AI入门课
第01章_AI快速入门
第一节 基础概念
1. AI简介
1) 什么是AI?
人工智能(AI)是通过计算机模拟人类智能(感知、推理、学习、决策),实现自主响应、问题解决的技术,核心是让机器“学会思考”,而非单纯执行指令。
2) AI的发展简史
- 起步:1956年达特茅斯会议,正式提出 “人工智能” 概念,AI 诞生。
- 低谷:1970-1990年代,两次 AI 寒冬,算力不足、算法受限、资金缩减,发展陷入停滞。
- 复苏:2006年深度学习提出,神经网络重新受到重视,AI 逐步回暖。
- 爆发:2020年后,大模型落地,ChatGPT、DeepSeek等产品问世,AI 全面落地应用。
3) AI的发展现状
- 发展现状:大模型主导,多场景落地;
- 核心突破:多模态融合(文本、图像、语音融合)、低成本部署;
- 现存问题:幻觉、算力依赖、伦理安全。
2. 相关名词
1) 大模型/Token
- 大模型:使用超大参数规模(百亿级以上)和海量数据训练的人工智能模型,能适配生成、问答、翻译等多种任务,常见产品如下:
| 模型名称 | 开发方 | 核心亮点 | 适用场景 |
|---|---|---|---|
| GPT-5.2 Ultra | OpenAI | 全能标杆,全模态,上下文 400K,推理 / 编程顶尖 | 复杂决策、科研、高要求代码 |
| Claude Opus 4.6 | Anthropic | 旗舰级,100 万 token 上下文(beta),长推理 / 编码极强,安全稳定 | 超长篇文档、深度研究、企业级编码 |
| Claude Sonnet 4.6 | Anthropic | 中杯旗舰,性能接近 Opus、价格更低,百万 token 上下文(beta),代码 / 长文优秀 | 日常专业场景、文档精读、代码开发、性价比首选 |
| Gemini 3.1 Pro | 原生多模态(视频 / 3D),超长上下文,性价比高 | 视频处理、工业设计、海量文档 | |
| Llama 4 | Meta | 开源标杆,隐私强,社区成熟 | 私有化部署、企业二次开发 |
| 通义千问 Qwen3.5 | 阿里云 | 中文顶尖,多模态广,开源商用友好 | 多语言、音视频、企业应用 |
| GLM-5 | 智谱 AI | 推理效率高,多语言生态成熟 | 通用对话、内容创作、垂直落地 |
| 文心一言 5.0 | 百度 | 中文语义精准,产业应用成熟 | 政务 / 教育 / 金融私有化、工具调用 |
| 豆包 5.0 | 字节跳动 | 日常体验佳,生态融合紧密 | 个人助理、内容创作、短视频辅助 |
| Kimi K2.5 | 月之暗面 | 长文本处理突出,国产长文能力领先 | 文献综述、长报告、大数据分析 |
- Token: 就是文字被切分后的最小单位,模型按它来计费、算长度、限字数等,1 个汉字 ≈ 1 token,1 个单词 ≈ 1~3 token。。
2) Agent/Claw/Swarm
- Agent:由提示词(Prompt)驱动,通过协同多种外部能力来完成复杂任务。
- Claw:AI工具调用组件,负责对接外部工具;
- Swarm:多Agent协同集群,分工完成复杂任务。
3) MCP/Skill/Plugin
- MCP:模型上下文协议(Model Context Protocol, MCP)是连接智能体与外部世界能力的关键桥梁,允许智能体调用外部工具。当智能体接收到无法仅凭自身知识完成的任务时(例如查询实时天气),它会调用 MCP 来执行这些任务。
- Skill:AI可调用的技能模块(如翻译、OCR);
- Plugin:插件,扩展AI功能(如联网、数据分析),可灵活增减。
4) FunctionCall/Embedding/RAG
- FunctionCall:函数调用,让AI调用外部工具(如查天气、算数据),实现“思考+执行”;
- Embedding:嵌入,将文本/图像转化为向量,用于语义匹配、检索;
- RAG:知识检索增强 (Retrieval-Augmented Generation, RAG) 能够使智能体查询外部知识库,并将检索到的最相关的信息作为生成答案的直接依据。在处理私有知识或垂直领域问答时,RAG 能显著提升智能体的回答准确率,减少幻觉问题。
5) 其它补充
- 多模态:AI同时处理文本、图像、语音、视频等多种信息(如图文生成、语音转文字);
- Fine-tuning(微调):基于预训练大模型,用少量特定数据训练,适配具体场景;
- Prompt Engineering(提示词工程):设计精准提示词,引导AI输出符合需求的结果;
- 对齐(Alignment):让AI输出贴合人类价值观、需求,避免有害内容;
- MoE(混合专家模型):将大模型拆分为多个“专家模块”,分工处理不同任务,提升效率、降低算力成本。
3. 模型交互
1) Prompt Engine
提示词(Prompt)就是你发给 AI 的指令、问题、要求,用来告诉 AI 你想让它做什么、怎么做,分为:
- 系统提示词:是预设的元指令,用于定义其角色、行为准则与能力边界,以确保其在交互中始终保持一致性、可控性和任务合规性。
- 用户提示词:用户原始提问输入,代表用户向 AI 提出的问题、命令或陈述。
提示词优化的核心原则是:明确需求、限定范围、提供示例、指定格式等,一般格式为:背景 + 指令 + 要求,优化技巧如下:
- 避免模糊表述(如“写好一点”→“写300字、正式语气、突出核心亮点”);
- 避免歧义,补充约束条件(如“不使用专业术语”“按时间顺序排列”);
- 使用少样本提示(给出1-2个示例)或思维链提示(引导AI分步推理);
- 避免提示词过于简略、未限定输出格式、未明确核心需求。
注意:
- DeepSeek给出的提示词样例:https://api-docs.deepseek.com/zh-cn/prompt-library/
2) Context Engine
上下文(Context) 是模型交互中的记忆载体,决定了 AI 能否理解多轮对话的历史脉络与背景信息,是保持对话连贯性的核心机制。
- 系统上下文: 包含角色定义、能力边界、全局规则等元指令,贯穿整个会话周期;
- 对话历史: 按时间顺序排列的用户与 AI 的消息记录,通常以
role + content形式存储; - 外部上下文: 通过 RAG、FunctionCall 等注入的实时知识或工具返回结果。
上下文管理的核心原则是:控制长度、保留关键、及时压缩,常用策略如下:
- 窗口截断: 超出模型最大上下文长度(如 4K / 32K / 128K)时,丢弃最早的历史消息;
- 摘要压缩: 对过早的历史对话进行语义摘要,替换为精简的总结文本,释放 Token 空间;
- 分层记忆: 将会话级短期记忆与用户级长期记忆分离,结合向量数据库实现跨会话记忆召回;
- 关键信息锚定: 将重要的系统指令、用户偏好固定放在上下文头部,避免被截断丢失。
注意:
- 上下文越长,推理延迟和 Token 消耗越高,需在连贯性与成本之间权衡。
3) Harness Engine
Harness(模型编排引擎) 是连接应用层与底层模型的中间层,负责对多模型、多厂商的 API 进行统一封装、调度与治理,让上层业务代码以一致的方式调用不同的 AI 能力。
- 统一接口: 屏蔽底层模型差异(OpenAI、DeepSeek、通义千问等),提供标准化的
chat / stream / embed调用方法; - 模型路由: 根据任务类型(简单问答、复杂推理、代码生成)或模型状态(可用性、负载)自动选择最优模型;
- 流控与降级: 设置 QPS 限流、超时熔断,当主模型异常时自动切换至备用模型(Fallback),保障服务稳定性;
- 重试与容错: 对网络抖动、API 限流等异常进行指数退避重试,避免单点故障导致业务中断;
- 观测与审计: 记录每次调用的输入输出、延迟、Token 消耗,便于成本分析与问题追溯。
工程化配置通常包含:
1# 示例:多模型路由与降级配置2ai3 harness4 providers5 primary6 modelqwen-max7 api-key$PRIMARY_KEY8 timeout30s9 fallback10 modeldeepseek-chat11 api-key$FALLBACK_KEY12 timeout60s13 rate-limit100 # 每秒最大请求数14 retry15 max-attempts316 backoff2s注意:
- Harness 层不处理业务逻辑,只负责模型调用的可靠性与一致性,应与业务层解耦。
4. 向量化
第二节 理论基础
1. 理论基础01
1) 什么是深度学习?
深度学习是AI核心理论,基于神经网络(模拟人脑结构),通过多层网络实现特征提取、模式识别,是大模型的基础;
2) 深度学习与机器学习的区别?
数据依赖、特征提取方式等。
3) 神经网络结构
- CNN(卷积神经网络):适用于图像识别、提取空间特征;
- RNN/LSTM(循环神经网络):适用于序列数据(文本、语音),处理上下文关联;
- Transformer:大模型核心结构(注意力机制),解决长文本依赖问题,提升并行计算效率。
4) 学习方式有哪些?
- 监督学习:有标签数据训练,如分类、回归;
- 无监督学习:无标签数据,自主挖掘规律,如聚类;
- 强化学习:通过“试错”学习,如AI下棋,核心是奖励机制;
5) 什么是过拟合和欠拟合?
- 过拟合:模型过度贴合训练数据,泛化能力差,通过正则化、数据增强解决;
- 欠拟合:模型未充分学习数据特征,预测不准),通过增加训练数据、加深模型层数解决。
6) 什么是注意力机制?
注意力机制是 Transformer 核心,让模型关注输入数据的关键部分(如文本中的重点词汇),提升处理效率和准确性;
第三节 大模型
1. 大模型部署
1) 基于Ollma部署大模型
Ollama 是一款极简的本地大模型运行工具,只需简单命令即可在电脑上一键部署、离线运行各类开源 AI 大模型。
- 官网地址:https://ollama.com
xxxxxxxxxx361# 安装Ollma2# 先从Ollma官网(https://ollama.com/)下载3OllamaSetup.exe /DIR=D:\study_setup\Ollama # 指定目录安装(安装后进入软件修改模型位置)4
5# 查看 Ollama 版本6ollama --version7
8# 查看ollama进程是否启动9tasklist | findstr ollama10
11# 启动ollama12ollama start13ollama serve # 重启14
15# 查看模型列表16ollama list # 已安装的的17ollama ps # 正在运行的18
19# 拉取(下载)模型20# 模型仓库:https://ollama.com/library21ollama pull qwen:7b22ollama pull deepseek-r1:14b23
24# 直接运行模型25ollama run qwen:7b # 启动 Qwen 7B(4-bit量化)26
27# 停止运行中的模型28ollama stop llama329
30# 删除不需要的模型31ollama rm llama332
33# 访问模型34curl http://localhost:11434/api/chat \35 -d '{"model":"qwen:7b","messages":[{"role":"user","content":"你好"}]}'36
2) 基于vLLM部署大模型
vLLM(Virtual Large Language Model)是伯克利大学开源的工业级高性能大语言模型(LLM)推理与服务引擎,以PagedAttention分页注意力技术为核心,极致优化显存与并发,是当前生产环境部署大模型的主流首选。
x1# 1. 安装基础依赖2yum install -y git gcc gcc-c++ make3
4# 2. 安装 Conda(必须,用来管理 Python 3.11)5curl -fsSL https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -o miniconda.sh6bash miniconda.sh -b -p ~/miniconda7source ~/miniconda/etc/profile.d/conda.sh8
9# 3. 创建 Python 3.11 环境(vLLM 唯一支持)10conda create -n vllm python=3.11 -y11conda activate vllm12
13# 4. 安装 CUDA 12.1 适配的 PyTorch + vLLM14pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu12115pip install vllm==0.18.0 transformers==4.48.0 accelerate -U16
17# 5. 国内加速(解决下载慢)18export HF_ENDPOINT=https://hf-mirror.com19
20# 6. 启动 千问 Qwen2.5-7B 大模型 API21python -m vllm.entrypoints.openai.api_server \22--model Qwen/Qwen2.5-7B-Instruct \23--trust-remote-code \24--dtype auto \25--gpu-memory-utilization 0.9 \26--max-model-len 4096 \27--host 0.0.0.0 \28--port 800029
30# 7. 验证是否启动成功31curl http://localhost:8000/v1/models32
33# 8. Python 调用代码34from openai import OpenAI35client = OpenAI(base_url="http://127.0.0.1:8000/v1", api_key="dummy")36
37resp = client.chat.completions.create(38 model="Qwen2.5-7B-Instruct",39 messages=[{"role":"user","content":"你好"}]40)41print(resp.choices[0].message.content)
2. 大模型微调
3. 大模型训练
第02章_AI工具使用
第一节 Claude Code
1. 安装部署
1) 什么是Claude Code?
Claude Code 是一款智能编码工具,能够读取你的代码库、编辑文件、执行命令,并与你的开发工具集成。
官方文档:https://code.claude.com/docs/en/overview。
笔记参考:https://cloud.fynote.com/share/d/HnIGGVKAMH
2) 命令行安装
xxxxxxxxxx521# 1. 连接VPN美国节点2[略]3
4# 2.下载和执行安装脚本5curl -fsSL https://claude.ai/install.sh | bash6
7# 3. 配置环境变量8PATH C:\Users\Administrator\.local\bin9CLAUDE_CODE_GIT_BASH_PATH D:\Application\Git\bin # 优先配置bash.exe路径到PATH,不配置这个10
11# 4. 启动和登录12claude13/login14
15# 5. 使用国产大模型16# step1:修改 C:\Users\%USERNAME%\.claude.json 17{18 "hasCompletedOnboarding": true19}20
21# step2:修改 C:\Users\%USERNAME%\.claude\settings.json22{23 "env": {24 "ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",25 "ANTHROPIC_API_KEY": "从智谱官网获取",26 "API_TIMEOUT_MS": "3000000",27 "CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1",28 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",29 "ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.6v",30 "ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5"31 },32 "autoUpdatesChannel": "latest"33}34
35# 也可通过环境变量方式配置36# 智谱37ANTHROPIC_API_KEY:从智谱官网获取38ANTHROPIC_BASE_URL:https://open.bigmodel.cn/api/anthropic39ANTHROPIC_MODEL:GLM-4.740# 阿里百炼41ANTHROPIC_API_KEY:从阿里百炼官网获取42ANTHROPIC_BASE_URL:https://coding.dashscope.aliyuncs.com/apps/anthropic43ANTHROPIC_MODEL:qwen3.5-plus44# DeepSeek45$env:ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"46$env:ANTHROPIC_AUTH_TOKEN="<你的 DeepSeek API Key>"47$env:ANTHROPIC_MODEL="deepseek-v4-pro[1m]"48$env:ANTHROPIC_DEFAULT_OPUS_MODEL="deepseek-v4-pro[1m]"49$env:ANTHROPIC_DEFAULT_SONNET_MODEL="deepseek-v4-pro[1m]"50$env:ANTHROPIC_DEFAULT_HAIKU_MODEL="deepseek-v4-flash"51$env:CLAUDE_CODE_SUBAGENT_MODEL="deepseek-v4-flash"52$env:CLAUDE_CODE_EFFORT_LEVEL="max"
3) 插件安装
在各大插件市场搜索安装即可,推荐一个 CC GUI 插件如下,可手工加载C:\Users\用户名\.claude\settings.json配置。
2. 基本使用
1) 基本命令
xxxxxxxxxx201# 启动 Claude Code2claude # 正常启动3claude -c # 启动并加载最近会话4
5# 核心模式切换(日常高频)6shift+tab # 切换交互模式(默认/规划/代理/自动)7 - 默认模式:手动确认每个操作(最安全)8 - 规划模式:仅生成计划,需审批执行9 - 代理模式:自动接受文件编辑/创建10 - 自动模式:无权限校验,谨慎使用11
12# 输入快捷键13shift+回车 # 多行输入(换行不发送)14ctrl+g # 打开内置编辑器输入长文本15直接拖入/粘贴图片 # 快速上传图片(无需命令)16
17# 直接执行终端命令(高频)18!ls # 执行 ls19!npm install # 执行任意终端命令20!python test.py # 运行代码
2) 会话管理
xxxxxxxxxx111# 会话上下文2ctrl+o # 查看当前会话上下文3/compact # 压缩上下文(减少token占用)4/compact 总结代码修改 # 带提示压缩5/clear # 清空会话上下文6esc esc # 快速回滚会话7
8# 会话任务9/resume # 重载/恢复最近会话10/tasks # 查看当前会话所有任务11ctrl+b # 将当前任务放入后台运行
3) 文件 / 项目操作
xxxxxxxxxx151# 文件查看2/tree # 生成项目目录树3/files # 列出项目文件4/file 路径 # 查看文件完整内容5/diff # 查看文件修改对比6
7# 文件编辑8/edit 路径 # 编辑指定文件9/undo # 撤销上一次文件修改10/save 路径 # 保存内容到文件11
12# 代码工具13/format # 自动格式化代码14/lint # 代码语法检查15/fix # 自动修复代码错误
3) 高级扩展
xxxxxxxxxx181# 项目配置文件2/init # 初始化/管理 CLAUDE.MD3/memory # 打开 CLAUDE.MD(项目级+用户级)4
5# MCP 服务管理6/mcp # 查看所有MCP服务7mcp add --transport http figma https://mcp.figma.com/mcp8mcp remove figma # 移除MCP服务(修正原命令错误)9
10# 技能管理(~/.claude/skills/技能名称/SKILLS.MD)11/skills # 查看所有技能12/技能名 提示词 # 使用指定技能13
14# 子代理 & 钩子 & 插件15/hooks # 管理钩子函数16/agent # 管理 SubAgent17/plugin # 管理插件(插件是对skills、subagent、hooks、mcp等的打包)18
注意:
skills会继承主Agent上下文,而SubAgent不会影响当前上下文,适合关联小,影响大的任务。
4) Skill示例
下面是一个文件整理技能,在技能目录~/.claude/skills/技能名称/SKILLS.MD创建SKILLS.MD文件,写入下面内容即可。
xxxxxxxxxx161---2name: file_organizer3description: 自动整理指定目录下的文件,按扩展名分类到不同文件夹。4requires: [“bash”]5---6
7# 文件整理技能8
9当用户要求整理某个目录时,请执行以下操作:10
111. 使用 `bash` 工具,在用户指定的目标目录中,创建 `Images`、`Documents`、`Archives` 子文件夹。122. 将所有的 `.jpg`、`.png` 文件移动到 `Images` 文件夹。133. 将所有的 `.pdf`、`.docx` 文件移动到 `Documents` 文件夹。144. 将所有的 `.zip`、`.tar.gz` 文件移动到 `Archives` 文件夹。155. 操作完成后,向用户报告整理结果。16
3. 其它AI编程工具
1) Cursor
Cursor 是由 Anysphere 公司开发、基于 VS Code 深度定制的 AI 原生代码编辑器,核心定位是 “AI 结对编程伙伴”。
它集成了 GPT-4、Claude、Gemini 等大模型,支持自然语言编程、项目级代码理解、跨文件智能重构、一键 Debug 与优化,并具备 Agent 自主执行、Yolo 快速编辑等高级模式,能直接通过对话生成、修改、解读与维护代码。
2) Trce
Trae(读作 /treɪ/) IDE是由字节跳动推出的一款 AI 原生集成开发环境的IDE,集成了智能问答、实时代码建议、代码片段生成及基于智能体的自动编程能力,并针对中文开发者进行了深度优化,例如全界面中文支持和语义理解优化。
官网地址:https://www.trae.cn/
笔记参考:https://cloud.fynote.com/share/d/iISJVVge
3) Open Code
4) Codex
5) Qorder
xxxxxxxxxx441# Windows安装2npm install -g @qoder-ai/qodercli3
4# 启动与基础信息5qodercli # 启动交互式TUI模式6qodercli --version # 查看版本{insert\_element\_0\_}7qodercli update # 升级CLI{insert\_element\_1\_}8qodercli -w /path/to/dir # 指定工作目录启动{insert\_element\_2\_}9qodercli -p "提示内容" # 单轮命令模式执行提示10
11# 登录与账户12/login # 登录账号{insert\_element\_3\_}13/logout # 退出登录14/usage # 查看账户、Credits消耗15
16# 帮助与状态17/help # 显示帮助{insert\_element\_4\_}18/status # 查看CLI状态(版本、模型、API等)19/config # 管理CLI配置{insert\_element\_5\_}20/release-notes # 查看更新日志21
22# 项目与记忆23/init # 初始化/更新AGENTS.md{insert\_element\_6\_}24/memory # 编辑AGENTS.md{insert\_element\_7\_}25
26# 代码与任务27/review # 代码评审本地改动{insert\_element\_8\_}28/quest # 基于Spec委派任务{insert\_element\_9\_}29/code-inspect # 代码检查(示例)30
31# 会话与上下文32/clear # 清空当前会话上下文{insert\_element\_10\_}33/compact # 压缩/总结上下文{insert\_element\_11\_}34/resume # 查看/恢复历史会话{insert\_element\_12\_}35/export 文件名 # 导出当前会话{insert\_element\_13\_}36
37# 工具与后台38/agents # 子Agent管理39/bashes # 查看后台Bash任务40/vim # 外部编辑器编辑输入41
42# 其他43/feedback 内容 # 提交反馈{insert\_element\_14\_}44/quit # 退出TUI
第二节 OpenClaw
1. 安装部署
1) 什么是OpenClaw?
