第02篇_开发工具
第01章_操作系统
第一节 Linux命令
1. Linux系统简介
1) 什么是Linux?
Linux是一种开源的、基于Unix的操作系统,广泛应用于服务器、嵌入式系统和桌面等领域,以稳定性、安全性和可定制性著称。
常见的发行版包括:CentOS/RRHEL(企业级/商业企业级)、Ubuntu(适合新手和桌面)、Debian(稳定可靠)等。
2) 设置环境变量
x1# 临时设置2# 可用 echo $MY_VAR 查看设置的变量,下同3export MY_VAR=value 4set MY_VAR=value5
6# 系统级永久配置7vim /etc/profile # 推荐,在登录Shell时加载,用于设置全局的环境变量,通常会一并加载 /etc/profile.d/ 目录8vim /etc/bashrc # 新开窗口时加载,用于设置每个终端会话的别名、函数和命令提示符等9ll /etc/profile.d/ # 包含多个脚本文件,每个脚本可以设置特定的环境变量10vim /etc/environment # 用于设置全局环境变量,键值对形式11
12# 用户级永久配置13vim ~/.profile # 推荐,用户级配置14vim ~/.bash_profile # 适用于bash shell,在登录Shell时加载,通常包含对 ~/.bashrc 的调用15vim ~/.bashrc # 适用于bash shell,新开窗口时加载16vim ~/.zshrc # 适用于zsh shell17
18# 使配置文件生效19source ~/.bashrc 20
21# 特殊环境变量:PATH=可执行文件查找目录22export PATH=$PATH:/new/path 23
24# 特殊环境变量:LD_LIBRARY_PATH=动态库加载目录25export LD_LIBRARY_PATH=/path/to/mylib:$LD_LIBRARY_PATH26
27# Java环境变量配置28export JAVA_HOME=/usr/lib/jvm/jdk-17-oracle-x6429export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar30export PATH=$PATH:$JAVA_HOME/bin31
3) 设置开机启动项
在Linux系统中,设置程序或服务在开机时自动启动有多种方法,具体取决于系统的初始化系统(如systemd、init等)。
161# 使用 systemd 服务(推荐方式)2vim /etc/systemd/system/myapp.service # 创建服务单元文件(详情见下文)3sudo systemctl enable myapp.service # 启用服务4sudo systemctl start myapp.service # 启动服务5sudo systemctl status myapp.service # 检查服务状态6
7# 使用/etc/rc.local8vim /etc/rc.local # 添加开机执行命令,如:/usr/local/nginx/sbin/nginx &9chmod +x /etc/rc.local # 给启动脚本授权10systemctl enable rc-local # 启用rc-local服务11systemctl start rc-local # 启动rc-local服务12
13# 其它方式(不推荐)14vim /etc/init.d/myapp # 使用init脚本方式(适用于旧系统)15@reboot /path/to/your/application # 使用 @reboot Cron 作业方式16
systemd 的服务单元文件示例如下:
121[Unit]2Description=My Application Service # 这是服务的描述3After=network.target # 指定该服务在网络服务启动后启动4
5[Service]6ExecStart=/path/to/your/application # 指定启动程序的路径7Restart=always # 设置服务在失败时总是自动重启8User=yourusername # 指定以哪个用户身份运行服务9
10[Install]11WantedBy=multi-user.target # 指定该服务在多用户目标启动时被启用12
4) 源码编译安装
171# 1. 下载源码包并解压(校验包完整性):2wget https://www.python.org/ftp/python/3.7.7/Python-3.7.7.tgz3tar -zxvf Python-3.7.7.tgz4 5# 2. 进入源码目录,查看 README 和 INSTALL 文件:6cat Python-3.7.7/README.rst7