OpenClaw 是一款开源 AI 智能体,可部署在本地电脑,通过 Telegram、微信等聊天软件操控,让 AI 不仅能对话建议,更能主动执行代码、管理文件、操作浏览器等实际任务,成为真正"能动手"的私人数字助理。
官网地址:https://openclaw.ai/
官方文档:https://docs.openclaw.ai/zh-CN
笔记参考:https://cloud.fynote.com/share/d/ZAHaTUrAC
2) Windows安装
xxxxxxxxxx281# 参考:https://docs.bigmodel.cn/cn/guide/develop/openclaw2
3# 1. 解锁 PowerShell 执行策略(必做)4# 按 Win+S,搜索 PowerShell,右键选择「以管理员身份运行」,UAC 点「是」5Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser6
7# 2. 执行官方一键安装8# 关闭管理员 PowerShell,打开普通权限 PowerShell 执行9# 脚本会自动安装 Node.js 22、配置环境变量、安装 OpenClaw 并完成初始化10iwr -useb https://openclaw.ai/install.ps1 | iex # 官方11iwr -useb https://open-claw.org.cn/install-cn.ps1 | iex # 国内加速12
13# 3. 新手引导14# 运行上述安装命令后,配置过程将自动开始。如果没有开始,您可以运行以下命令开始配置15openclaw onboard --install-daemon16
17# 4. 验证安装18openclaw --version # 输出版本号19openclaw doctor # 检查配置问题20openclaw status # 查看状态21
22# 5. 修改配置(如配置模型key等)23openclaw config24
25# 6. 启动服务(普通权限的 PowerShell)26openclaw gateway run # 启动 Gateway 服务27openclaw dashboard # 启动 WebUI 仪表盘28
3) Linux安装
xxxxxxxxxx71# 一键安装2curl -fsSL https://openclaw.ai/install.sh | bash3
4# 验证与初始化5openclaw --version6openclaw onboard --install-daemon7
2. 基本使用
1) 常用命令
xxxxxxxxxx421# 基础与配置2openclaw onboard # 初始化向导3openclaw configure # 交互式配置4openclaw config set <key> <val> # 设置配置项5openclaw config get <key> # 获取配置6openclaw config unset <key> # 删除配置7openclaw doctor # 健康检查8openclaw doctor --fix # 自动修复9openclaw status # 系统状态10openclaw update # 更新OpenClaw11openclaw logs --follow # 实时日志12
13# Gateway服务14openclaw gateway start # 后台启动15openclaw gateway stop # 停止16openclaw gateway restart # 重启17openclaw gateway status # 状态18openclaw gateway run --dev # 前台调试19openclaw gateway install # 安装系统服务(开机自启)20
21# 模型管理22openclaw models list # 列出模型23openclaw models set <model> # 设置默认模型24openclaw models status # 模型状态25
26# 渠道管理27openclaw channels list # 渠道列表28openclaw channels status # 渠道状态29openclaw channels login <name> # 登录渠道30
31# Skill管理32openclaw skills list # 已装技能33openclaw skills check # 检查技能34openclaw skills refresh # 刷新技能35
36# 会话(TUI内)37/new # 新会话38/status # 会话状态39/think high|medium|off # 思考深度40/elevated full|ask # 提权模式41/export-session <path> # 导出会话42/kill <agent-id> # 终止子代理
2) 修改大模型
xxxxxxxxxx321# 命令行切换(推荐)2openclaw models set moonshot/kimi-latest # 设置默认3openclaw models set ollama/qwen2.5:7b # 本地Ollama4
5# 配置文件(~/.openclaw/openclaw.json)6{7 "agents": {8 "defaults": {9 "model": {10 "primary": "moonshot/kimi-latest",11 "fallbacks": ["doubao/seed-2.0-lite", "ollama/qwen2.5:7b"]12 }13 }14 },15 "models": {16 "providers": {17 "moonshot": {18 "baseUrl": "https://api.moonshot.cn/v1",19 "apiKey": "sk-xxx",20 "models": [{"id": "kimi-latest", "name": "Kimi"}]21 },22 "ollama": {23 "baseUrl": "http://localhost:11434/v1",24 "apiKey": "ollama",25 "models": [{"id": "qwen2.5:7b", "name": "Qwen2.5"}]26 }27 }28 }29}30
31# 生效32openclaw gateway restart
3) 配置渠道
xxxxxxxxxx341# 飞书2openclaw channels login feishu3# 输入 appId、appSecret、encryptKey4
5# 企业微信6openclaw channels login wecom7# 输入 corpId、agentId、secret8
9# 钉钉10openclaw channels login dingtalk11# 输入 clientId、clientSecret12
13# QQ14openclaw channels login qq15# 输入 appId、token16
17# Telegram18openclaw channels login telegram19# 输入 botToken20
21# 配置文件示例(~/.openclaw/openclaw.json)22{23 "channels": {24 "feishu": {25 "enabled": true,26 "appId": "xxx",27 "appSecret": "xxx",28 "encryptKey": "xxx"29 }30 }31}32
33# 生效34openclaw gateway restart
4) 添加SKILL
xxxxxxxxxx261# ClawHub安装(推荐)2npx clawhub@latest install tavily-search # 联网搜索3npx clawhub@latest install summarize # 文本总结4npx clawhub@latest install gog # Google办公5npx clawhub@latest install obsidian # Obsidian笔记6npx clawhub@latest install system-utils # 系统工具7
8# 批量/更新9clawhub update --all # 更新所有10clawhub sync --all # 同步11
12# 手动安装13mkdir -p ~/.openclaw/workspace/skills/hello14cat > ~/.openclaw/workspace/skills/hello/SKILL.md << 'EOF'15---16name: hello17description: 打招呼18---19# Hello Skill20用户说你好时回复:Hello from OpenClaw!21EOF22
23# 生效24openclaw skills refresh25# 或26openclaw gateway restart
第三节 DALL.E3
第四节 Midjourney
第五节 Dify
Dify:面向企业级用户的开源 AI 平台,支持主流大模型(如 GPT‑4、Claude)、灵活创建聊天机器人、文本应用和复杂工作流,允许私有化部署、更好地保障数据隐私和合规性。
Coze:针对个人或小型团队构建对话式 AI 应用的低/无代码平台,支持国内模型、一键页面布局、丰富插件嵌入、云端托管(依赖火山引擎),适合快速验证智能体/聊天机器人产品。
mauns:全自主、多代理驱动的智能体平台,擅长接收高层指令后自动拆解任务、调用多模型及 API(浏览网页、写代码、生成报告/部署网站等),适合跨域、多步骤、复杂任务的专业用户或团队使用。
第六节 milvus
1. 安装部署
1) 什么是milvus?
Milvus 是一个由 Zilliz 开发的高性能向量数据库,专为存储、索引和检索高维向量数据而设计,它能够处理图像、音频、视频、自然语言等嵌入表示(embeddings),支持海量向量(万亿级)毫秒级相似搜索,现已成为世界领先的开源向量数据库项目之一。
2) 安装milvus
- Milvus Standalone: Docker 中运行,所有组件(Milvus + etcd)打包在一台主机内,支持10亿向量存储,适合中小型生产环境。
xxxxxxxxxx151#创建目录并进入【创建目录,然后一会docker-compose.yml就会下载在这里】2mkdir -p /root/dockerrepos/milvus && cd /root/dockerrepos/milvus3
4#下载compose 配置,或者直接将资料中 docker-compose.yml上传至目录下5wget https://github.com/milvus-io/milvus/releases/download/v2.5.14/milvus-standalone-docker-compose.yml -O docker-compose.yml6
7# 启动 Milvus8docker compose up -d9
10# 停止Milvus11docker compose down12
13# 访问 Web UI14http://119.29.250.81:9091/webui/ 15
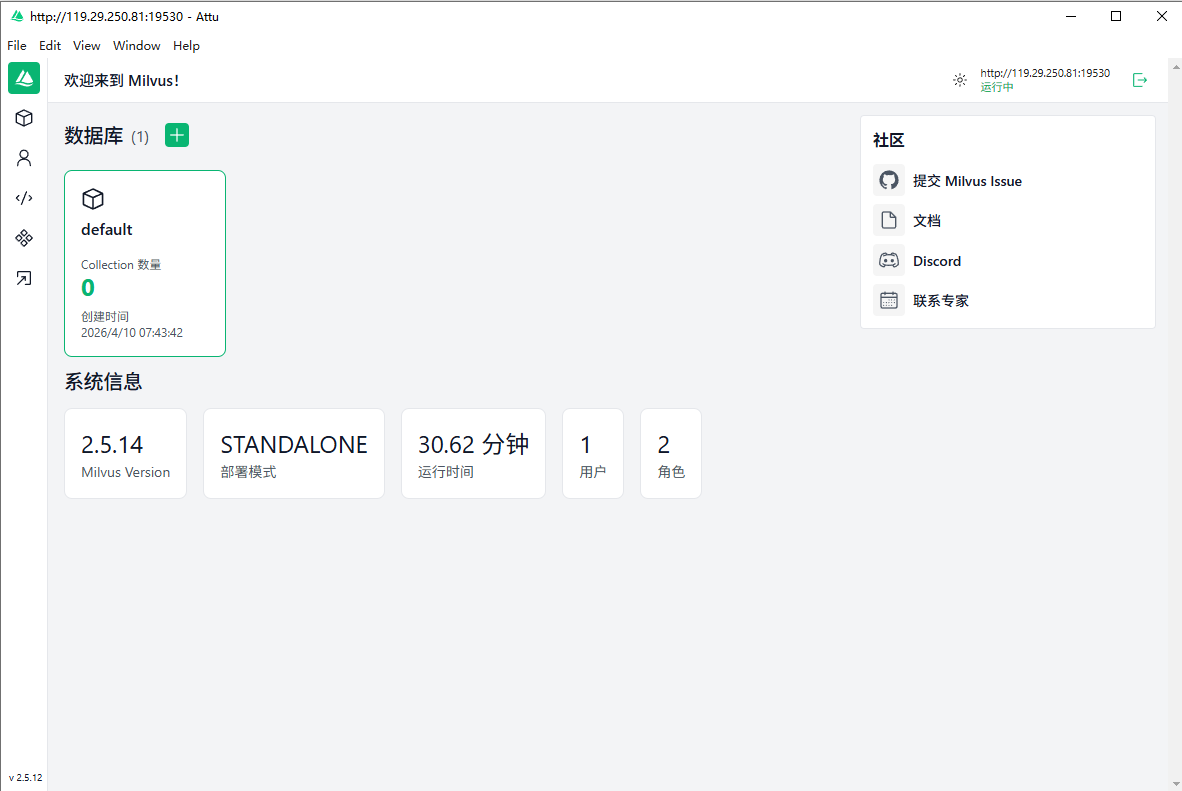
- Attu:一款专为 Milvus 向量数据库打造的开源数据库管理工具,提供了便捷的图形化界面,简化了操作与管理流程。
2. 基本使用
1) 导入依赖
xxxxxxxxxx101<dependency>2 <groupId>org.slf4j</groupId>3 <artifactId>slf4j-api</artifactId>4 <version>2.0.9</version>5</dependency>6<dependency>7 <groupId>io.milvus</groupId>8 <artifactId>milvus-sdk-java</artifactId>9 <version>2.6.0</version>10</dependency>
2) 创建Collection和Schema
Collection:可以比作 MySql 中的表,是 Milvus 中最大的数据单元,有行和列的概念,每列代表一个字段,每行代表一个实体。
Schema:定义了 Collections 的数据结构,必须包含的 3 类字段:
- 主键字段:必须有,且只能 1 个,唯一标识一条数据,类型:int /varchar。
- 向量字段:必须有,最多 4 个,存文章、图片、音频转成的向量,用来做相似度检索,必须指定向量维度(dim)。
- 标量字段:可选,任意多个,存文本、数字、布尔、JSON等普通数据,用来过滤或筛选(比如:分类、时间、作者、状态)。
xxxxxxxxxx861package com.allyun.controller;2
3import io.milvus.v2.client.ConnectConfig;4import io.milvus.v2.client.MilvusClientV2;5import io.milvus.v2.common.DataType;6import io.milvus.v2.common.IndexParam;7import io.milvus.v2.service.collection.request.AddFieldReq;8import io.milvus.v2.service.collection.request.CreateCollectionReq;9import java.util.ArrayList;10import java.util.List;11
12public class TestMilvusCollection {13 static String MILVUS_URI = "http://192.168.1.3:19530";14 static String TOKEN = "root:Milvus";15
16
17 public static void main(String[] args) {18
19 //1.连接到Milvus20 ConnectConfig connectConfig = ConnectConfig.builder()21 .uri(MILVUS_URI)22 .token(TOKEN)23 .build();24 MilvusClientV2 client = new MilvusClientV2(connectConfig);25
26
27 //2.创建 Collection28 String collectionName = "testCollection";29
30 createCollection(client,collectionName);31
32 //3.列出collection33 List<String> collectionNames = client.listCollections().getCollectionNames();34 System.out.println("collectionNames:"+collectionNames);35
36 }37
38
39 private static void createCollection(MilvusClientV2 client, String collectionName) {40 //1.创建schema41 CreateCollectionReq.CollectionSchema schema = MilvusClientV2.CreateSchema()42 .addField(43 AddFieldReq.builder()44 .fieldName("id")45 .dataType(DataType.Int64)46 .isPrimaryKey(true)47 .autoID(false)48 .build()49 )50 .addField(51 AddFieldReq.builder()52 .fieldName("vector")53 .dataType(DataType.FloatVector)54 .dimension(5)55 .build()56 )57 .addField(58 AddFieldReq.builder()59 .fieldName("color")60 .dataType(DataType.VarChar)61 .maxLength(512)62 .build()63 );64
65 //2. 构建索引66 ArrayList<IndexParam> indexParams = new ArrayList<IndexParam>();67
68 IndexParam vector = IndexParam.builder()69 .fieldName("vector")70 .indexType(IndexParam.IndexType.IVF_FLAT)71 .metricType(IndexParam.MetricType.COSINE)/72 .build();73 indexParams.add(vector);74
75 //创建collection76 client.createCollection(77 CreateCollectionReq.builder()78 .collectionName(collectionName)79 .collectionSchema(schema)80 .indexParams(indexParams)81 .build()82 );83
84 }85}86
3) 数据增删查
xxxxxxxxxx1441import com.google.gson.Gson;2import com.google.gson.JsonObject;3import io.milvus.v2.client.ConnectConfig;4import io.milvus.v2.client.MilvusClientV2;5import io.milvus.v2.common.DataType;6import io.milvus.v2.common.IndexParam;7import io.milvus.v2.service.collection.request.AddFieldReq;8import io.milvus.v2.service.collection.request.CreateCollectionReq;9import io.milvus.v2.service.utility.request.FlushReq;10import io.milvus.v2.service.vector.request.DeleteReq;11import io.milvus.v2.service.vector.request.GetReq;12import io.milvus.v2.service.vector.request.InsertReq;13import io.milvus.v2.service.vector.response.DeleteResp;14import io.milvus.v2.service.vector.response.GetResp;15import io.milvus.v2.service.vector.response.InsertResp;16import io.milvus.v2.service.vector.response.QueryResp;17
18import java.util.ArrayList;19import java.util.Arrays;20import java.util.List;21
22public class TestMilvusCollection4 {23 static String MILVUS_URI = "http://192.168.0.108:19530";24 static String TOKEN = "root:Milvus";25
26
27 public static void main(String[] args) {28
29 // 1.连接到Milvus30 ConnectConfig connectConfig = ConnectConfig.builder()31 .uri(MILVUS_URI)32 .token(TOKEN)33 .build();34
35 MilvusClientV2 client = new MilvusClientV2(connectConfig);36
37
38 // 2.向collection插入数据39 String collectionName = "testCollection";40 inserDataIntoCollection(client,collectionName);41 42 // 3.查询数据43 GetResp getResp = client.get(44 GetReq.builder()45 .collectionName(collectionName)46 .ids(List.of(1, 2, 3))47 .outputFields(List.of("id", "color"))48 .build()49 );50 for (QueryResp.QueryResult getResult : getResp.getResults) {51 System.out.println("数据:"+getResult.toString());52 }53 54 // 4.删除数据55 DeleteResp delete = client.delete(DeleteReq.builder().collectionName(collectionName).ids(List.of(0, 1)).build());56 System.out.println("delete:"+delete);57 }58
59 private static void inserDataIntoCollection(MilvusClientV2 client, String collectionName) {60 //准备数据61 Gson gson = new Gson();62 List<JsonObject> data = Arrays.asList(63 gson.fromJson("{\"id\": 0, \"vector\": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], \"color\": \"pink_1111\"}", JsonObject.class),64 gson.fromJson("{\"id\": 1, \"vector\": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], \"color\": \"red_7025\"}", JsonObject.class),65 gson.fromJson("{\"id\": 2, \"vector\": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], \"color\": \"orange_6781\"}", JsonObject.class),66 gson.fromJson("{\"id\": 3, \"vector\": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], \"color\": \"pink_9298\"}", JsonObject.class),67 gson.fromJson("{\"id\": 4, \"vector\": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], \"color\": \"red_4794\"}", JsonObject.class),68 gson.fromJson("{\"id\": 5, \"vector\": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], \"color\": \"yellow_4222\"}", JsonObject.class),69 gson.fromJson("{\"id\": 6, \"vector\": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], \"color\": \"red_9392\"}", JsonObject.class),70 gson.fromJson("{\"id\": 7, \"vector\": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], \"color\": \"grey_8510\"}", JsonObject.class),71 gson.fromJson("{\"id\": 8, \"vector\": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], \"color\": \"white_9381\"}", JsonObject.class),72 gson.fromJson("{\"id\": 9, \"vector\": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], \"color\": \"purple_4976\"}", JsonObject.class)73 );74
75 //插入数据76 InsertResp insert = client.insert(77 InsertReq.builder()78 .collectionName(collectionName)79 .data(data)80 .build()81 );82
83 //刷新数据,否则查询不到数据84 client.flush(85 FlushReq.builder()86 .collectionNames(List.of(collectionName))87 .build()88 );89
90 System.out.println("插入数据成功");91
92
93
94 }95
96 private static void createCollection(MilvusClientV2 client, String collectionName) {97 //1.创建schema98 CreateCollectionReq.CollectionSchema schema = MilvusClientV2.CreateSchema()99 .addField(100 AddFieldReq.builder()101 .fieldName("id")102 .dataType(DataType.Int64)103 .isPrimaryKey(true)104 .autoID(false)105 .build()106 )107 .addField(108 AddFieldReq.builder()109 .fieldName("vector")110 .dataType(DataType.FloatVector)111 .dimension(5)112 .build()113 )114 .addField(115 AddFieldReq.builder()116 .fieldName("color")117 .dataType(DataType.VarChar)118 .maxLength(512)119 .build()120 );121
122 //构建索引123 ArrayList<IndexParam> indexParams = new ArrayList<IndexParam>();124
125 IndexParam vector = IndexParam.builder()126 .fieldName("vector")127 .indexType(IndexParam.IndexType.IVF_FLAT)128 .metricType(IndexParam.MetricType.COSINE)129 .build();130 indexParams.add(vector);131
132 //创建collection133 client.createCollection(134 CreateCollectionReq.builder()135 .collectionName(collectionName)136 .collectionSchema(schema)137 .indexParams(indexParams)138 .build()139 );140
141 }142}143
144
3. 其它向量数据库
1) Redis Stack
第03章_AI应用开发(Java)
第一节 SpringAI
1. SpringAI简介
1) 什么是Spring AI?
SpringAI是一个AI工程领域的应用程序框架,对OpenAI、DeepSeek等主流 AI 大模型提供了支持。
2. 接入DeepSeek
1) 引入依赖
xxxxxxxxxx551<!-- 继承SpringBoot父工程:spring-boot-starter-parent -->2<parent>3 <groupId>org.springframework.boot</groupId>4 <artifactId>spring-boot-starter-parent</artifactId>5 <version>3.4.3</version>6</parent>7
8<!-- 使用JDK17+版本编译 -->9<properties>10 <maven.compiler.source>17</maven.compiler.source>11 <maven.compiler.target>17</maven.compiler.target>12 <spring-ai.version>1.0.0-M5</spring-ai.version>13 <spring-ai-alibaba.version>1.0.0-M6.1</spring-ai-alibaba.version>14</properties>15
16<!-- 依赖 -->17<dependencies>18 <!-- SpringBoot Web模块 -->19 <dependency>20 <groupId>org.springframework.boot</groupId>21 <artifactId>spring-boot-starter-web</artifactId>22 </dependency>23
24 <!-- Spring AI 集成 OpenAi/DeepSeek -->25 <dependency>26 <groupId>group.springframework.ai</groupId>27 <artifactId>spring-ai-openai-spring-boot-starter</artifactId>28 </dependency>29 30 <!-- SpringBoot 测试模块 -->31 <dependency>32 <groupId>org.springframework.boot</groupId>33 <artifactId>spring-boot-test</artifactId>34 </dependency>35
36 <!-- lombok -->37 <dependency>38 <groupId>org.projectlombok</groupId>39 <artifactId>lombok</artifactId>40 </dependency>41</dependencies>42
43<!-- 依赖管理 -->44<dependencyManagement>45 <dependencies>46 <!-- Spring AI 依赖管理 -->47 <dependency>48 <groupId>group.springframework.ai</groupId>49 <artifactId>spring-ai-bom</artifactId>50 <version>${spring-ai.version}</version>51 <type>pom</type>52 <scope>import</scope>53 </dependency>54 </dependencies>55</dependencyManagement>
2) 创建配置文件
xxxxxxxxxx181# application.yml2
3# 服务器配置4server5 port80806
7# Spring配置8spring9 application10 nameSpringAI-demo11 ai12 # DeepSeek配置13 openai14 base-urlhttps//api.deepseek.com15 api-keysk-04b52cab40d7443486c24a7a09691ec916 chat17 options18 modeldeepseek-chat
3) 编写Controller
xxxxxxxxxx521/**2 * Sping AI 接入 OpenAI/DeepSeek 模型3 */4("/deepseek")6public class DeepSeekClientModelController {7
8 /**9 * OpenAi/DeepSeek 对话模型客户端10 */11 12 private OpenAiChatModel openAiChatModel;13
14 /**15 * 接入DeepSeek对话模型 deepseek-chat16 *17 * @param msg18 * @return19 */20 ("/chat")21 public String chat((defaultValue = "你是谁?") String msg) {22 // 构建提示词23 Prompt prompt = new Prompt(msg, OpenAiChatOptions.builder()24 .withModel("deepseek-chat")25 .withTemperature(0.8F)26 .build());27
28 // 对话29 ChatResponse chatResponse = openAiChatModel.call(prompt);30 return chatResponse.getResult().getOutput().getContent();31 }32
33 /**34 * 接入DeepSeek流式对话模型 deepseek-chat35 *36 * @param msg37 * @return38 */39 (value = "/stream", produces = "text/html;charset=UTF-8")40 public Flux<String> stream((defaultValue = "你是谁?") String msg) {41 // 构建提示词42 Prompt prompt = new Prompt(msg, OpenAiChatOptions.builder()43 .withModel("deepseek-chat")44 .withTemperature(0.8F)45 .build());46
47 // 对话48 Flux<ChatResponse> chatResponseFlux = openAiChatModel.stream(prompt);49 return chatResponseFlux.map((r) -> r.getResult() != null && r.getResult().getOutput() != null && r.getResult().getOutput().getContent() != null ? r.getResult().getOutput().getContent() : "").filter(StringUtils::hasText);50 }51
52}
4) 创建启动类
xxxxxxxxxx91/**2 * 启动类3 */4(exclude = ContextFunctionCatalogAutoConfiguration.class)5public class DeepSeekApplication {6 public static void main(String[] args) {7 SpringApplication.run(DeepSeekApplication.class, args);8 }9}
5) 测试
3. 接入阿里百炼平台
1) 引入依赖
xxxxxxxxxx61<!-- Spring AI 集成 千问模型 -->2<dependency>3 <groupId>com.alibaba.cloud.ai</groupId>4 <artifactId>spring-ai-alibaba-starter</artifactId>5 <version>${spring-ai-alibaba.version}</version>6</dependency>
2) 修改配置
xxxxxxxxxx151spring2 ai3 # 阿里百炼4 dashscope5 api-keysk-441a047d9be542778a471a00ebbf9df86 chat7 options8 modelqwen-max9 image10 options11 modelwanx2.1-t2i-plus12 audio13 synthesis14 options15 modelcosyvoice-v1
3) 编写Controller
xxxxxxxxxx1221/**2 * Sping AI 接入 阿里百炼 模型3 */4("spring.ai.dashscope.api-key")6("/dashscope")7public class DashScopeClientModelController {8
9 /**10 * 阿里百炼 对话模型客户端11 */12 13 private DashScopeChatModel dashScopeChatModel;14
15 /**16 * 阿里百炼 图片模型客户端17 */18 19 private DashScopeImageModel dashScopeImageModel;20
21 /**22 * 阿里百炼 语音模型客户端23 */24 25 private DashScopeSpeechSynthesisModel dashScopeSpeechSynthesisModel;26
27 /**28 * 接入阿里百炼对话模型 qwen-max29 *30 * @param msg31 * @return32 */33 ("/chat")34 public String chat((defaultValue = "你是谁?") String msg) {35 // 构建提示词36 Prompt prompt = new Prompt(msg, DashScopeChatOptions.builder()37 .withModel("qwen-max")38 .withTemperature(0.8)39 .build());40
41 // 对话42 ChatResponse chatResponse = dashScopeChatModel.call(prompt);43 return chatResponse.getResult().getOutput().getText();44 }45
46 /**47 * 接入阿里百炼流式对话模型 qwq-32b48 *49 * @param msg50 * @return51 */52 (value = "/stream", produces = "text/html;charset=UTF-8")53 public Flux<String> streamByQwq32b((defaultValue = "你是谁?") String msg) {54 // 构建提示词55 Prompt prompt = new Prompt(msg, DashScopeChatOptions.builder()56 .withModel("qwq-32b")57 .withTemperature(0.8)58 .build());59
60 // 对话61 Flux<ChatResponse> chatResponseFlux = dashScopeChatModel.stream(prompt);62 return chatResponseFlux.map((r) -> r.getResult() != null && r.getResult().getOutput() != null && r.getResult().getOutput().getText() != null ? r.getResult().getOutput().getText() : "").filter(StringUtils::hasText);63 }64
65 /**66 * 接入阿里百炼文生图模型 wanx2.1-t2i-plus67 *68 * @param msg69 * @return70 */71 (value = "/image", produces = "text/html;charset=UTF-8")72 public void image((defaultValue = "生成一个美女") String msg, HttpServletResponse httpServletResponse) throws IOException {73 // 构建图片提示词74 ImagePrompt imagePrompt = new ImagePrompt(msg,75 DashScopeImageOptions.builder()76 .withModel(DashScopeImageApi.DEFAULT_IMAGE_MODEL)77 .withN(1)//要生成的图像数。必须介于 1 和 10 之间。78 .withHeight(1024)//生成的图像的高宽度。79 .withWidth(1024).build());80
81 // 生成82 ImageResponse imageResponse = dashScopeImageModel.call(imagePrompt);83 String imageUrl = imageResponse.getResult().getOutput().getUrl();84
85 //输出到浏览器86 URL url = URI.create(imageUrl).toURL();87 InputStream in = url.openStream();88 httpServletResponse.setHeader("Content-Type", MediaType.IMAGE_PNG_VALUE);89 httpServletResponse.getOutputStream().write(in.readAllBytes());90 httpServletResponse.getOutputStream().flush();91 }92
93 /**94 * 接入阿里百炼文生语音模型 cosyvoice-v195 *96 * @param msg97 * @return98 */99 (value = "/audio", produces = "text/html;charset=UTF-8")100 public String audio((defaultValue = "床前明月光,疑是地上霜。举头望明月,低头思故乡。") String msg) throws IOException {101 // 构建语音提示词102 SpeechSynthesisPrompt speechSynthesisPrompt = new SpeechSynthesisPrompt(103 msg,104 DashScopeSpeechSynthesisOptions.builder()105 .withSpeed(1.0) // 设置语速106 .withPitch(0.9) // 设置音调107 .withVolume(60) // 设置音量108 .build());109
110 // 生成111 SpeechSynthesisResponse response = dashScopeSpeechSynthesisModel.call(speechSynthesisPrompt);112
113 // 输出到文件114 File file = new File("D:\\output.mp3");115 try (FileOutputStream fos = new FileOutputStream(file)) {116 ByteBuffer byteBuffer = response.getResult().getOutput().getAudio();117 fos.write(byteBuffer.array());118 }119
120 return "生成成功,请查看:" + file.getAbsolutePath();121 }122}
4. 接入Ollma本地模型
1) 部署本地模型
- 安装Ollma平台:访问官网
https://ollama.com/下载对应系统的Ollma安装包进行安装,注意配置环境。 - 拉取AI模型:访问模型库
https://ollama.com/library挑选所需的AI模型,通过ollama run deepseek-r1:1.5b命令拉取。 - 启动AI对话:模型安装成功后,可通过
ollama run deepseek-r1:1.5b开启对话。
注意:
- Ollma本地模型默认安装在C盘,可通过
OLLAMA_MODELS环境变量进行修改。
2) 引入依赖
xxxxxxxxxx61<!-- Spring AI 集成 Ollma本地模型 -->2<dependency>3 <groupId>group.springframework.ai</groupId>4 <artifactId>spring-ai-ollama-spring-boot-starter</artifactId>5 <version>${spring-ai-ollma.version}</version>6</dependency>
3) 修改配置
xxxxxxxxxx81spring2 ai3 # Ollma本地模型4 ollama5 base-urlhttp//localhost114346 chat7 options8 modeldeepseek-r11.5b
4) 编写Controller
xxxxxxxxxx291/**2 * Sping AI 接入对话模型(定制客户端)3 */4("/ollma")6public class OllmaClientModelController {7
8 9 private OllamaChatModel ollamaChatModel;10
11 /**12 * 接入Ollma本地对话模型 deepseek-r1:1.5b13 *14 * @param msg15 * @return16 */17 ("/chat")18 public String chat((defaultValue = "你是谁?") String msg) {19 // 构建提示词20 OllamaOptions ollamaOptions = OllamaOptions.create();21 ollamaOptions.withModel("deepseek-r1:1.5b").withTemperature(0.8F);22 Prompt prompt = new Prompt(msg, ollamaOptions);23
24 // 对话25 ChatResponse chatResponse = ollamaChatModel.call(prompt);26 return chatResponse.getResult().getOutput().getContent();27 }28
29}
5. ChatClient工具
1) 什么是ChatClient?
ChatModel是 Spring AI 与 AI 模型交互的基础接口,直接和具体的 AI 模型(如OpenAI、DeepSeek、通义千问等)进行交互。
ChatClient是对 ChatModel 的进一步封装,它屏蔽了底层模型的差异性,为开发者提供了统一的接口来和不同的 AI 模型进行交互。
2) 配置ChatClient
xxxxxxxxxx951/**2 * AI 相关配置3 */4public class AiConfig {6
7 /**8 * 对话记忆存储器(用于存储历史对话记录,实现对话连续性)9 */10 11 public ChatMemory chatMemory() {12 return new InMemoryChatMemory();13 }14
15 /**16 * 向量数据库17 *18 * @param embeddingModel 向量模型(通过yml配置自动创建和注入)19 * @return 向量数据库20 */21 22 VectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {23 return SimpleVectorStore.builder(embeddingModel).build();24 }25
26 /**27 * 通用对话客户端(支持多种AI模型的基础功能)28 *29 * @param chatClientBuilder30 * @return31 */32 33 public ChatClient chatClient(ChatClient.Builder chatClientBuilder, ChatMemory chatMemory, VectorStore vectorStore) {34 return chatClientBuilder35 .defaultSystem("请以中文友好回答。") // 默认角色预设36 .defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory)) // 对话记忆存储37 .defaultAdvisors(new QuestionAnswerAdvisor(vectorStore)) // 向量数据库38 .defaultTools("addOperation", "mulOperation") // AI工具函数39 .build();40 }41}42
43/**44 * AI工具函数配置45 */46public class ToolsConfig {49 /**50 * 加法函数输入51 *52 * @param a53 * @param b54 */55 public record AddOperation(int a, int b) {56 }57
58 /**59 * 乘法函数输入60 *61 * @param m62 * @param n63 */64 public record MulOperation(int m, int n) {65 }66
67 /**68 * 加法函数69 *70 * @return 匿名内部类对象71 */72 73 ("加法运算")74 public Function<AddOperation, Integer> addOperation() {75 return request -> {76 log.info("加法函数被调用,参数为:{}", request);77 return request.a + request.b;78 };79 }80
81 /**82 * 乘法函数83 *84 * @return 匿名内部类对象85 */86 87 ("乘法运算")88 public Function<MulOperation, Integer> mulOperation() {89 return request -> {90 log.info("乘法函数被调用,参数为:{}", request);91 return request.m * request.n;92 };93 }94}95
3) 使用ChatClient
xxxxxxxxxx511/**2 * Sping AI 接入对话模型(通用客户端)3 */4("/chatclient")6public class ChatClientController {7
8 /**9 * 对话模型通用客户端(也支持流式对话)10 */11 12 private ChatClient chatClient;13
14 /**15 * 接入阿里百炼对话模型 qwen-max(注意修改yml文件中的模型配置)16 *17 * @param msg18 * @return19 */20 ("/chat")21 public String chat((name = "sessionId", defaultValue = "1") Integer sessionId, (defaultValue = "你是谁?") String msg) {22 return chatClient.prompt()23 .system("您是一个航天助手,正在通过在线聊天和客户进行互动,请以友好的中文进行回复。") // 个性化角色预设24 .user(msg) // 用户消息25 .advisors(spec -> spec26 .param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId)27 .param(AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100)28 )29 .call()// 对话30 .content();31 }32
33 /**34 * 接入阿里百炼对话模型 qwq-32b(注意修改yml文件中的模型配置)35 *36 * @param msg37 * @return38 */39 (value = "/stream", produces = "text/html;charset=UTF-8")40 public Flux<String> stream((name = "sessionId", defaultValue = "1") Integer sessionId, (defaultValue = "你是谁?") String msg) {41 return chatClient.prompt()42 .system("你是KD公司的智能风控小助手。") // 个性化角色预设43 .user(msg) // 用户消息44 .advisors(spec -> spec45 .param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId)46 .param(AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100)47 )48 .stream()// 流式对话49 .content();50 }51}
6. 检索增强生成(RAG)
1) 什么是RAG?