8# 3. 执行./configure 命令,生成 Makefile 文件:9./configure --prefix=/usr/local/Python10
11# 4. 执行 Make 命令进行编译:12make/make clean13
14# 5. 执行 make install 命令进行软件的安装:15# 默认的安装路径为/usr/local/,相应的配置文件位置为/usr/local/etc 或/usr/local/***/etc16make install17
2. 电源/登录
shutdown-关机或重启
91[DESC]2 关闭计算机,使用权限是超级用户。3 4[EXAMPLE]5 ● shutdown -h now # 立即关机6 ● shutdown -r now # 立即重启7 ● shutdown -h +5 # 5分钟后关机,并且会向所有登录用户发送警告信息8 ● shutdown -r +5 # 5分钟后重启,并且会向所有登录用户发送警告信息9 ● shutdown -c # 取消已计划的关机或重启
halt-关机
51[DESC]2 关闭系统,使用权限是超级用户。3
4[EXAMPLE]5 ● halt -p # 快速关机
reboot-重启
51[DESC]2 重新启动计算机,使用权限是系统管理者。3 4[EXAMPLE]5 ● reboot # 正常重启系统(推荐)。安全地关闭所有服务和进程,然后重新启动系统。
login-登录
21[DESC]2 以用户名和用户密码登录操作系统,也可以用于切换用户或进行远程登录。
logout-登出(注销)
21[DESC]2 登出系统,相当于注销。它的权限是所有用户。使用 logout 的前提是当前 shell 是登录 shell 才可以。
last-查看登录情况
171[DESC]2 显示近期用户或终端的登录情况,使用权限是所有用户。3 4[OPTIONS]5 ● -n:指定输出记录的条数。6 ● -x:显示系统关闭、用户登录和退出的历史。7
8[EXAMPLE]9 ● last # 显示所有用户的最近登录记录10 ● last john # 显示用户 john 的登录记录11 ● last -n 10 # 只显示最近的 10 条登录记录12 ● last -x # 显示系统关机、重启以及用户登录和退出的记录13
14[root@VM-20-5-centos ~]# last15root pts/0 163.125.147.195 Mon Apr 28 20:32 still logged in16root pts/0 163.125.147.195 Mon Apr 28 20:30 - 20:31 (00:00)17root pts/0 163.125.147.195 Mon Apr 28 20:12 - 20:29 (00:17)
w-查看登录用户
191[DESC]2 显示当前登录到系统的用户及其活动信息。3
4[EXAMPLE]5 ● w # 显示所有登录用户的详细信息6 7[root@VM-20-5-centos ~]# w8 22:00:59 up 54 days, 10:45, 2 users, load average: 0.00, 0.07, 0.089USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT10root pts/0 163.125.147.195 20:32 3.00s 0.21s 0.00s w11root pts/1 163.125.147.195 21:19 37:31 0.02s 0.02s -bash12# USER:登录用户名。13# TTY:终端名称。14# FROM:登录来源(IP 地址或主机名)。15# LOGIN@:登录时间。16# IDLE:空闲时间。17# JCPU:该终端上所有进程的累计 CPU 时间。18# PCPU:当前活动进程的 CPU 时间。19# WHAT:当前正在执行的命令。
chsh-修改默认Shell
71[DESC]2 用于更改用户的默认登录 shell(命令行解释器)。3 4[EXAMPLE]5 ● chsh -l # 列出所有可用的 shell6 ● chsh -s /bin/tcsh # 将当前用户的默认 shell 更改为 /bin/tcsh7 ● chsh -s /bin/tcsh username # 将用户 username 的默认 shell 更改为 /bin/tcsh
exit-退出当前shell
61[DESC]2 退出当前的 shell 会话或退出登录,它的使用权限是所有用户。3