RAG(Retrieval-Augmented Generation )指检索增强生成式人工智能,是一种将大型语言模型(LLM)与外部知识源相结合的人工智能技术。通过在生成响应前检索相关信息,RAG 能够为模型提供最新且特定领域的知识,从而提高回答的准确性和相关性。
2) 对数据进行向量化
步骤:文档 → 解析 → chunks → Embedding → 向量 → 存入向量库,最终结果形成知识库,整个过程叫 indexing。
xxxxxxxxxx761/**2 * 检索增强生成(RAG)3 */4("/embedding")6public class EmbeddingController {7
8 /**9 * 千问向量模型(SpringBoot根据yml中的配置自动创建)10 */11 12 private DashScopeEmbeddingModel embeddingModel;13
14 /**15 * 向量数据库(AiConfig中配置了一个内存向量数据,用于存储向量化后的私有知识,实现检索增强生成(RAG))16 */17 18 private VectorStore vectorStore;19
20 /**21 * 向量化文本22 *23 * @param msg 文本24 */25 ("/embed")26 public void embed((defaultValue = "我是黄原鑫") String msg) {27 // 存储28 List<Document> documents = List.of(new Document(msg));29 System.out.println(documents);30 vectorStore.add(documents);31 }32
33 /**34 * 向量化文件35 */36 ("/embedFile")37 public void embedFile() throws IOException {38 // 加载文件39 Resource resource = new ClassPathResource("rag/机票预订须知.txt");40
41 // 分割42 TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resource);43 List<Document> splitDocuments = new TokenTextSplitter().apply(tikaDocumentReader.read());44 System.out.println(splitDocuments);45
46 // 存储47 vectorStore.add(splitDocuments);48
49 }50
51
52 /**53 * 向量化查询54 *55 * @param msg 文本56 */57 ("/query")58 public String query((defaultValue = "我是谁?") String msg) {59
60 // 构建向量查询请求61 SearchRequest request = SearchRequest.builder()62 .query(msg)63 .topK(3)64 .build();65
66 // 向量查询67 List<Document> result = vectorStore.similaritySearch(request);68 if (result == null || result.isEmpty()) {69 return "";70 }71
72 // 输出73 System.out.println(result);74 return result.toString();75 }76}
3) 增强生成内容
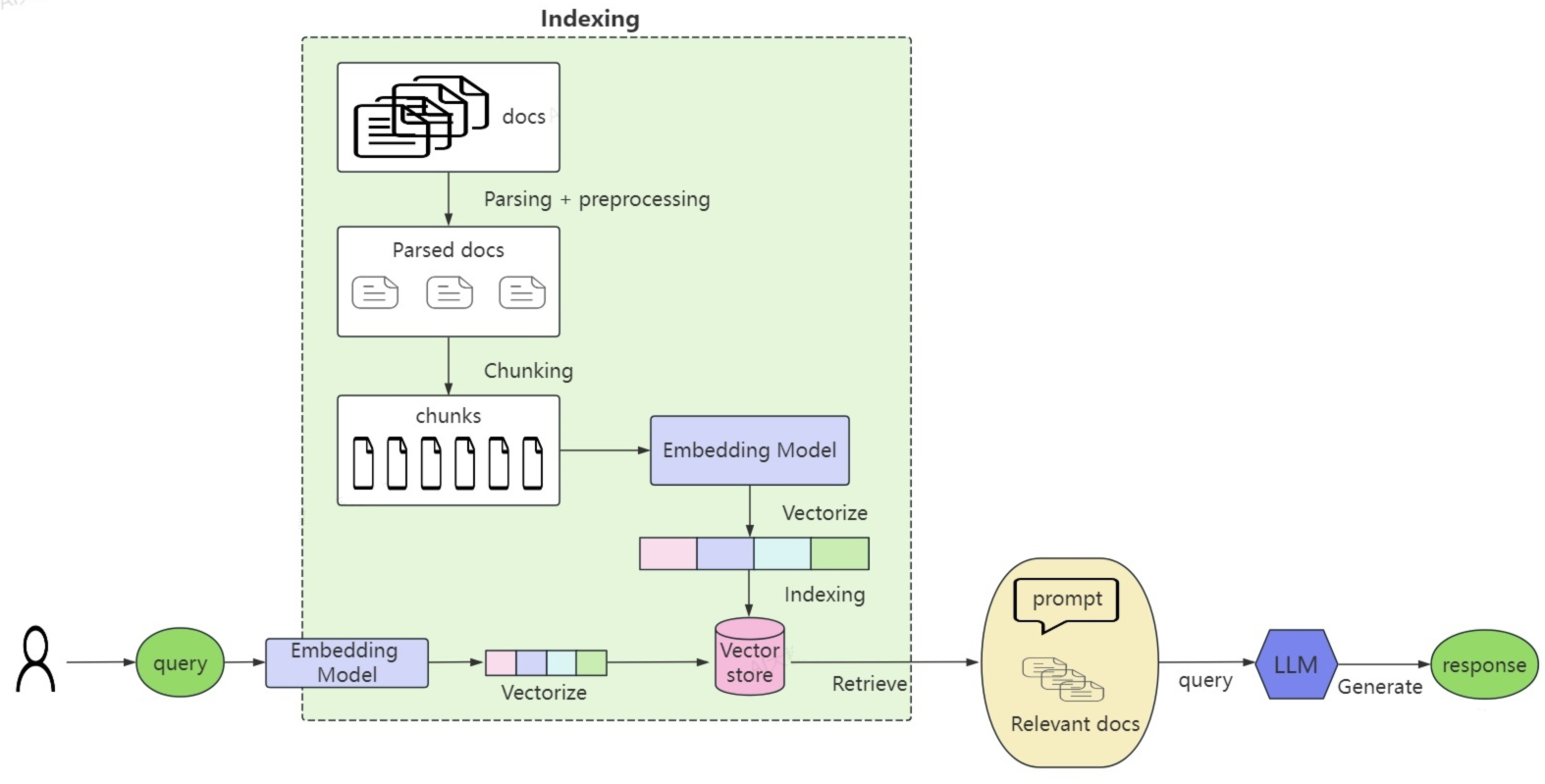
一个 RAG 系统的数据流程如下:
- 离线预处理(Indexing):先把原始文档解析、清洗,切分成短文本块;再用 Embedding 模型把文本块转成语义向量,最后存入向量数据库,完成知识库构建。
- 在线查询:用户提问后,用同一 Embedding 模型把问题转成向量,在向量库中检索出语义最相关的文档。
- 生成回答:把用户问题 + 检索到的上下文拼成 Prompt,输入大模型,生成有事实依据、无幻觉的最终回答。
代码请参考前一小节示例。
第二节 Spring AI Alibaba
1. Spring AI Alibaba 简介
1) 什么是Spring AI Alibaba?
Spring AI Alibaba 是阿里云基于官方 Spring AI 构建、专为 Java 开发者设计的开源企业级 AI 应用与 AI Agent 开发框架。
- 官网地址:https://java2ai.com/
- 阿里百炼:https://bailian.console.aliyun.com/
- 版本推荐:https://java2ai.com/docs/versions
项目架构分为三层:
- Agent Framework:基于 ReactAgent 理念构建支持自动上下文工程与人机交互的 Agent 。
- Graph:底层工作流与多代理协调框架,提供预置节点和简化的状态管理,作为 Agent Framework 的运行时基座。
- Augmented LLM:基于 Spring AI 的原子抽象,提供模型、工具、MCP、消息、向量存储等 LLM 应用基础能力。
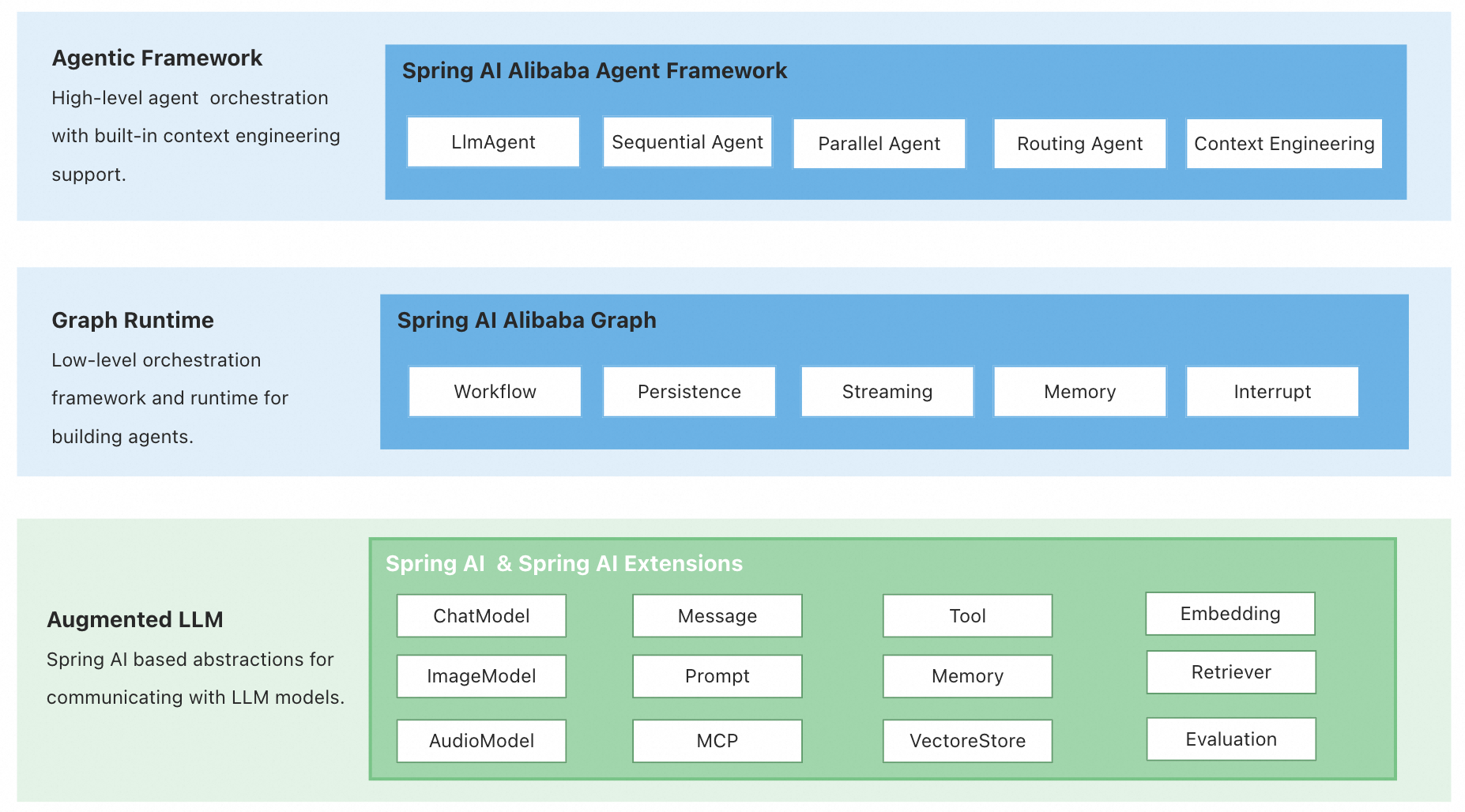
2) 主流 Java AI 框架选型
以下是当前主流 Java AI 框架对比情况:
| 对比维度 | Spring AI Alibaba | Spring AI | LangChain4J |
|---|---|---|---|
| Spring Boot 集成 | 原生支持 | 原生支持 | 社区适配 |
| 文本模型 | 主流模型,可扩展 | 主流模型,可扩展 | 主流模型,可扩展 |
| 音视频、多模态、向量模型 | 支持 | 支持 | 支持 |
| RAG | 模块化 RAG | 模块化 RAG | 模块化 RAG |
| 向量数据库 | 主流向量数据库 阿里云ADB、OpenSearch等 | 主流向量数据库 | 主流向量数据库 |
| MCP 支持 | 支持 Nacos MCP Registry 支持 | 支持 | 支持 |
| 函数调用 | 支持(20+官方工具集成) | 支持 | 支持 |
| 提示词模版 | 硬编码,无声明式注解 | 硬编码,无声明式注解 | 声明式注解 |
| 提示词管理 | Nacos 配置中心 | 无 | 无 |
| Chat Memory | 优化版JDBC、Redis、ElasticSearch | JDBC、Neo4j、Cassandra | 多种实现适配 |
| 可观测性 | 支持,可接入阿里云ARMS | 支持 | 部分支持 |
| 工作流 Workflow | 支持,兼容 Dify、百炼 DSL | 无 | 无 |
| 多智能体 Multi-agent | 支持,官方通用智能体实现 | 无 | 无 |
| 模型评测 | 支持 | 支持 | 支持 |
| 社区活跃度与文档健全性 | 官方社区,活跃度高 | 官方社区,活跃度高 | 个人发起社区 |
| 开发提效组件 | 丰富,包括调试、代码生成工具等 | 无 | 无 |
| Example 仓库 | 丰富,活跃度高 | 较少 | 丰富,活跃度高 |
Spring AI Alibaba不仅可以通过 Nacos 配置中心管理提示词,还在可观测性、工作流、多智能体方面做的更好。
2. 入门案例
1) 导入依赖
父工程:
xxxxxxxxxx481 2<project xmlns="http://maven.apache.org/POM/4.0.0"3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">5 <modelVersion>4.0.0</modelVersion>6
7 <groupId>com.huangyuanxin.ai</groupId>8 <artifactId>SpringAI-Alibaba-demo</artifactId>9 <version>1.0-SNAPSHOT</version>10 <packaging>pom</packaging>11 <modules>12 <module>SpringAI-Alibaba-demo01</module>13 </modules>14
15 <!-- 必须基于 JDK 17+ 构建 -->16 <properties>17 <maven.compiler.source>17</maven.compiler.source>18 <maven.compiler.target>17</maven.compiler.target>19 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>20 </properties>21
22 <!-- 依赖管理 -->23 <dependencyManagement>24 <dependencies>25 <dependency>26 <groupId>com.alibaba.cloud.ai</groupId>27 <artifactId>spring-ai-alibaba-bom</artifactId>28 <version>1.1.2.0</version>29 <type>pom</type>30 <scope>import</scope>31 </dependency>32 <dependency>33 <groupId>org.springframework.ai</groupId>34 <artifactId>spring-ai-bom</artifactId>35 <version>1.1.2</version>36 <type>pom</type>37 <scope>import</scope>38 </dependency>39 <dependency>40 <groupId>com.alibaba.cloud.ai</groupId>41 <artifactId>spring-ai-alibaba-extensions-bom</artifactId>42 <version>1.1.2.1</version>43 <type>pom</type>44 <scope>import</scope>45 </dependency>46 </dependencies>47 </dependencyManagement>48</project>子工程:
xxxxxxxxxx331 2<project xmlns="http://maven.apache.org/POM/4.0.0"3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">5 <modelVersion>4.0.0</modelVersion>6 <parent>7 <groupId>com.huangyuanxin.ai</groupId>8 <artifactId>SpringAI-Alibaba-demo</artifactId>9 <version>1.0-SNAPSHOT</version>10 </parent>11
12 <artifactId>SpringAI-Alibaba-demo01</artifactId>13
14 <properties>15 <maven.compiler.source>23</maven.compiler.source>16 <maven.compiler.target>23</maven.compiler.target>17 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>18 </properties>19
20 <dependencies>21 <dependency>22 <groupId>com.alibaba.cloud.ai</groupId>23 <artifactId>spring-ai-alibaba-agent-framework</artifactId>24 </dependency>25
26 <dependency>27 <groupId>com.alibaba.cloud.ai</groupId>28 <artifactId>spring-ai-alibaba-starter-dashscope</artifactId>29 </dependency>30
31 </dependencies>32
33</project>
2) Agent示例
xxxxxxxxxx231public class AgentExample {2
3 public static void main(String[] args) throws Exception {4 // 创建模型实例5 DashScopeApi dashScopeApi = DashScopeApi.builder()6 .apiKey("sk-441a047d9be542778a471a00ebbf9df1") // 生产环境通过系统环境变量获取7 .build();8 ChatModel chatModel = DashScopeChatModel.builder()9 .dashScopeApi(dashScopeApi)10 .build();11
12 // 创建 Agent13 ReactAgent agent = ReactAgent.builder()14 .name("智能问答助手")15 .model(chatModel)16 .instruction("你是一个智能问答助手,可以回答用户的任何问题")17 .build();18
19 // 运行 Agent20 AssistantMessage response = agent.call("你好!你是谁?");21 System.out.println(response.getText()); // 你好!😊 我是通义千问(Qwen)......22 }23}
第三节 LangChain4J
1. 基本使用
1) 导入依赖
xxxxxxxxxx431<dependencies>2 <!-- LangChain4j核心 -->3 <dependency>4 <groupId>dev.langchain4j</groupId>5 <artifactId>langchain4j</artifactId>6 <version>1.0.1</version>7 </dependency>8 <!-- LangChain4j的MCPClient -->9 <dependency>10 <groupId>dev.langchain4j</groupId>11 <artifactId>langchain4j-mcp</artifactId>12 <version>1.0.1-beta6</version>13 </dependency>14
15 <!-- OpenAI/DeepSeek -->16 <dependency>17 <groupId>dev.langchain4j</groupId>18 <artifactId>langchain4j-open-ai</artifactId>19 <version>1.0.1</version>20 </dependency>21
22 <!-- 阿里百炼 -->23 <dependency>24 <groupId>dev.langchain4j</groupId>25 <artifactId>langchain4j-community-dashscope</artifactId>26 <version>1.0.1-beta6</version>27 </dependency>28
29 <!-- Ollama本地模型 -->30 <dependency>31 <groupId>dev.langchain4j</groupId>32 <artifactId>langchain4j-ollama</artifactId>33 <version>1.0.1-beta6</version>34 </dependency>35
36 <!-- 单元测试 -->37 <dependency>38 <groupId>org.junit.jupiter</groupId>39 <artifactId>junit-jupiter</artifactId>40 <version>5.8.2</version>41 <scope>test</scope>42 </dependency>43</dependencies>
2) 接入对话模型
xxxxxxxxxx571/**2 * 一、LangChain4J接入常见对话模型3 *4 * @author HuangYuanXin5 * @date 2025/06/18 05:466 **/7public class Test01_LangChain4J {8
9 /**10 * 1. 接入DeepSeek官方的 deepseek-chat 模型11 */12 13 public void deepseekChat() {14 // 构建模型15 OpenAiChatModel model = OpenAiChatModel.builder()16 .baseUrl("https://api.deepseek.com")17 .apiKey("sk-04b52cab40d7443486c24a7a09691ec9")18 .modelName("deepseek-chat").build();19
20 // 对话21 String answer = model.chat("你好,你是谁?");22 System.out.println(answer);23 }24
25 /**26 * 2. 接入阿里百炼的 qwen-max 模型27 */28 29 public void qwenMax() {30 // 构建模型31 QwenChatModel model = QwenChatModel.builder()32 .apiKey("sk-441a047d9be542778a471a00ebbf9df8")33 .modelName("qwen-max")34 .build();35
36 // 对话37 String answer = model.chat("你好,你是谁?");38 System.out.println(answer);39 }40
41 /**42 * 3. 接入Ollama本地的 deepseek-r1:1.5b 模型43 */44 45 public void OllamaChat() {46 // 构建模型47 OllamaChatModel model = OllamaChatModel.builder()48 .baseUrl("http://localhost:11434") // Ollama默认端口为1143449 .modelName("deepseek-r1:1.5b")50 .build();51
52 // 对话53 String answer = model.chat("你好,你是谁?");54 System.out.println(answer);55 }56
57}
3) 接入图片/语音模型
xxxxxxxxxx451/**2 * 二、LangChain4J接入图片/语音模型3 */4public class Test02_ImageAudition {5 /**6 * 1. 接入阿里炼的文生图模型:万相7 */8 9 public void generateImage() {10 // 构建文生图模型11 WanxImageModel model = WanxImageModel.builder()12 .modelName("wanx2.1-t2i-plus")13 .apiKey("sk-441a047d9be542778a471a00ebbf9df8")14 .build();15
16 // 生成图片17 Response<Image> response = model.generate("美女");18 System.out.println(response.content().url());19 }20
21 /**22 * 2. 接入阿里百炼的文生语音模型:cosyvoice-v123 */24 25 public void generateAudition() {26 // 调用参数27 SpeechSynthesisParam param = SpeechSynthesisParam.builder()28 .apiKey("sk-441a047d9be542778a471a00ebbf9df8")29 .model("cosyvoice-v1")30 .text("大家好,我是黄原鑫")31 .build();32
33 // 调用模型34 SpeechSynthesizer speechSynthesizer = new SpeechSynthesizer();35 ByteBuffer audio = speechSynthesizer.call(param);36
37 // 输出到文件38 File file = new File("D:\\output.mp3");39 try (FileOutputStream fos = new FileOutputStream(file)) {40 fos.write(audio.array());41 } catch (IOException e) {42 throw new RuntimeException(e);43 }44 }45}
4) 实现智能体(AI Agent)
xxxxxxxxxx1041/**2 * 三、基于LangChain4J实现智能体(多个AI模型编排)3 *4 * @author HuangYuanXin5 * @date 2025/06/18 05:466 **/7public class Test03_IntelligentAgent {9
10 /**11 * 业务类型枚举12 */13 public enum BizType {14 ("查询图书信息")15 QUERY_BOOK,16 ("上架图书")17 ADD_BOOK,18 ("其它业务")19 OTHER20 }21
22 /**23 * 业务类型识别器24 */25 interface BizTypeRecognizer {26 ("以下文本是什么业务类型:{{it}}")27 BizType identify(String msg);28 }29
30 /**31 * 聊天机器人32 */33 interface ChatBot {34 ("""35 你是图书管理系统的管理员,请为客户服务。36 """)37 String reply(String msg);38 }39
40 /**41 * 业务处理器42 */43 class BizHandler {44 private BizTypeRecognizer bizTypeRecognizer;45 private ChatBot chatBot;46
47 public BizHandler(BizTypeRecognizer bizTypeRecognizer, ChatBot chatBot) {48 this.bizTypeRecognizer = bizTypeRecognizer;49 this.chatBot = chatBot;50 }51
52 /**53 * 处理业务54 *55 * @param msg56 * @return57 */58 public String handle(String msg) {59 // 识别业务类型60 BizType bizType = bizTypeRecognizer.identify(msg);61
62 // 根据业务类型处理业务63 switch (bizType) {64 case QUERY_BOOK:65 log.info("queryBook: {}", msg);66 return "查询图书成功,只有1本《格列夫游记》"; // 已知业务调用对应API接口67 case ADD_BOOK:68 log.info("addBook: {}", msg);69 return "添加图书成功"; // 已知业务调用对应API接口70 case OTHER:71 log.info("other: {}", msg);72 return chatBot.reply(msg); // 其它类型任务交给智能助手处理73 default:74 log.info("unknown biz type");75 return "业务类型识别错误";76 }77 }78 }79
80 /**81 * 使用AI模型+业务接口处理业务82 */83 84 public void test() {85 // 创建多个AI对话模型86 OpenAiChatModel deepseekChatModel = OpenAiChatModel.builder()87 .baseUrl("https://api.deepseek.com")88 .apiKey("sk-04b52cab40d7443486c24a7a09691ec9")89 .modelName("deepseek-chat").build();90 QwenChatModel qwenChatModel = QwenChatModel.builder()91 .apiKey("sk-441a047d9be542778a471a00ebbf9df8")92 .modelName("qwen-max")93 .build();94
95 // 使用AI模型+业务接口创建业务对象96 BizTypeRecognizer bizTypeRecognizer = AiServices.create(BizTypeRecognizer.class, deepseekChatModel);97 ChatBot chatBot = AiServices.create(ChatBot.class, qwenChatModel);98
99 // 使用AI业务对象处理业务100 BizHandler bizHandler = new BizHandler(bizTypeRecognizer, chatBot);101 String rssult = bizHandler.handle("帮我查询一共有多少图书?");102 System.out.println(rssult);103 }104}
5) 调用MCP服务
xxxxxxxxxx161/**2 * 通过LangChain4J调用MCP服务(MCP是一种AI工具服务调用协议)3 *4 * @author HuangYuanXin5 * @date 2025/06/18 05:466 **/7public class Test03_MCPClient {9
10 // 测试npx方式调用百度地图MCP11 12 public void test() {13 // TODO14 }15
16}
2. 整合SpringBoot
1) 引入依赖
xxxxxxxxxx341<dependencies>2 <!-- LangChain4j框架 -->3 <dependency>4 <groupId>dev.langchain4j</groupId>5 <artifactId>langchain4j</artifactId>6 <version>1.0.1</version>7 </dependency>8
9 <!-- WEB启动器 -->10 <dependency>11 <groupId>org.springframework.boot</groupId>12 <artifactId>spring-boot-starter-web</artifactId>13 </dependency>14
15 <!-- WEBFLUX启动器 -->16 <dependency>17 <groupId>org.springframework.boot</groupId>18 <artifactId>spring-boot-starter-webflux</artifactId>19 </dependency>20
21 <!-- OpenAi/DeepSeek启动器 -->22 <dependency>23 <groupId>dev.langchain4j</groupId>24 <artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>25 <version>1.0.1-beta6</version>26 </dependency>27
28 <!-- 阿里百炼启动器 -->29 <dependency>30 <groupId>dev.langchain4j</groupId>31 <artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>32 <version>1.0.1-beta6</version>33 </dependency>34</dependencies>
2) 模型配置
xxxxxxxxxx241server2 port80803
4langchain4j5 # OpenAi/Deepseek6 open-ai7 chat-model8 base-urlhttps//api.deepseek.com9 api-keysk-04b52cab40d7443486c24a7a09691ec910 model-namedeepseek-chat11 # 阿里百炼12 community13 dashscope14 # 对话模型15 chat-model16 api-keysk-441a047d9be542778a471a00ebbf9df817 model-nameqwen-max18 # 流式对话模型19 streaming-chat-model20 api-keysk-441a047d9be542778a471a00ebbf9df821 model-nameqwq-32b22 # 向量模型23 embedding-model24 api-keysk-441a047d9be542778a471a00ebbf9df8
3) 创建代理
xxxxxxxxxx941/**2 * AI相关配置3 */4public class AiConfig {6
7 /**8 * AI工具服务(用于function-call调用)9 */10 11 private AiToolsService aiToolsService;12
13 /**14 * 对话记忆存储器(用于存储历史对话记录,实现对话连续性)15 */16 17 private RedisMemoryStore redisMemoryStore;18
19 /**20 * 向量数据库(用于存储向量化后的私有知识,实现检索增强生成(RAG),常见向量数据库有:内存向量数据库、Redis向量数据库、Elasticsearch向量数据库等)21 *22 * @return23 */24 25 public EmbeddingStore<TextSegment> embeddingStore() {26 return new InMemoryEmbeddingStore<>(); // 内存向量数据库27 }28
29 /**30 * AI模型代理接口(LangChain4J会根据接口生成代理对象,并根据构建参数实现附加功能)31 */32 public interface AiModelProxy {33 /**34 * 对话35 *36 * @param memoryId 记忆ID 一般是会话ID或用户ID37 * @param msg 用户消息38 * @return 对话应答39 */40 ("""41 您是一个航天助手,正在通过在线聊天和客户进行互动,请以友好的中文进行回复。42 """)43 String chat( int memoryId, String msg);44
45 /**46 * 对话(流式)47 *48 * @param memoryId 记忆ID 一般是会话ID或用户ID49 * @param msg 用户消息50 * @param bizdate 业务日期(通过系统消息预设角色时所用的参数)51 * @return 对话应答(流式)52 */53 ("""54 您是KD公司的交易实时风控系统,正在通过在线聊天和客户进行互动,请以友好的中文进行回复。55 您可以为客户查询指标的阈值、设置指标的阈值,以及删除指标等操作。56 今天的业务日期是{{bizdate}}57 """)58 TokenStream stream( int memoryId, String msg, ("bizdate") Integer bizdate);59 }60
61 /**62 * AI模型代理(调用AI模型对话,并添加了一些额外功能)63 *64 * @param qwenChatModel AI对话模型65 * @param qwenStreamingChatModel AI流式对话模型66 * @param qwenEmbeddingModel AI向量模型67 * @param embeddingStore 向量数据库68 * @return AI模型代理对象69 */70 71 public AiModelProxy qwenAiModelProxy(QwenChatModel qwenChatModel, QwenStreamingChatModel qwenStreamingChatModel, QwenEmbeddingModel qwenEmbeddingModel, EmbeddingStore<TextSegment> embeddingStore) {72
73 // 构建内容检索器(用于检索向量数据库,实现检索增强生成(RAG))74 EmbeddingStoreContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()75 .embeddingStore(embeddingStore) // 从哪个向量数据库检索76 .embeddingModel(qwenEmbeddingModel) // 检索时使用的AI向量模型77 .maxResults(5) // 最大结果数78 .minScore(0.5) // 最小匹配分数79 .build();80
81 // 创建Ai模型代理82 AiModelProxy qwenAiModelProxy = AiServices.builder(AiModelProxy.class)83 .chatModel(qwenChatModel) // AI对话模型84 .streamingChatModel(qwenStreamingChatModel) // AI流式对话模型85 .chatMemoryProvider(memoryId -> MessageWindowChatMemory.builder().maxMessages(10).id(memoryId).build()) // 对话记忆存储器86 //.chatMemoryProvider(memoryId -> MessageWindowChatMemory.builder().maxMessages(10).id(memoryId).chatMemoryStore(redisMemoryStore).build()) // 使用自定义的对话记忆存储器87 .tools(aiToolsService) // AI工具服务(用于function-call调用)88 .contentRetriever(contentRetriever) // 内容检索器(用于检索向量数据库,实现检索增强生成(RAG))89 .build();90
91 return qwenAiModelProxy;92 }93
94}
4) 流式对话
xxxxxxxxxx351/**2 * LangChain4J接入常见AI流式对话模型(SpringBoot版)3 */4("/stream")6public class StreamController {7
8 /**9 * 使用AI模型代理流式对话(附加:预设角色、对话记忆存储、AI工具服务、检索增强生成)10 *11 * @param msg12 * @return13 */14 15 private AiConfig.AiModelProxy qwenAiModelProxy;16
17 /**18 * 使用AI模型代理流式对话(附加:预设角色、对话记忆存储、AI工具服务、检索增强生成)19 *20 * @param msg21 * @return22 */23 (value = "/qwenAiModelProxy", produces = "text/stream;charset=UTF-8")24 public Flux<String> chatByQwenAiModelProxy((name = "sessionId", defaultValue = "1") Integer sessionId, (defaultValue = "你是谁?") String msg) {25 TokenStream tokenStream = qwenAiModelProxy.stream(sessionId, msg, Integer.valueOf(LocalDate.now().format(DateTimeFormatter.ofPattern("yyyyMMdd"))));26
27 return Flux.create(sink -> {28 tokenStream.onPartialResponse(s -> sink.next(s))29 .onCompleteResponse(c -> sink.complete())30 .onError(sink::error)31 .start();32 });33 }34
35}
第04章_AI应用开发(Python)
第一节 Python 基础语法
1. 数据类型
xxxxxxxxxx321# ─── 数字 ───2a = 10 # int(任意大小,无 BigInteger)3b = 3.14 # float4c = 3 + 4j # complex5
6# ─── 布尔 ───7is_active = True # 首字母大写8is_deleted = False9
10# ─── 字符串 ───11name = "Alice"12# f-string(推荐,Python 3.6+)13msg = f"My name is {name}, age is {2026-1994}"14
15# ─── 列表(= Java ArrayList) ───16numbers = [1, 2, 3, 4, 5]17numbers.append(6) # 末尾添加18sliced = numbers[1:3] # [2, 3](切片)19squares = [x**2 for x in range(10)] # 列表推导式20
21# ─── 元组(不可变列表) ───22point = (10, 20) # 创建后不能修改23x, y = point # 解包24
25# ─── 字典(= Java HashMap) ───26person = {"name": "Alice", "age": 30}27name = person.get("name", "Unknown") # 安全访问28for key, value in person.items(): # 遍历29 print(key, value)30
31# ─── 集合(去重) ───32unique = {1, 2, 3, 3} # {1, 2, 3}
2. 控制流
xxxxxxxxxx301# ─── if-elif-else ───2score = 853if score >= 90:4 grade = "A"5elif score >= 80:6 grade = "B"7else:8 grade = "C"9
10# ─── for 循环 ───11for i, item in enumerate(["a", "b", "c"]): # 同时取索引和值12 print(i, item)13
14# ─── while ───15while True:16 cmd = input("> ")17 if cmd == "quit":18 break19 20# ─── match/case 模式匹配 ───21def route_by_intent(state: dict) -> str:22 match state:23 case {"intent": "risk_query"}:24 return "risk_agent"25 case {"intent": "knowledge_search"}:26 return "kb_agent"27 case {"intent": "alert", "confidence": c} if c > 0.8:28 return "auto_process"29 case _:30 return "general_agent"
3. 函数
xxxxxxxxxx181# ─── 基本定义(不需要声明返回类型) ───2def add(a, b):3 return a + b4
5# ─── 默认参数 ───6def greet(name, greeting="Hello"):7 return f"{greeting}, {name}!"8
9# ─── 可变参数(*args 元组, **kwargs 字典) ───10def log(event, *args, **kwargs):11 print(f"[{event}]", args, kwargs)12
13log("error", "timeout", user="admin", code=500)14# [error] ('timeout',) {'user': 'admin', 'code': 500}15
16# ─── lambda(匿名函数) ───17square = lambda x: x ** 218sorted([3, 1, 2], key=lambda x: x) # [1, 2, 3]
4. 面向对象
xxxxxxxxxx261class Animal:2 species = "Unknown" # 类属性(所有实例共享,类似 Java static)3
4 def __init__(self, name): # 构造器(self = Java 的 this)5 self.name = name # 实例属性6
7 def speak(self):8 return f"{self.name} makes a sound"9
10# 继承11class Dog(Animal):12 def __init__(self, name, breed):13 super().__init__(name) # 调用父类构造器14 self.breed = breed15
16 def speak(self): # 重写17 return f"{self.name} barks"18
19# 特殊方法(魔术方法)20class Point:21 def __init__(self, x, y):22 self.x, self.y = x, y23 def __str__(self): # print() 时调用24 return f"Point({self.x}, {self.y})"25 def __eq__(self, other): # == 运算符26 return self.x == other.x and self.y == other.y
5. 模块与异常处理
xxxxxxxxxx151# ─── 导入 ───2from langgraph.graph import StateGraph, END3from tools.risk_tools import search_risk_policy4import config.settings5
6# ─── 异常处理(LangGraph 工具调用必备) ───7try:8 result = llm.invoke(messages)9except RateLimitError:10 time.sleep(2 ** attempt) # 指数退避11except APIError as e:12 logger.error(f"API错误: {e}")13 raise # 重新抛出14finally:15 pass # 总是执行(清理资源)
第二节 LangGraph 必备高级特性
1. 类型提示
LangChain / LangGraph 大量使用类型提示,必须掌握。
xxxxxxxxxx151from typing import List, Dict, Optional, Union, Callable, Literal, Annotated2
3# ─── 函数类型提示 ───4def search(query: str, top_k: int = 5) -> List[Dict[str, str]]:5 """搜索文档,返回结果列表"""6 return [{"content": "...", "score": "0.95"}]7
8# ─── 可选类型 ───9def find_user(id: int) -> Optional[dict]:10 return None # 可以返回 None11
12# ─── Literal:限定返回值(LangGraph 路由必备) ───13def route(state: dict) -> Literal["pass", "review", "reject"]:14 """返回值只能是这三个字符串之一"""15 return "pass"TypedDict(LangGraph State 定义核心)
xxxxxxxxxx161from typing import TypedDict, Annotated, Literal2from langgraph.graph.message import add_messages3
4# ─── 基础 State 定义 ───5class AgentState(TypedDict):6 """LangGraph 图状态:所有节点共享"""7 messages: Annotated[list, add_messages] # 关键:add_messages 自动追加而非覆盖8 intent: str9 context: list10 tool_calls: list11 pending_approval: bool12 final_response: str13
14# 对比:不用 Annotated + add_messages 的陷阱15class NaiveState(TypedDict):16 messages: list # 每次更新会完全覆盖,丢失对话历史!Annotated(LangGraph 字段合并策略)
xxxxxxxxxx121# Annotated[类型, 合并函数] — 定义 state 字段如何被节点更新2# add_messages: 追加消息(而非覆盖)3# 自定义合并: Annotated[int, lambda x, y: x + y] # 累加4# 自定义合并: Annotated[list, merge_lists] # 自定义函数5
6def merge_lists(left: list, right: list) -> list:7 return left + right8
9class State(TypedDict):10 messages: Annotated[list, add_messages]11 counter: Annotated[int, lambda x, y: x + y]12 items: Annotated[list, merge_lists]
2. 装饰器进阶
LangChain 的 @tool 就是用装饰器实现的。
xxxxxxxxxx361from functools import wraps2import time3
4# ─── @tool 的本质 ───5def my_tool(func):6 """模拟 @tool 装饰器:自动提取函数签名给 LLM"""7 (func) # 保留原函数的 __name__ 和 __doc__8 def wrapper(*args, **kwargs):9 print(f"调用工具: {func.__name__}")10 return func(*args, **kwargs)11 return wrapper12
13def search_kb(query: str) -> str:15 """搜索知识库"""16 return f"结果: {query}"17
18# ─── 带参数的装饰器(如 @retry(stop=3)) ───19def retry(max_attempts: int):20 def decorator(func):21 (func)22 def wrapper(*args, **kwargs):23 for attempt in range(max_attempts):24 try:25 return func(*args, **kwargs)26 except Exception:27 if attempt == max_attempts - 1:28 raise29 time.sleep(2 ** attempt)30 return wrapper31 return decorator32
33(max_attempts=3)34def call_llm(prompt: str) -> str:35 """带自动重试的 LLM 调用"""36 pass
3. 生成器与流式输出
xxxxxxxxxx161# ─── 生成器函数(yield) ───2def stream_tokens(text: str):3 """模拟 LLM 流式输出(逐 token 产出)"""4 for word in text.split():5 yield word # 暂停并返回当前值6
7for token in stream_tokens("Hello World from Agent"):8 print(token, end=" ") # Hello World from Agent9
10# ─── 生成器表达式 ───11squares = (x**2 for x in range(10)) # 惰性求值,内存友好12
13# ─── yield from:委托生成 ───14def chain():15 yield from range(3) # 等价于 for i in range(3): yield i16 yield from range(4, 6)
4. 异步编程(async/await)
LangGraph 默认使用异步执行,必须掌握。
xxxxxxxxxx301import asyncio2
3# ─── 基本语法 ───4async def fetch_data():5 await asyncio.sleep(1) # 模拟 IO,不阻塞其他任务6 return "数据"7
8async def main():9 result = await fetch_data() # 等待协程完成10 print(result)11
12asyncio.run(main()) # 入口:启动事件循环13
14# ─── 并发执行(gather) ───15async def analyze_transactions(txs: list) -> list:16 """并发分析多笔交易(实际项目用法)"""17 tasks = [analyze_one(tx) for tx in txs]18 results = await asyncio.gather(*tasks, return_exceptions=True)19 return results20
21# ─── 异步上下文管理器(aiofiles) ───22import aiofiles23async def read_file():24 async with aiofiles.open('file.txt', 'r') as f:25 return await f.read()26
27# ─── LangGraph 异步调用 ───28# agent.ainvoke() — 异步单次29# agent.astream() — 异步流式30# agent.abatch() — 异步批量
5. Pydantic 数据校验
LangChain 的工具参数校验、配置管理都基于 Pydantic。
xxxxxxxxxx221from pydantic import BaseModel, Field2
3class Transaction(BaseModel):4 id: str = Field(..., min_length=1, description="交易ID")5 amount: float = Field(..., gt=0, description="交易金额,必须>0")6 currency: str = Field(default="CNY")7
8# 自动校验9tx = Transaction(id="TX001", amount=50000)10print(tx.model_dump()) # {'id': 'TX001', 'amount': 50000.0, 'currency': 'CNY'}11
12# ─── LangChain 工具中的 Pydantic ───13from langchain_core.tools import tool14
15class SearchInput(BaseModel):16 query: str = Field(description="搜索关键词")17 top_k: int = Field(default=5, ge=1, le=20)18
19(args_schema=SearchInput)20def search_docs(query: str, top_k: int = 5) -> str:21 """搜索企业文档。LLM 会自动生成符合 schema 的参数。"""22 return f"搜索'{query}'的前{top_k}个结果"
第三节 大模型应用开发
1. OpenAI SDK 调用
xxxxxxxxxx401# pip install openai2from openai import OpenAI3
4client = OpenAI(5 api_key="sk-xxx", # 或使用环境变量6 base_url="https://api.openai.com/v1" # 可替换为兼容 API7)8
9# ─── 基本调用 ───10response = client.chat.completions.create(11 model="gpt-4o",12 messages=[13 {"role": "system", "content": "你是风控专家助手"},14 {"role": "user", "content": "大额交易怎么定义?"}15 ],16 temperature=0.7,17 max_tokens=50018)19print(response.choices[0].message.content)20print(f"tokens: {response.usage.prompt_tokens} in / {response.usage.completion_tokens} out")21