4[EXAMPLE]5 ● exit # 退出当前终端会话6 ● exit -1 # 在脚本中使用退出状态码
3. 系统信息
uname-查看系统信息
141[DESC]2 显示系统信息,包括内核名称、节点名、内核版本、机器硬件名称等。3
4[EXAMPLE]5 ● uname -a # 显示所有系统信息6
7[root@myhost ~]# uname -a8Linux myhost 5.10.0-14-amd64 #1 SMP Debian 5.10.113-1 (2022-04-22) x86_64 GNU/Linux9# 内核名称:myhost10# 节点名(主机名):myhost11# 内核版本:5.10.0-14-amd6412# 内核版本信息:#1 SMP Debian 5.10.113-1 (2022-04-22)13# 机器硬件名称:x86_6414# 操作系统名称:GNU/Linux
whoami-查看当前用户
121[DESC]2 显示当前有效用户的用户名3
4[root@VM-20-5-centos ~]# whoami5root6
7# 在脚本中检查是否root用户8if [ "$(whoami)" = "root" ]; then9 echo "You are running as root."10else11 echo "You are not running as root."12fi
env-查看环境变量
71[DESC]2 显示当前的环境变量,也可以用于在指定的环境中运行程序。3
4[EXAMPLE]5 ● env # 打印当前环境变量6 ● env PATH=/usr/bin ls # 临时设置 PATH 环境变量并运行 ls 命令7 ● env -i ls # 运行 ls 命令,但不会继承当前环境变量
locale-查看本地化配置
241[DESC]2 显示或设置系统的本地化环境。本地化环境定义了系统的语言、字符编码、日期和时间格式、数字格式等。3
4[EXAMPLE]5 ● locale # 显示当前的本地化设置6 ● locale -a # 显示所有可用的本地化设置7 ● export LANG=en_US.UTF-8 # 设置本地化环境8 9[root@VM-20-5-centos ~]# locale10LANG=en_US.utf811LC_CTYPE="en_US.utf8"12LC_NUMERIC="en_US.utf8"13LC_TIME="en_US.utf8"14LC_COLLATE="en_US.utf8"15LC_MONETARY="en_US.utf8"16LC_MESSAGES="en_US.utf8"17LC_PAPER="en_US.utf8"18LC_NAME="en_US.utf8"19LC_ADDRESS="en_US.utf8"20LC_TELEPHONE="en_US.utf8"21LC_MEASUREMENT="en_US.utf8"22LC_IDENTIFICATION="en_US.utf8"23LC_ALL=24
uptime-查看系统负载
91[DESC]2 查看系统启动时间和负载3
4[root@VM-20-5-centos ~]# uptime5 22:11:32 up 54 days, 10:55, 2 users, load average: 0.00, 0.01, 0.056 7# 提取系统负载8[root@VM-20-5-centos ~]# uptime | awk '{print $10, $11, $12}'90.00, 0.01, 0.05
hostname-查看/修改主机名
111[DESC]2 查看和修改主机名等。3
4[EXAMPLE]5 ● hostname # 显示主机名(配置在/etc/hostname文件)6 ● hostname "HYX" # 临时设置主机名(注意:永久设置需修改/etc/hostname和/etc/hosts文件)7 ● hostnamectl set-hostname VM-20-5-centos # 永久设置主机名(注意:只修改/etc/hostname文件,未修改/etc/hosts文件)8
9[root@VM-20-5-centos ~]# hostname10vm-20-5-centos11
date-查看/修改日期时间
141[DESC]2 显示和设置系统日期和时间,或用于格式化日期输出、计算时间差以及在脚本中处理日期和时间。3
4[EXAMPLE]5 ● date # 显示当前日期和时间6 ● date +"%Y-%m-%d %H:%M:%S" # 显示特定格式的日期和时间7 ● date 042815302025 # 将日期和时间设置为 2025 年 4 月 28 日 15:308
9[root@VM-20-5-centos ~]# date10Mon Apr 28 21:56:39 CST 202511
12[root@VM-20-5-centos ~]# date +"%Y-%m-%d %H:%M:%S"132025-04-28 21:57:3814
lscpu-查看CPU信息
61[DESC]2 显示 CPU 的详细信息,包括处理器架构、核心数量、线程数量、CPU 频率、缓存大小等。3
4[EXAMPLE]5 ● lscpu # 显示所有 CPU 信息6 ● cat /proc/cpuinfo # 显示 CPU 详细信息
free-查看内存信息
151[DESC]2 显示系统的总内存、已用内存、空闲内存以及交换内存(swap)的使用情况。3 4[EXAMPLE]5 ● free -h # 以易读的格式显示内存使用情况6 ● free -l # 显示详细的内存使用情况7 ● free -s 2 # 每 2 秒刷新一次内存使用情况,便于实时监控8 ● cat /proc/meminfo # 显示内存信息9
10[root@VM-20-5-centos ~]# free -h11 total used free shared buff/cache available12Mem: 2.0G 884M 78M 6.6M 1.0G 930M13Swap: 0B 0B 0B14# 行说明:total-总内存,used-已使用,free-空闲,shared-共享内存,buff/cache-缓冲区/缓存,available-实际可用内存15# 列说明:Mem-表示物理内存的使用情况,Swap-表示交换内存的使用情况
df-查看磁盘信息
381[DESC]2 显示文件系统的磁盘空间使用情况,包括各个挂载点的磁盘空间总量、已用量、剩余量以及使用率等信息。3 4[EXAMPLE]5 ● df -h # 显示所有文件系统的磁盘使用情况(易读格式)6 ● df -hT # 显示文件系统的类型7 ● df -i # 显示 inode 的使用情况8
9[root@VM-20-5-centos ~]# df -hT10Filesystem Type Size Used Avail Use% Mounted on11devtmpfs devtmpfs 989M 0 989M 0% /dev12tmpfs tmpfs 1000M 24K 1000M 1% /dev/shm13tmpfs tmpfs 1000M 712K 999M 1% /run14tmpfs tmpfs 1000M 0 1000M 0% /sys/fs/cgroup15/dev/vda1 ext4 50G 15G 33G 31% /16tmpfs tmpfs 200M 0 200M 0% /run/user/017overlay overlay 50G 15G 33G 31% /var/lib/docker/overlay2/9abd0692ae36f2db5c0d4e90880dd9afa2892097243dbe35002d8d7a07232ba1/merged18# Filesystem:文件系统的设备名或挂载点19# Type(使用 -T 选项时):文件系统的类型(如 ext4、tmpfs 等)。20# Size:文件系统的总大小。21# Used:已使用的空间。22# Avail:可用的空间。23# Use%:已使用空间的百分比。24# Mounted on:文件系统的挂载点。25
26[root@VM-20-5-centos ~]# df -i27Filesystem Inodes IUsed IFree IUse% Mounted on28devtmpfs 253075 327 252748 1% /dev29tmpfs 255813 7 255806 1% /dev/shm30tmpfs 255813 516 255297 1% /run31tmpfs 255813 16 255797 1% /sys/fs/cgroup32/dev/vda1 3276800 167423 3109377 6% /33tmpfs 255813 1 255812 1% /run/user/034overlay 3276800 167423 3109377 6% /var/lib/docker/overlay2/9abd0692ae36f2db5c0d4e90880dd9afa2892097243dbe35002d8d7a07232ba1/merged35# Inodes(使用 -i 选项时):文件系统的 inode 总数。36# IUsed(使用 -i 选项时):已使用的 inode 数量。37# IFree(使用 -i 选项时):可用的 inode 数量。38# IUse%(使用 -i 选项时):已使用 inode 的百分比。