22# ─── 流式输出(打字机效果) ───23stream = client.chat.completions.create(24 model="gpt-4o",25 messages=[{"role": "user", "content": "介绍LangGraph"}],26 stream=True27)28for chunk in stream:29 if chunk.choices[0].delta.content:30 print(chunk.choices[0].delta.content, end='', flush=True)31
32# ─── DeepSeek 兼容接口(成本敏感场景替代方案) ───33client_ds = OpenAI(34 api_key="your-deepseek-key",35 base_url="https://api.deepseek.com"36)37response = client_ds.chat.completions.create(38 model="deepseek-chat",39 messages=[{"role": "user", "content": "你好"}]40)
2. LangChain LCEL(现代管道模式)
LCEL(LangChain Expression Language) 是 LangChain 的核心编程序范式,用 | 管道符串联组件。
xxxxxxxxxx191from langchain_openai import ChatOpenAI2from langchain_core.prompts import ChatPromptTemplate3from langchain_core.output_parsers import StrOutputParser4
5# ─── LCEL 基础管道 ───6llm = ChatOpenAI(model="gpt-4o", temperature=0.7)7prompt = ChatPromptTemplate.from_messages([8 ("system", "你是{role}"),9 ("user", "{question}")10])11
12chain = prompt | llm | StrOutputParser()13result = chain.invoke({"role": "风控专家", "question": "如何识别异常交易?"})14
15# ─── LCEL 关键方法 ───16# chain.invoke() → 单次调用17# chain.batch() → 批量(自动并发)18# chain.stream() → 流式输出19# chain.ainvoke() → 异步版本
3. RAG 检索增强生成
xxxxxxxxxx541from langchain_openai import ChatOpenAI, OpenAIEmbeddings2from langchain_core.prompts import ChatPromptTemplate3from langchain_core.output_parsers import StrOutputParser4from langchain_core.runnables import RunnablePassthrough5from langchain_text_splitters import RecursiveCharacterTextSplitter6from langchain_milvus import Milvus7
8# ─── 1. 文档分割 ───9text_splitter = RecursiveCharacterTextSplitter(10 chunk_size=500, # 每块 500 字符11 chunk_overlap=50, # 重叠 50 字符(保持语义连贯)12 separators=["\n\n", "\n", "。", ";", ",", " ", ""]13)14
15# ─── 2. 向量存储 ───16# 向量化模型17embeddings = OpenAIEmbeddings(model="text-embedding-3-small")18# 向量存储库19vectorstore = Milvus(20 embedding_function=embeddings,21 connection_args={"host": "localhost", "port": "19530"},22 collection_name="risk_control_docs",23 index_params={"metric_type": "COSINE", "index_type": "IVF_FLAT", "params": {"nlist": 1024}}24)25
26# ─── 3. RAG 链 ───27# 获取检索器28retriever = vectorstore.as_retriever(search_kwargs={"k": 4}) 29
30# 检索词模板31template = """基于以下参考文档回答。如果找不到答案,明确说"不知道",不要编造。32
33参考文档:34{context}35
36用户问题:{question}37回答:"""38
39prompt = ChatPromptTemplate.from_template(template)40
41# 用于拼接召回的文本42def format_docs(docs):43 return "\n\n".join(doc.page_content for doc in docs)44
45# RAG链:拼接检索器和用户问题->生成提示词->大模型->获取输出46rag_chain = (47 {"context": retriever | format_docs, "question": RunnablePassthrough()}48 | prompt49 | llm50 | StrOutputParser()51)52
53# 调用54answer = rag_chain.invoke("什么是反洗钱的三道防线?")
4. Tool Calling(工具调用)
xxxxxxxxxx211from langchain_core.tools import tool2from langchain_openai import ChatOpenAI3
4# ─── 定义工具(docstring 自动作为工具描述给 LLM 理解) ───5def search_risk_rules(keyword: str) -> str:7 """搜索风控规则库,输入关键词返回匹配的规则"""8 return f"找到3条关于'{keyword}'的规则:\n1. 大额交易监控\n2. 异常时段交易\n3. 频繁转账预警"9
10def calculate_risk_score(amount: float, frequency: int) -> int:12 """计算交易风险评分(0-100),输入金额和频次"""13 return min(100, int(amount / 1000 + frequency * 10))14
15# ─── 绑定工具到模型 ───16llm = ChatOpenAI(model="gpt-4o")17llm_with_tools = llm.bind_tools([search_risk_rules, calculate_risk_score])18
19# 模型自动判断是否调用工具20response = llm_with_tools.invoke("帮我查大额交易规则")21print(response.tool_calls) # 查看模型决定调用的工具
第四节 LangGraph 多 Agent 编排
LangGraph 是构建有状态、多角色 Agent 的框架,核心是 StateGraph。
1. 核心三要素
- State:图中流转的共享状态,用 TypedDict 定义
- Nodes:处理状态的函数,输入 State 返回更新
- Edges:节点间的流转关系(普通边 / 条件边)
2. StateGraph 构建
xxxxxxxxxx531from typing import TypedDict, Literal, Annotated2from langgraph.graph import StateGraph, END3from langgraph.graph.message import add_messages4from langchain_openai import ChatOpenAI5
6# ─── State 定义 ───7class RiskState(TypedDict):8 messages: Annotated[list, add_messages]9 transaction: str10 amount: float11 risk_score: int12 decision: str13 reason: str14
15# ─── 节点定义 ───16def assess_risk(state: RiskState) -> RiskState:17 amount = state["amount"]18 if amount > 500000:19 state["risk_score"] = 9020 state["reason"] = "大额交易"21 elif amount > 100000:22 state["risk_score"] = 6023 state["reason"] = "较大额交易"24 else:25 state["risk_score"] = 2026 state["reason"] = "正常交易"27 return state28
29def llm_judge(state: RiskState) -> RiskState:30 llm = ChatOpenAI(model="gpt-4o", temperature=0)31 prompt = f"""交易金额:{state['amount']},风险评分:{state['risk_score']}32决策:通过 / 人工审核 / 拒绝"""33 response = llm.invoke(prompt)34 # 实际需解析 LLM 输出,此处简化35 if state["risk_score"] >= 80:36 state["decision"] = "拒绝"37 elif state["risk_score"] >= 50:38 state["decision"] = "人工审核"39 else:40 state["decision"] = "通过"41 return state42
43# ─── 构建 Graph ───44graph = StateGraph(RiskState)45graph.add_node("assess", assess_risk)46graph.add_node("judge", llm_judge)47graph.add_edge("assess", "judge")48graph.add_edge("judge", END)49graph.set_entry_point("assess")50
51app = graph.compile()52result = app.invoke({"transaction": "向境外转账600000元", "amount": 600000, "risk_score": 0, "decision": "", "reason": ""})53print(f"决策:{result['decision']}")
3. 条件边(多分支路由)
xxxxxxxxxx261# ─── 路由函数 ───2def route_by_risk(state: RiskState) -> Literal["auto_pass", "manual_review", "auto_reject"]:3 score = state["risk_score"]4 if score >= 80:5 return "auto_reject"6 elif score >= 50:7 return "manual_review"8 return "auto_pass"9
10# ─── 条件边 ───11graph = StateGraph(RiskState)12graph.add_node("assess", assess_risk)13graph.add_node("auto_pass", lambda s: {**s, "decision": "通过"})14graph.add_node("manual_review", lambda s: {**s, "decision": "人工审核"})15graph.add_node("auto_reject", lambda s: {**s, "decision": "拒绝"})16
17graph.add_conditional_edges(18 "assess",19 route_by_risk,20 {"auto_pass": "auto_pass", "manual_review": "manual_review", "auto_reject": "auto_reject"}21)22graph.add_edge("auto_pass", END)23graph.add_edge("manual_review", END)24graph.add_edge("auto_reject", END)25graph.set_entry_point("assess")26app = graph.compile()
4. ReAct Agent(推理 + 行动循环)
xxxxxxxxxx191from langgraph.prebuilt import create_react_agent2
3def query_risk_db(rule_name: str) -> str:5 """查询风控规则库"""6 rules = {"大额交易": "单笔超50万需审核", "频繁转账": "1h内5笔以上需冻结"}7 return rules.get(rule_name, "未找到")8
9def log_alert(tx_id: str, level: str) -> str:11 """记录风控告警"""12 return f"已记录:{tx_id},等级{level}"13
14llm = ChatOpenAI(model="gpt-4o")15agent = create_react_agent(llm, [query_risk_db, log_alert])16
17result = agent.invoke({18 "messages": [("user", "交易TX20240501金额80万,查规则并记录告警")]19})
5. 多 Agent 协作(Supervisor 模式)
xxxxxxxxxx191from langgraph_supervisor import create_supervisor2
3# 子 Agent4risk_agent = create_react_agent(ChatOpenAI(model="gpt-4o"), [query_risk_db, log_alert])5kb_agent = create_react_agent(ChatOpenAI(model="gpt-4o"), [search_knowledge_base])6
7# Supervisor 调度8supervisor = create_supervisor(9 agents=[risk_agent, kb_agent],10 model=ChatOpenAI(model="gpt-4o"),11 prompt="""你是风控智能助手的主管。根据用户请求分派:12 - risk_agent:风控规则查询、告警13 - kb_agent:知识库搜索、文档问答14 """15)16
17result = supervisor.invoke({18 "messages": [("user", "查反洗钱政策,检查这笔50万交易是否需要告警")]19})
6. Human-in-the-Loop(人工审核断点)
xxxxxxxxxx181from langgraph.types import interrupt2
3# 方式一:在节点函数中主动中断4def operation_node(state: AgentState) -> AgentState:5 """需要人工审批的操作节点"""6 if state["pending_approval"]:7 # 主动中断,抛出暂停信号,把提示文案传给前端/调用方8 approval = interrupt(f"等待审批:{state['tool_calls']}")9 if approval != "approved":10 state["final_response"] = "操作已被拒绝"11 return state12 # 审批通过才走到这里13 state["final_response"] = "操作已执行"14 return state15
16# 方式二:设置在进入 operation 节点之前自动中断17graph.add_node("operation", operation_node)18app = graph.compile(checkpointer=checkpointer, interrupt_before=["operation"])
7. 状态持久化(Checkpointing)
xxxxxxxxxx171from langgraph.checkpoint.memory import MemorySaver2# 生产环境:from langgraph.checkpoint.sqlite import SqliteSaver3
4# 创建checkpointer对象并配置上去5checkpointer = MemorySaver()6app = graph.compile(checkpointer=checkpointer)7
8# 会话ID配置9config = {"configurable": {"thread_id": "session-001"}}10
11# 多次调用,状态自动累积12app.invoke({"amount": 500000}, config)13app.invoke({"amount": 200000}, config) # 同一会话,可访问历史14
15# 查看历史状态16state = app.get_state(config)17print(state.values)
第五节 Milvus 向量数据库
1. 基本概念
Milvus 是云原生向量数据库,专为十亿级向量相似度搜索设计,是 RAG 应用的核心基础设施。
对比 FAISS / Chroma:FAISS 是内存库(进程挂了数据丢),Milvus 支持持久化和集群。
xxxxxxxxxx21# 安装2pip install pymilvus langchain-milvus
2. Schema 与 Collection
xxxxxxxxxx251from pymilvus import connections, Collection, CollectionSchema, FieldSchema, DataType, utility2
3# 连接4connections.connect(host="localhost", port="19530")5
6# 字段定义7id_field = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True)8vector_field = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1536)9content_field = FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=65535)10source_field = FieldSchema(name="source", dtype=DataType.VARCHAR, max_length=500)11
12# 表定义13schema = CollectionSchema(14 fields=[id_field, vector_field, content_field, source_field],15 description="风控知识库"16)17
18# 创建表19collection = Collection(name="risk_control_knowledge", schema=schema)20
21# 创建索引22collection.create_index(23 field_name="embedding",24 index_params={"metric_type": "COSINE", "index_type": "IVF_FLAT", "params": {"nlist": 1024}}25)
3. 向量搜索
xxxxxxxxxx191# 加载进内存(不执行load()直接 search 会报错,程序重启、新建集合后必须 load 一次)2collection.load()3
4# 向量搜索5results = collection.search(6 data=[query_vector], # 入参:【查询向量列表】,支持批量多个query7 anns_field="embedding", # 做向量检索的字段名(存Embedding的列)8 param={9 "metric_type": "COSINE", # 距离算法:余弦相似度,越大越相似10 "params": {"nprobe": 10} # IVF_FLAT索引超参:检索时遍历10个聚类桶11 },12 limit=3, # Top-K:返回相似度最高前3条13 output_fields=["content", "source"]# 额外取出非向量字段,不用再查数据库14)15
16# 解析返回结果17for hits in results: # 外层:对应data里每一个查询向量的结果18 for hit in hits: # 内层:单个query匹配到的top3文档19 print(f"相似度: {hit.score:.4f} | 内容: {hit.entity.get('content')[:100]}")
4. 混合搜索(标量过滤)
xxxxxxxxxx101# 先根据 expr 过滤元数据,再在过滤后的数据集里做向量相似度检索,实现「RAG 定向知识库召回」2results = collection.search(3 data=[query_vector],4 anns_field="embedding",5 param=search_params,6 limit=3,7 expr='source == "policy_v2.1"', # 只搜索特定来源8 output_fields=["content", "source"]9)10# expr 支持: source in [...], source like "pattern%"
5. LangChain 集成
xxxxxxxxxx221from langchain_milvus import Milvus2
3# 创建向量库4vectorstore = Milvus(5 embedding_function=OpenAIEmbeddings(model="text-embedding-3-small"),6 connection_args={"host": "localhost", "port": "19530"},7 collection_name="risk_knowledge_base",8 index_params={"metric_type": "COSINE", "index_type": "IVF_FLAT", "params": {"nlist": 1024}},9 auto_id=True10)11
12# 插入文档13vectorstore.add_documents(chunks)14
15# 搜索16results = vectorstore.similarity_search_with_score("大额交易报告流程", k=3)17
18# 转为检索器(接入 RAG 链)19retriever = vectorstore.as_retriever(20 search_type="mmr", # MMR 去重21 search_kwargs={"k": 4, "fetch_k": 20}22)
第六节 MCP 协议与工具封装
1. MCP 协议核心价值
MCP(Model Context Protocol)是标准化的 Agent 工具协议,核心优势:
- 标准化工具描述:统一的 JSON Schema 格式,LLM 不需要为每个工具适配不同格式
- 动态工具发现:
tools/list让 Agent 动态感知可用工具,无需硬编码 - 双向通信:支持
resources(数据资源)和prompts,不只是工具调用 - 传输层抽象:STDIO(进程间)和 HTTP+SSE(远程),同一套工具可本地/远程部署
vs Function Calling:Function Calling 只有单向调用,无资源订阅和动态发现。MCP = Function Calling 的超集 + 标准化协议层。
2. MCP Server 实现
xxxxxxxxxx941# mcp_server/risk_tools_server.py2from mcp.server import Server, NotificationOptions3from mcp.server.models import InitializationCapabilities4import mcp.server.stdio5import mcp.types as types6
7# 创建 MCP Server8server = Server("risk-control-tools")9
10# ─── 注册工具列表 ───11.list_tools()12async def list_tools() -> list[types.Tool]:13 return [14 types.Tool(15 name="query_position",16 description="查询客户持仓信息",17 inputSchema={18 "type": "object",19 "properties": {20 "customer_id": {"type": "string", "description": "客户ID"},21 "stock_code": {"type": "string", "description": "股票代码(可选)"}22 },23 "required": ["customer_id"]24 }25 ),26 types.Tool(27 name="query_market_snapshot",28 description="获取股票实时行情快照",29 inputSchema={30 "type": "object",31 "properties": {32 "stock_codes": {33 "type": "array",34 "items": {"type": "string"},35 "description": "股票代码列表"36 }37 },38 "required": ["stock_codes"]39 }40 ),41 types.Tool(42 name="query_risk_indicators",43 description="查询风控指标(资金流向、波动率等)",44 inputSchema={45 "type": "object",46 "properties": {47 "indicator_type": {"type": "string", "description": "指标类型:fund_flow/volatility/concentration"},48 "stock_code": {"type": "string", "description": "股票代码"},49 "date": {"type": "string", "description": "日期 YYYY-MM-DD(默认当日)"}50 },51 "required": ["indicator_type", "stock_code"]52 }53 )54 ]55