du-查看目录大小
231[DESC]2 查看磁盘空间使用情况。3 4[EXAMPLE]5 ● du -h # 显示当前目录的磁盘空间占用情况(易读格式)6 ● du -sh # 仅显示当前目录的总计大小7 ● du -h -t 5M # 仅显示大于指定大小的文件或目录8 ● du -h -d 1 # 按目录深度显示磁盘空间占用情况9 ● du -sh ./* | sort -hr # 查看指定目录磁盘空间使用情况。10
11[root@VM-20-5-centos ~]# du -h -t 5M1243M ./log1339M ./htmls/notes149.2M ./htmls/static15138M ./htmls16182M .17
18[root@VM-20-5-centos ~]# du -sh ./* | sort -hr19138M ./htmls2043M ./log218.0K ./shell224.0K ./calc_md5.sh23
4. 系统管理
at-管理定时任务
231[DESC]2 用于设置单次执行的任务。注意:需要开启 atd 进程(ps -ef | grep atd)。3 4[FORMAT]5 at[参数][时间]6
7[OPTIONS]8 ● at <绝对时间/相对时间> # 进入任务编辑页面(ctrl+d保存退出)9 ● at -l # 查看所有已设置的定时任务(atq)10 ● at -c <任务ID> # 查看任务的详细内容11 ● at -d <任务ID> # 删除任务(atrm)12
13[EXAMPLE]14 ● at 10:17 # 在10:17分执行(可能跨天)15 ● at 5:00PM # 在当天下午 5 点执行16 ● at 17:20 tomorrow # 在明天的 17:20 执行17 ● at 5pm+3 days # 在 3 天后的下午 5 点执行18 ● at noon + 1000 days # 在当前时间的 1000 天后的中午 12 点执行19
20[REMARK-黑白名单]21 ● /etc/at.deny: 黑名单,写入该文件的用户不能使用at命令22 ● /etc/at.allow:白名单,仅写入该文件的用户可以使用at命令23 ● 注意:root用户不受黑白名单控制;黑白名单同时存在时白名单会覆盖黑名单,都不存在时仅root用户可执行at命令。
crontab-管理周期任务
381[DESC]2 依赖cron服务管理周期任务。3
4[EXAMPLE] 5 ● crontab -e # 打开当前用户的 crontab 文件进行编辑(vim /etc/crontab)6 ● crontab -l # 列出当前用户的 crontab 文件内容7 ● crontab -r # 删除当前用户的 crontab 文件,所有计划任务将被移除8 ● crontab -e -u hyx # 打开某个用户的 cron 服务(一般 root 用户在执行这个命令的时候需要此参数)9 10[REMARK-crontab配置]11 * * * * * command arg...12 分(0-59) 时(0-23) 日(0-31) 月(0-12) 周(0-7) 命令 参数13
14 星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。15 逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”。16 中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”。17 正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。18
19[REMARK-crontab示例]20 ● * * * * * /path/to/command # 每分钟执行一次任务21 ● * * * * * /path/to/command > /dev/null 2>&1 # 输出重定向到 /dev/null(默认情况下,cron 任务的输出通常会发送到用户的邮箱)22 ● */5 * * * * /root/backupscript.sh # 每隔 5 分钟运行一次 backupscript.sh 脚本23 ● 0 1 * * * /root/backupscript.sh # 每天的凌晨 1 点运行 backupscript.sh 脚本24 ● 15 3 1 * * /root/backupscript.sh # 每月的第一个凌晨 3:15 运行 backupscript.sh 脚本25 ● 30 21 * * * /usr/local/etc/rc.d/lighttpd restart # 每晚的21:30重启apache。