56# ─── 工具调用处理 ───57.call_tool()58async def call_tool(name: str, arguments: dict) -> list[types.TextContent]:59 if name == "query_position":60 customer_id = arguments["customer_id"]61 stock_code = arguments.get("stock_code")62 # 实际项目接入持仓系统 API63 result = f"客户{customer_id}持仓:{stock_code or '全部'}..."64 return [types.TextContent(type="text", text=result)]65
66 elif name == "query_market_snapshot":67 stock_codes = arguments["stock_codes"]68 # 实际项目接入行情系统 API69 result = f"行情快照({len(stock_codes)}只股票):..."70 return [types.TextContent(type="text", text=result)]71
72 elif name == "query_risk_indicators":73 # 实际项目接入风控系统 API74 result = f"风控指标:..."75 return [types.TextContent(type="text", text=result)]76
77 raise ValueError(f"未知工具: {name}")78
79# ─── 启动 Server ───80async def main():81 async with mcp.server.stdio.stdio_server() as (read_stream, write_stream):82 await server.run(83 read_stream,84 write_stream,85 InitializationCapabilities(86 sampling=types.SamplingCapability(),87 experimental={}88 ),89 NotificationOptions()90 )91
92if __name__ == "__main__":93 import asyncio94 asyncio.run(main())
3. LangGraph 集成 MCP 工具
xxxxxxxxxx301# agents/langgraph_mcp_integration.py2from langgraph.prebuilt import create_react_agent3from langchain_openai import ChatOpenAI4from langchain_mcp_adapters.client import MultiServerMCPClient5
6# ─── 连接 MCP Server ───7mcp_client = MultiServerMCPClient({8 "risk_tools": {9 "command": "python",10 "args": ["mcp_server/risk_tools_server.py"],11 "transport": "stdio"12 },13 "market_data": {14 "url": "http://market-mcp-server:8080/sse",15 "transport": "sse"16 }17})18
19# ─── 获取所有 MCP 工具 ───20tools = await mcp_client.get_tools()21# tools 自动包含 query_position, query_market_snapshot, query_risk_indicators22
23# ─── 创建 Agent ───24llm = ChatOpenAI(model="gpt-4o")25agent = create_react_agent(llm, tools)26
27# Agent 可以动态发现和使用所有 MCP 工具28result = await agent.ainvoke({29 "messages": [("user", "帮我查客户C10086的持仓和今天市场行情")]30})
4. MCP 工具注册中心
替代零散硬编码MultiServerMCPClient配置,中心化统一管理所有 MCP 服务配置、健康、限流、热更。
xxxxxxxxxx281# 生产环境:工具注册中心化,支持热加载、权限控制、速率限制2class MCPToolRegistry:3 """MCP 工具注册中心"""4 def __init__(self):5 self._tools = {} # tool_name → MCP server6 self._status = {} # tool_name → health status7 self._rate_limiter = {} # tool_name → token bucket8
9 def register(self, tool_name: str, server_config: dict):10 self._tools[tool_name] = server_config11
12 def get_available_tools(self) -> list:13 """返回当前可用的工具列表(排除挂掉的)"""14 return [name for name, status in self._status.items() if status == "healthy"]15
16 def check_health(self, tool_name: str) -> bool:17 """健康检查"""18 return self._status.get(tool_name) == "healthy"19
20 def reload(self, tool_name: str):21 """热加载工具(不重启 Agent)"""22 pass23 24# 注册远端SSE行情工具25registry.register("market_data", {26 "url": "http://market-mcp-server:8080/sse",27 "transport": "sse"28})
第七节 RAG 优化实战
1. 语义分块(Semantic Chunking)
传统固定大小的分块会割裂语义。语义分块根据内容相似度决定切分时机:
xxxxxxxxxx811from langchain_openai import OpenAIEmbeddings2import numpy as np3
4class SemanticChunker:5 """6 基于语义相似度的文档分割器7 原理:相邻句子向量余弦相似度低于阈值则切分片段,同时约束单块最大/最小字符长度,8 替代固定字符切割,保证拆分后每段语义完整,适配RAG知识库入库切片9 """10
11 def __init__(self, similarity_threshold=0.5, min_chunk=256, max_chunk=1024):12 """13 初始化语义切分器14 :param similarity_threshold: 分句切分阈值,相邻句子余弦相似度低于该值则截断分块15 :param min_chunk: 单个文本块最小字符长度,不足最小长度时,即使语义断裂也不切分16 :param max_chunk: 单个文本块最大字符长度,超上限强制截断,防止单块文本过长17 """18 self.threshold = similarity_threshold19 self.min_chunk = min_chunk20 self.max_chunk = max_chunk21 # 初始化OpenAI向量化模型,用于句子生成Embedding向量22 self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")23
24 def split(self, text: str) -> list[str]:25 """26 入口方法:对整篇长文本执行语义分块27 :param text: 原始完整文档字符串28 :return: 切分完成后的文本片段列表29 """30 # 第一步:按中文句号、感叹号、问号拆分单句31 sentences = self._split_sentences(text)32 # 批量对所有句子生成embedding向量33 embeddings = self.embeddings.embed_documents(sentences)34
35 chunks = [] # 最终存储所有切分好的文档块36 current_chunk = [sentences[0]] # 缓存正在拼接的当前句子组,初始装入第一句37
38 # 从第二个句子开始遍历对比相邻语义39 for i in range(1, len(sentences)):40 # 计算上一句与当前句的余弦相似度41 similarity = self._cosine_similarity(embeddings[i-1], embeddings[i])42 # 统计当前累计拼接文本总字符数43 current_len = sum(len(s) for s in current_chunk)44
45 # 条件1:语义差距大 + 当前长度达标最小阈值 → 切分46 if similarity < self.threshold and current_len >= self.min_chunk:47 chunks.append("".join(current_chunk))48 current_chunk = [sentences[i]]49 # 条件2:累计文本超过最大限制,强制切分,避免片段过大50 elif current_len >= self.max_chunk:51 chunks.append("".join(current_chunk))52 current_chunk = [sentences[i]]53 # 语义相近且长度未超限,继续追加句子到当前块54 else:55 current_chunk.append(sentences[i])56
57 # 遍历结束,把最后剩余未入列表的片段存入结果58 if current_chunk:59 chunks.append("".join(current_chunk))60 return chunks61
62 63 def _cosine_similarity(a, b):64 """65 静态方法:手动计算两个向量余弦相似度66 :param a: 上一句embedding数组67 :param b: 当前句embedding数组68 :return: 余弦相似度数值 [0~1],数值越高语义越相近69 """70 return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))71
72 73 def _split_sentences(text: str) -> list[str]:74 """75 静态方法:中文分句,以 。!?作为分隔符拆分句子76 :param text: 原始文档77 :return: 去除空值、补全句号的句子列表78 """79 import re80 # 正则切割,过滤空字符串,每个分句末尾补回句号81 return [s.strip() + "。" for s in re.split(r'[。!?]', text) if s.strip()]
2. 混合检索(Hybrid Search)
Dense(BGE-M3 语义)+ Sparse(BM25 关键词)+ RRF 融合 + Reranker 重排序
xxxxxxxxxx621from langchain_community.retrievers import BM25Retriever2from FlagEmbedding import FlagReranker3
4class HybridRetriever:5 """6 混合检索器:稠密向量检索(BGE-M3)+BM25稀疏关键词检索7 流程:两路召回 → RRF分数融合 → BGE-Reranker精排,提升RAG召回准确率8 """9
10 def __init__(self, vectorstore, documents, dense_weight=0.6):11 """12 初始化混合检索13 :param vectorstore: Milvus向量库实例,存储文档稠密向量,做语义召回14 :param documents: Document文档列表,用于构建BM25倒排索引15 :param dense_weight: 稠密向量结果权重,(1-dense_weight)为BM25权重,默认0.6偏向语义检索16 """17 self.vectorstore = vectorstore # Milvus稠密向量存储18 self.bm25 = BM25Retriever.from_documents(documents) # 基于文档构建BM25关键词检索器19 self.reranker = FlagReranker('BAAI/bge-reranker-v2-m3') # BGE精排模型,对候选文档二次打分排序20 self.dense_weight = dense_weight # 稠密向量RRF权重系数21 self.k = 60 # RRF(倒数排名融合)平滑常数,缓解排名靠前文档分值爆炸22
23 def search(self, query: str, top_k: int = 5, rerank_top_n: int = 20) -> list:24 """25 混合检索主逻辑26 :param query: 用户检索问题27 :param top_k: 最终返回topN文档数量28 :param rerank_top_n: 两路召回后参与重排的候选文档总数29 :return: 经过融合+精排后的Document列表30 """31 # 1、两路初筛:向量语义召回、BM25关键词召回,各自取出候选数量32 dense_results = self.vectorstore.similarity_search_with_score(query, k=rerank_top_n)33 bm25_results = self.bm25.invoke(query)34
35 # 2、RRF倒数排名融合:合并两路文档得分36 scores = {}37 # 遍历稠密向量召回结果,按排名计算加权RRF分值38 for rank, (doc, score) in enumerate(dense_results):39 # 用正文前200字符作为文档唯一标识,避免重复文档多次计分40 key = doc.page_content[:200]41 # RRF公式:weight/(rank+k),排名越靠前分值越高42 scores[key] = scores.get(key, 0) + self.dense_weight / (rank + self.k)43
44 # 遍历BM25关键词召回结果,截断至候选上限,叠加加权RRF分值45 for rank, doc in enumerate(bm25_results[:rerank_top_n]):46 key = doc.page_content[:200]47 scores[key] = scores.get(key, 0) + (1 - self.dense_weight) / (rank + self.k)48
49 # 按融合总分降序排序全部候选文档50 sorted_docs = sorted(scores.items(), key=lambda x: x[1], reverse=True)51
52 # 3、BGE-Reranker精细重排序53 # 截取融合排序后的前N份文档作为精排候选集54 candidates = [doc for doc, _ in sorted_docs[:rerank_top_n]]55 # 构造[查询,候选文本]输入对,送入重排模型打分56 pairs = [[query, doc] for doc in candidates]57 rerank_scores = self.reranker.compute_score(pairs)58
59 # 根据重排分数从高到低排序60 ranked = sorted(zip(candidates, rerank_scores), key=lambda x: x[1], reverse=True)61 # 截取最终需要的top_k文档返回62 return [doc for doc, score in ranked[:top_k]]
3. 召回率评估
xxxxxxxxxx401class RetrievalEvaluator:2 """3 检索效果评估器:计算Top-K召回率Recall@K4 指标含义:标准答案相关文档出现在检索返回topK列表中的样本占比,用来量化RAG知识库检索能力5 """6
7 def __init__(self, test_set: list[dict]):8 """9 :param test_set: 标注测试数据集,单条样例结构10 {"question": "大额交易定义?", "relevant_doc_ids": ["doc_001", "doc_003"]}11 question:测试查询问句12 relevant_doc_ids:该问题对应的标准答案文档ID列表(人工标注的相关文档)13 业务说明:测试集构建:从 500+ 文档中抽取 200 条问题,由 2 人独立标注 + 第三方仲裁,保证标注可信度14 """15 self.test_set = test_set16
17 def evaluate(self, retriever, k: int = 5) -> dict:18 """19 批量执行评估,输出Recall@K指标20 :param retriever: 任意检索器实例(HybridRetriever/原生Milvus检索器),必须实现search(question,top_k)方法21 :param k: 取检索结果前k条做召回判定,常用k=3/5/1022 :return: 评估结果字典:topK值、召回率、总样本数、命中样本数23 """24 correct = 0 # 命中样本计数器:相关文档至少命中1篇即算该样本召回成功25 for item in self.test_set:26 # 调用检索器,返回top-k候选文档27 results = retriever.search(item["question"], top_k=k)28 # 遍历检索结果,提取文档ID存入集合(集合方便求交集)29 retrieved_ids = {self._get_doc_id(doc) for doc in results}30 # 交集非空:代表至少一篇相关文档被召回,命中+131 if retrieved_ids & set(item["relevant_doc_ids"]):32 correct += 133
34 # Recall@K = 命中样本数 / 总测试样本数35 recall = correct / len(self.test_set)36 return {"top_k": k, "recall": recall, "total": len(self.test_set), "hits": correct}37
38 def _get_doc_id(self, doc):39 """从Document的metadata中取出文档唯一ID,需要入库时预先存入doc_id元数据"""40 return doc.metadata["doc_id"]
第八节 Agent 评估与可观测性
1. 关键指标体系
| 指标类型 | 指标 | 目标值 |
|---|---|---|
| 性能 | 首 Token 延迟 | < 2s |
| 性能 | 端到端响应时间 | < 10s |
| 质量 | Top-K 召回率 | > 90% |
| 质量 | 回答准确率(用户反馈) | > 85% |
| 稳定性 | 幻觉率 | < 3% |
| 稳定性 | LLM 调用成功率 | > 99.5% |
| 成本 | 日均 Token 消耗 | 监控异常增长 |
2. Langfuse 集成(LLM 调用追踪)
xxxxxxxxxx201# 环境变量配置2# LANGFUSE_PUBLIC_KEY=pk-xxx3# LANGFUSE_SECRET_KEY=sk-xxx4# LANGFUSE_HOST=https://cloud.langfuse.com5
6from langfuse.langchain import CallbackHandler7
8# LangChain / LangGraph 自动追踪9langfuse_handler = CallbackHandler()10
11# 每次调用传入 handler12result = agent.invoke(13 {"messages": [("user", "查询大额交易规则")]},14 config={"callbacks": [langfuse_handler]}15)16
17# Langfuse Dashboard 可查看:18# - 每次 LLM 调用的 trace(输入、输出、token 用量、耗时)19# - Agent 决策链路(哪个节点→哪个工具→哪个 LLM)20# - Token 成本统计
3. 幻觉检测与降低策略
xxxxxxxxxx211class HallucinationDetector:2 """幻觉检测:检查回复中引用的规则/指标是否真实存在于知识库"""3
4 def __init__(self, vectorstore):5 self.vectorstore = vectorstore6
7 def check(self, response: str) -> tuple[bool, list]:8 """返回 (是否有幻觉, 可疑片段列表)"""9 # 提取回复中引用的"规则编号""指标名称"等实体10 import re11 rule_refs = re.findall(r'《([^》]+)》', response)12 indicator_refs = re.findall(r'"(指标|规则)[::](\w+)"', response)13
14 suspicious = []15 for ref in rule_refs + [i[1] for i in indicator_refs]:16 # 检查该引用是否真实存在于知识库17 results = self.vectorstore.similarity_search(ref, k=1)18 if not results or results[0].metadata.get("score", 0) < 0.7:19 suspicious.append(ref)20
21 return len(suspicious) == 0, suspicious降低幻觉的 5 个策略:
- RAG 增强:知识型回答必须先检索,强制引用来源
- 工具锁定:查询类问题不走纯生成,必须走工具调用 → 用工具返回数据回答
- System Prompt:"如果你不知道,就说不知道,不要编造"
- Few-shot 示例:教模型如何说"我不确定"
- 人工兜底:事务类操作经人工审批
4. 监控 Dashboard(自定义埋点)
xxxxxxxxxx411# 关键指标采集 → Kafka → Flink 聚合 → InfluxDB → Grafana2import time3from dataclasses import dataclass, field4from datetime import datetime5
6class AgentMetrics:8 """Agent 运行指标采集器"""9 total_calls: int = 010 success_calls: int = 011 total_latency_ms: float = 012 hallucination_count: int = 013 tool_call_failures: int = 014 tokens_used: int = 015 events: list = field(default_factory=list)16
17 def record_call(self, success: bool, latency_ms: float, tokens: int,18 hallucination: bool = False, tool_error: bool = False):19 self.total_calls += 120 if success:21 self.success_calls += 122 self.total_latency_ms += latency_ms23 self.tokens_used += tokens24 if hallucination:25 self.hallucination_count += 126 if tool_error:27 self.tool_call_failures += 128
29 def report(self) -> dict:30 return {31 "success_rate": self.success_calls / max(self.total_calls, 1),32 "avg_latency_ms": self.total_latency_ms / max(self.total_calls, 1),33 "hallucination_rate": self.hallucination_count / max(self.total_calls, 1),34 "tool_error_rate": self.tool_call_failures / max(self.total_calls, 1),35 "total_tokens": self.tokens_used36 }37
38# 告警规则39# - 幻觉率 > 5% → 触发告警40# - 响应超时率 > 1% → 触发告警41# - Tool Call 失败率 > 3% → 触发告警
第九节 容错与降级策略
1. Tool Calling 多层容错