26 ● 45 4 1,10,22 * * /usr/local/etc/rc.d/lighttpd restart # 每月1、10、22日的4:45重启apache。27 ● 10 1 * * 6,0 /usr/local/etc/rc.d/lighttpd restart # 每周六、周日的1:10重启apache。28 ● 0,30 18-23 * * * /usr/local/etc/rc.d/lighttpd restart # 每天18:00至23:00之间每隔30分钟重启apache。29 ● 0 23 * * 6 /usr/local/etc/rc.d/lighttpd restart # 每星期六的11:00 pm重启apache。30 ● * */1 * * * /usr/local/etc/rc.d/lighttpd restart # 每一小时重启apache31 ● * 23-7/1 * * * /usr/local/etc/rc.d/lighttpd restart # 晚上11点到早上7点之间,每隔一小时重启apache32 ● 0 11 4 * mon-wed /usr/local/etc/rc.d/lighttpd restart # 每月的4号与每周一到周三的11点重启apache33 ● 0 4 1 jan * /usr/local/etc/rc.d/lighttpd restart # 一月一号的4点重启apache34 ● */30 * * * * /usr/sbin/ntpdate 210.72.145.44 # 每半小时同步一下时间35
36[REMARK-注意事项]37 ● cron 任务运行时的环境变量可能与登录用户不同,如果任务依赖于某些环境变量,建议在任务脚本中显式设置这些变量。38
ifconfig-网卡配置
81[DESC]2 用于查看网络接口的状态、配置 IP 地址、启用或禁用接口等,已逐渐被 ip 命令取代。3 4[EXAMPLE]5 ● ifconfig # 查看网络接口6 ● ifconfig eth0 # 查看特定网络接口7 ● ifconfig -a # 列出所有网络接口及其配置信息,包括 IP 地址、子网掩码、MAC 地址等8 ● ifconfig eth0 192.168.1.100 netmask 255.255.255.0 # 为 eth0 分配 IP 地址和子网掩码
ip-新一代网卡配置
81[DESC]2 用于显示和操作路由、网络设备、接口等网络配置。3 4[EXAMPLE]5 ● ip a # 查看网络接口6 ● ip addr show eth0 # 查看特定网络接口7 ● ip r # 查看路由表8 ● sudo ip addr add 192.168.1.100/24 dev eth0 # 为 eth0 分配 IP 地址和子网掩码
netstat-查看端口信息
111[DESC]2 用于显示网络连接、路由表、接口统计信息等网络相关信息,已逐渐被 ss 命令所取代。3
4[EXAMPLE]5 ● netstat -a # 查看所有网络连接6 ● netstat -t # 查看 TCP 连接7 ● netstat -u # 查看 UDP 连接8 ● netstat -l # 仅显示处于监听状态的端口9 ● netstat -n # 以数字形式显示地址和端口号,不进行 DNS 解析10 ● netstat -p # 显示程序名称11 ● netstat -lantp | grep mysql # 查看mysql占用的端口
ping-检查远程主机连线状态
51[DESC]2 用于测试主机之间的网络连接是否正常。3
4[EXAMPLE]5 ● ping www.baidu.com # 发生 ICMP 请求检查网络连通性
ps-查看进程列表
101[DESC]2 用于显示当前运行的进程信息。3 4[EXAMPLE]5 ● ps -ef # 显示所有进程的详细信息6 ● ps -ef | grep mysql # 检查是否启动mysql进程7 ● ps -eo pid,comm,%cpu,%mem --sort=-%cpu | head # 按 CPU 使用率排序8 ● ps -eo pid,comm,%cpu,%mem --sort=-%mem | head # 按内存使用率排序9 ● ps -ef --forest # 显示树状结构的进程关系10 ● watch "ps -eo pid,comm,%cpu,%mem --sort=-%cpu" # 每 2 秒刷新一次进程信息,显示当前 CPU 使用率最高的进程
pstree-查看进程树