xxxxxxxxxx591import asyncio2from tenacity import retry, stop_after_attempt, wait_exponential3from enum import Enum4
5class ToolStatus(Enum):6 HEALTHY = "healthy"7 DEGRADED = "degraded"8 CIRCUIT_OPEN = "circuit_open"9
10class ResilientToolExecutor:11 """带熔断、重试、降级的工具执行器"""12
13 def __init__(self, timeout=3.0, max_failures=5, circuit_timeout=30):14 self.timeout = timeout15 self.max_failures = max_failures16 self.circuit_timeout = circuit_timeout17 self._failures = {} # tool_name → failure count18 self._status = {} # tool_name → ToolStatus19 self._circuit_open_at = {} # tool_name → timestamp20
21 (stop=stop_after_attempt(2), wait=wait_exponential(multiplier=1, min=0.5, max=5))22 async def execute(self, tool_name: str, tool_func, *args, **kwargs) -> str:23 status = self._status.get(tool_name, ToolStatus.HEALTHY)24
25 # 熔断检查26 if status == ToolStatus.CIRCUIT_OPEN:27 opened_at = self._circuit_open_at.get(tool_name, 0)28 if time.time() - opened_at < self.circuit_timeout:29 return self._fallback(tool_name, "服务熔断中,使用降级响应")30 # 半开探测31 self._status[tool_name] = ToolStatus.DEGRADED32
33 # 超时保护34 try:35 result = await asyncio.wait_for(36 tool_func(*args, **kwargs),37 timeout=self.timeout38 )39 self._on_success(tool_name)40 return result41 except asyncio.TimeoutError:42 return self._on_failure(tool_name, "工具调用超时")43 except Exception as e:44 return self._on_failure(tool_name, str(e))45
46 def _on_success(self, tool_name: str):47 self._failures[tool_name] = 048 self._status[tool_name] = ToolStatus.HEALTHY49
50 def _on_failure(self, tool_name: str, error_msg: str) -> str:51 self._failures[tool_name] = self._failures.get(tool_name, 0) + 152 if self._failures[tool_name] >= self.max_failures:53 self._status[tool_name] = ToolStatus.CIRCUIT_OPEN54 self._circuit_open_at[tool_name] = time.time()55 return self._fallback(tool_name, error_msg)56
57 def _fallback(self, tool_name: str, reason: str) -> str:58 """降级策略:返回缓存数据或告知用户"""59 return f"[工具{tool_name}暂时不可用:{reason}] 当前仅支持知识问答模式"
2. Agent 层降级
xxxxxxxxxx301class DegradableAgent:2 """支持降级的 Agent 包装器"""3
4 def __init__(self, primary_agent, fallback_agent=None):5 self.primary = primary_agent6 self.fallback = fallback_agent7 self.tool_executor = ResilientToolExecutor()8
9 async def invoke(self, state: dict) -> dict:10 try:11 return await self.primary.ainvoke(state)12 except Exception as e:13 logger.warning(f"Agent 主流程失败: {e},切换到降级模式")14
15 # 降级策略:16 # 1. 尝试换工具/换参数17 # 2. 所有工具都失败 → 纯对话模式18 # 3. 关键数据用本地缓存(标注"数据可能延迟")19
20 return {21 "messages": state["messages"] + [22 ("assistant", "当前系统繁忙,仅支持知识问答。您的问题已记录,稍后为您处理。")23 ],24 "degraded": True25 }26
27 def get_available_tools(self) -> list:28 """只返回当前健康的工具列表"""29 return [name for name, status in self.tool_executor._status.items()30 if status != ToolStatus.CIRCUIT_OPEN]
3. System Prompt 工具状态注入
xxxxxxxxxx151def build_dynamic_system_prompt(available_tools: list, degraded_tools: list) -> str:2 """动态生成 System Prompt,告知 Agent 当前工具可用性"""3 tools_desc = "\n".join(f"- {t}: 可用" for t in available_tools)4 degraded_desc = "\n".join(f"- {t}: 不可用,请告知用户" for t in degraded_tools)5
6 return f"""你是风控智能助手。7
8当前可用工具:9{tools_desc}10
11当前不可用工具(不要尝试调用):12{degraded_desc or "无"}13
14注意:如果用户需要的功能对应的工具不可用,请明确告知用户当前无法处理,15建议替代方案(如知识问答),不要假装执行了操作。"""
第十节 风控智能助手项目实战
1. 项目架构
xxxxxxxxxx201┌─────────────────────────────────────────────────────┐2│ FastAPI │3│ /chat /stream /health │4├─────────────────────────────────────────────────────┤5│ LangGraph 层 │6│ ┌──────────┐ ┌──────────┐ ┌───────────────────┐ │7│ │ 路由Agent │→│ 查询Agent │→│ 操作Agent(审批) │ │8│ │ 意图识别 │ │ 工具调用 │ │ Human-in-the-Loop │ │9│ └──────────┘ └──────────┘ └───────────────────┘ │10├──────────────┬──────────────────┬───────────────────┤11│ LLM 服务 │ MCP 工具层 │ 向量检索 │12│ GPT-4o / │ 委托/行情/持仓/ │ BGE-M3 + Milvus │13│ DeepSeek │ 指标封装 │ + BM25 │14├──────────────┴──────────────────┴───────────────────┤15│ 数据 / 存储层 │16│ TDSQL(MySQL) + Redis + Kafka + MinIO │17├─────────────────────────────────────────────────────┤18│ 可观测性 │19│ Langfuse (trace) + Grafana (metrics) + ELK (log) │20└─────────────────────────────────────────────────────┘
2. Agent Graph 设计
xxxxxxxxxx61用户输入 → 路由Agent(意图识别)2├── 查询Agent(自主闭环)→ MCP工具调用 → 汇总3├── 操作Agent(需审批)→ Human-in-the-Loop → MCP工具调用 → 汇总4└── 报告Agent(多步编排)→ RAG检索 + MCP工具调用 → 汇总5↓6汇总Agent(整合结果,生成自然语言回复)
xxxxxxxxxx621# agents/graph.py2from typing import TypedDict, Annotated, Literal, List3from langgraph.graph import StateGraph, END4from langgraph.graph.message import add_messages5from langgraph.checkpoint.sqlite import SqliteSaver6from langgraph.prebuilt import create_react_agent7from langchain_openai import ChatOpenAI8
9# ─── State(完整版) ───10class AgentState(TypedDict):11 messages: Annotated[list, add_messages] # 对话历史12 intent: str # 意图分类13 context: list # RAG 检索到的文档14 tool_calls: list # 待执行的工具调用15 pending_approval: bool # 是否需要人工审核16 final_response: str # 最终回复17
18# ─── 意图分类路由 ───19def classify_intent(state: AgentState) -> AgentState:20 last_msg = state["messages"][-1].content21 if any(kw in last_msg for kw in ["查询", "行情", "持仓", "指标"]):22 state["intent"] = "query"23 elif any(kw in last_msg for kw in ["调整", "修改", "发送", "通知", "执行"]):24 state["intent"] = "operation"25 elif any(kw in last_msg for kw in ["报告", "分析", "总结"]):26 state["intent"] = "report"27 else:28 state["intent"] = "knowledge"29 return state30
31def route_by_intent(state: AgentState) -> Literal["query", "operation", "report", "knowledge"]:32 return state["intent"]33
34# ─── 构建完整 Graph ───35def build_risk_assistant_graph(mcp_tools: list):36 llm = ChatOpenAI(model="gpt-4o", temperature=0)37
38 # 子 Agent39 query_agent = create_react_agent(llm, mcp_tools) # 查询 Agent:调用 MCP 工具40 kb_agent = create_react_agent(llm, [search_kb]) # 知识库 Agent:RAG 检索41
42 graph = StateGraph(AgentState)43 graph.add_node("classify", classify_intent)44 graph.add_node("query_agent", query_agent)45 graph.add_node("operation_agent", operation_with_approval)46 graph.add_node("report_agent", report_orchestrator)47 graph.add_node("kb_agent", kb_agent)48
49 graph.add_conditional_edges("classify", route_by_intent, {50 "query": "query_agent",51 "operation": "operation_agent",52 "report": "report_agent",53 "knowledge": "kb_agent"54 })55
56 for node in ["query_agent", "operation_agent", "report_agent", "kb_agent"]:57 graph.add_edge(node, END)58
59 graph.set_entry_point("classify")60
61 checkpointer = SqliteSaver.from_conn_string("risk_agent_checkpoints.db")62 return graph.compile(checkpointer=checkpointer)
3. FastAPI 服务层
xxxxxxxxxx581# api/main.py2from fastapi import FastAPI, HTTPException3from fastapi.middleware.cors import CORSMiddleware4from pydantic import BaseModel, Field5import uuid6import uvicorn7
8api = FastAPI(title="风控智能助手 API", version="2.0.0")9api.add_middleware(CORSMiddleware, allow_origins=["*"], allow_methods=["*"], allow_headers=["*"])10
11class ChatRequest(BaseModel):12 message: str = Field(..., description="用户输入")13 session_id: str = Field(default_factory=lambda: str(uuid.uuid4()))14
15class ChatResponse(BaseModel):16 answer: str17 session_id: str18 tool_calls: list = []19
20.post("/chat", response_model=ChatResponse)21async def chat(request: ChatRequest):22 try:23 result = await agent_app.ainvoke(24 {"messages": [("user", request.message)]},25 config={"configurable": {"thread_id": request.session_id}}26 )27 return ChatResponse(28 answer=result["messages"][-1].content,29 session_id=request.session_id30 )31 except Exception as e:32 logger.error(f"对话失败: {e}", exc_info=True)33 raise HTTPException(status_code=500, detail=str(e))34
35# ─── 流式接口 ───36.post("/chat/stream")37async def chat_stream(request: ChatRequest):38 from fastapi.responses import StreamingResponse39
40 async def generate():41 async for event in agent_app.astream(42 {"messages": [("user", request.message)]},43 config={"configurable": {"thread_id": request.session_id}},44 stream_mode="values"45 ):46 if "messages" in event:47 latest = event["messages"][-1]48 if hasattr(latest, 'content'):49 yield f"data: {latest.content}\n\n"50
51 return StreamingResponse(generate(), media_type="text/event-stream")52
53.get("/health")54async def health():55 return {"status": "ok", "service": "风控智能助手"}56
57if __name__ == "__main__":58 uvicorn.run(api, host="0.0.0.0", port=8000)
4. 配置管理
xxxxxxxxxx291# config/settings.py2from pydantic_settings import BaseSettings3
4class Settings(BaseSettings):5 # LLM6 openai_api_key: str7 openai_base_url: str = "https://api.openai.com/v1"8 default_model: str = "gpt-4o"9 deepseek_api_key: str = ""10
11 # Milvus12 milvus_host: str = "localhost"13 milvus_port: int = 1953014 milvus_collection: str = "risk_knowledge"15
16 # Database17 db_url: str = "mysql+pymysql://user:pass@localhost/risk_control"18
19 # Observability20 langfuse_public_key: str = ""21 langfuse_secret_key: str = ""22 langfuse_host: str = "https://cloud.langfuse.com"23
24 # MCP25 mcp_servers: dict = {}26
27 model_config = {"env_file": ".env", "env_file_encoding": "utf-8"}28
29settings = Settings()
5. 项目目录结构
xxxxxxxxxx281risk_control_agent/2├── config/3│ └── settings.py # pydantic-settings 配置4├── agents/5│ ├── graph.py # LangGraph Agent 图6│ ├── supervisor.py # Supervisor 调度7│ └── routing.py # 意图分类 + 路由8├── tools/9│ ├── mcp_client.py # MCP 客户端封装10│ └── risk_tools.py # 风控工具(@tool)11├── mcp_server/12│ └── risk_tools_server.py # MCP Server 实现13├── knowledge_base/14│ ├── hybrid_retriever.py # BGE-M3 + BM25 混合检索15│ ├── semantic_chunker.py # 语义分块16│ ├── vectorstore.py # Milvus 操作封装17│ └── reranker.py # BGE-Reranker 重排序18├── evaluation/19│ ├── metrics.py # 指标采集(召回率、幻觉率)20│ └── test_set.py # 测试集管理21├── api/22│ └── main.py # FastAPI 服务23├── resilience/24│ ├── circuit_breaker.py # 熔断器25│ └── fallback.py # 降级策略26├── main.py27├── requirements.txt28└── .env
第十一节 企业级工程实践
1. LLM 调用安全处理
xxxxxxxxxx191import time2from openai import OpenAI, RateLimitError, APIError3from tenacity import retry, stop_after_attempt, wait_exponential4
5(6 stop=stop_after_attempt(3),7 wait=wait_exponential(multiplier=1, min=1, max=10),8 retry=RetryErrorFilter9)10def safe_llm_call(messages: list, model: str = "gpt-4o") -> str:11 """带指数退避的 LLM 安全调用"""12 client = OpenAI()13 response = client.chat.completions.create(14 model=model,15 messages=messages,16 temperature=0,17 timeout=3018 )19 return response.choices[0].message.content
2. 日志系统
xxxxxxxxxx311import logging2
3def setup_logger(name: str, level: str = "INFO") -> logging.Logger:4 logger = logging.getLogger(name)5 logger.setLevel(getattr(logging, level))6 handler = logging.StreamHandler()7 handler.setFormatter(logging.Formatter(8 '%(asctime)s [%(levelname)s] %(name)s: %(message)s',9 datefmt='%Y-%m-%d %H:%M:%S'10 ))11 logger.addHandler(handler)12 return logger13
14logger = setup_logger("risk_agent")15
16# ─── LangChain 回调日志 ───17from langchain_core.callbacks import BaseCallbackHandler18
19class AgentLoggingCallback(BaseCallbackHandler):20 def on_llm_start(self, serialized, prompts, **kwargs):21 logger.info(f"LLM调用开始,prompt长度: {len(str(prompts))}")22
23 def on_llm_end(self, response, **kwargs):24 tokens = response.llm_output.get("token_usage", {})25 logger.info(f"LLM调用完成,用量: {tokens}")26
27 def on_tool_start(self, serialized, input_str, **kwargs):28 logger.info(f"工具调用: {serialized['name']}({input_str})")29
30 def on_tool_error(self, error, **kwargs):31 logger.error(f"工具调用失败: {error}")
3. 测试策略
xxxxxxxxxx261# ─── 单元测试(pytest) ───2def test_assess_risk_high_amount():3 from agents.graph import assess_risk4 state = {"amount": 600000, "risk_score": 0, "decision": "", "reason": ""}5 result = assess_risk(state)6 assert result["risk_score"] >= 807 assert len(result["reason"]) > 08
9def test_route_by_risk_high():10 from agents.graph import route_by_risk11 assert route_by_risk({"risk_score": 90}) == "auto_reject"12
13# ─── API 集成测试 ───14from fastapi.testclient import TestClient15from api.main import api16
17client = TestClient(api)18
19def test_chat_endpoint():20 response = client.post("/chat", json={"message": "查询大额交易规则"})21 assert response.status_code == 20022 assert "answer" in response.json()23
24def test_health_endpoint():25 response = client.get("/health")26 assert response.json()["status"] == "ok"