131[DESC]2 以树状结构显示进程及其父子关系。3 4[FORMAT]5 pstree [<options>] [<pid> | <user>]6 pstree -V | --version7
8[EXAMPLE]9 ● pstree # 显示系统中所有进程的树状结构,以 init(或 systemd)为根10 ● pstree -a # 显示每个进程的完整命令行参数11 ● pstree -p # 每个进程名称旁边显示其 PID12 ● pstree 1451 # 只显示指定进程号13 ● pstree mysql # 只显示指定用户
top-进程资源监控
271[DESC]2 实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。3 4[OPTIONS]5 ● -b # 批处理6 ● -c # 显示完整的命令7 ● -I # 忽略失效过程8 ● -s # 保密模式9 ● -S # 累积模式10 ● -i<时间> # 设置间隔时间11 ● -u<用户名> # 指定用户名12 ● -p<进程号> # 指定进程13 ● -n<次数> # 循环显示的次数14 15[EXAMPLE]16 ● top # 显示进程信息。17 ● top -c # 高亮显示当前运行进程18 ● top -n 2 # 更新两次后终止更新显示19 ● top -d 3 # 更新周期为3秒20 ● top -p 574 # 显示指定的进程信息21 22[REMARK-交互命令]23 ● 1 # 显示每个 CPU 核心的使用率24 ● b # 高亮/取消高亮当前运行进程25 ● x # 高亮/取消高亮排序行26 ● P/M/T # 分别以CPU%、%MEM、Time+列排序27 ● c # 切换显示完整命令
kill-杀死进程
221[DESC]2 实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。3 4[FORMAT]5 kill [OPTION] [PID]6 7[OPTIONS]8 ● -l # 信号,若果不加信号的编号参数,则使用“-l”参数会列出全部的信号名称。9 ● -a # 当处理当前进程时,不限制命令名和进程号的对应关系。10 ● -p # 指定 kill 命令只打印相关进程的进程号,而不发送任何信号。11 ● -s # 指定发送信号。12 ● -u # 指定用户。13 14[EXAMPLE]15 ● kill -2 1234 # 终止进程,类似于用户按下 Ctrl+C16 ● kill -9 1234 # 强制终止进程,该信号不能被进程捕获或忽略17 ● kill -15 1234 # 请求进程终止(默认信号)18 ● killall -9 firefox # 批量终止进程19 ● pkill -9 kgbp* # 批量终止进程,支持正则表达式20
21[REMARK]22 ● 僵尸进程不能被 kill 命令终止,因为它们已经“死亡”。在这种情况下,需要终止父进程或等待父进程读取状态信息。
jobs-管理系统任务
71[DESC]2 用于管理后台作业,通常与 &(后台运行符号)、fg(前台运行)、bg(后台运行)和 kill 等命令配合使用。3 4[EXAMPLE]5 ● jobs -l # 查看后台作业6 ● sleep 100 & # 将作业放在后台执行7 ● fg %1 # 把作业号为 1 的作业放到前台运行
watch-监控动态信息
111[DESC]2 定期运行指定的命令,并显示其输出的变化,非常适合用于监控系统状态、日志文件或其他动态信息。3 4[EXAMPLE]5 ● watch "df -h" # 实时监控磁盘空间使用情况 6 ● watch -n 5 "df -h" # 实每 5 秒刷新一次7 ● watch -d "df -h" # 高亮显示变化的部分8 ● watch -c "ls --color=auto" # 支持彩色输出9 ● watch -t "df -h" # 不显示标题信息,如“Every 2.0s: df -h”标题10 ● watch -n 1 "tail -n 50 /var/log/syslog" # 监控日志文件的变化11 ● watch -g "df -h" -c "echo 'Disk usage changed!'" # 当输出发生变化时运行其他命令
5. 文件管理
ls-查看文件/目录信息
251[DESC]2 列出当前或指定目录内容,默认按照文件名排序。3
4[OPTIONS]5 ● -l:列出详细信息,可简写为 ll 命令。6 ● -a:显示以.开头的隐藏文件。7 ● -t:按建立时间先后排序。8 ● -S:按文件大小从大到小排序。9 ● -r:反向排序。10 ● -R:递归执行。11
12[EXAMPLE]13 ● ll -at ./logs # 查看 logs 目录下的所有文件,并按创建时间排序14
15[REMARK-文件详细信息]16 # 文件详细信息如下:17 drwxr-xr-x. 2 root root 80 Jun 28 09:40 fsck18 prw-------. 1 root root 0 Jun 28 09:40 initctl19 srw-rw-rw-. 1 root root 0 Jun 28 09:40 rpcbind.sock20 -rw-r--r--. 1 root root 5 Jun 28 09:40 crond.pid21 lrwxrwxrwx. 1 root root 15 Jun 28 09:40 stdin -> /proc/self/fd/022 brw-rw----. 1 root disk 8, 0 Jun 28 09:40 sda23 # 从左到右依次为:文件类型(1位) 文件权限(3组) 次级目录数/软链接数 所属用户+组 文件大小 最后修改日期 文件名24 # 其中文件类型包括:文件(_)、目录(d)、软链接(l)、管道(p)、Socket(s)、块设备(b)、字符设备(c)。25 # 3组文件权限分别代表:属主权限、属组权限、其他用户权限,每组又分3位,表示r-读、w-写、x-可执行,权限数分别为6、4、2。
cd-修改当前工作目录
101[DESC]2 切换当前工作目录。3
4[EXAMPLE]5 ● cd /usr 表示进入目录 /usr 中。6 ● cd . 表示进入当前目录。7 ● cd .. 表示进入(退到)上一层目录,两个点代表父目录。8 ● cd – 表示进入前一个目录,适用于在两个目录之间快速切换。9 ● cd ~ 表示进入主目录,若是 root 用户则回到/root 目录下,若是普通用户则回到 /home 目录下。10 ● cd 不带参数,则默认回到主目录。
pwd-查看当前工作目录
61[DESC]2 显示当前工作目录路径。3 4[OPTIONS]5 ● -L # 显示逻辑路径(默认行为),即符号链接的路径,通过符号链接进入该目录时会有不同。6 ● -P # 显示物理路径,指当前工作目录的实际路径。
mkdir-创建目录
91[DESC]2 创建目录(文件夹),可以一次性创建多个目录,如果目录已经存在,默认会报错。3
4[OPTIONS]5 ● -p # 创建多级目录,且目录已存在时不报错。6 7[EXAMPLE]8 ● mkdir dir1 dir2 dir3 # 同时创建多个目录9 ● mkdir -p dir1/dir2/dir3 # 创建多级目录
touch-创建空文件或修改文件的时间戳
71[DESC]2 创建空文件 或 更新文件的时间戳。3
4[EXAMPLE]5 ● touch file01 # 如果 file01 不存在则创建,存在则更新文件的访问时间和修改时间。6 ● touch -a file01 # 仅更新文件的访问时间7 ● touch -m file01 # 仅更新文件的修改时间
ln-创建链接文件
161[DESC]2 用于创建硬链接或软链接(-s参数)。3 4[FORMAT]5 ln [选项] [源文件或目录] [目标链接名]6
7[EXAMPLE]8 ● ln file.txt hardlink.txt # 创建硬链接 hardlink.txt9 ● ln -s /home/user/documents/file.txt ~/link_to_file.txt # 创建符号链接 link_to_file.txt10 ● ln -s /home/user/projects ~/link_to_projects # 创建指向目录的符号链接 link_to_projects11 ● ln -sf /path/to/new/source/file.txt ./symlink.txt # 强制覆盖已存在的链接12 ● ln -sn /path/to/new/source/directory ./symlink_dir # 防止覆盖已存在的链接13
14[REMARK-链接类型]15 ● 硬链接:源文件和链接文件是对等的关系,索引节点(inode)号相同,节省磁盘空间,但不能跨文件系统,也不能指向目录或不存在的文件。16 ● 软链接:链接文件指向一个文件路径,两者 inode 不同,类似于Windows的快捷方式。
file-查看文件类别
131[DESC]2 过分析文件的内容来判断文件的类型,而不仅仅是依赖文件的扩展名。3 4[EXAMPLE]5 ● file example.txt # 检查单个文件的类型6 ● file -z example.gz # 检查压缩文件的内容类型7 ● file -L symlink # 检查符号链接的目标文件类型8
9[root@vm-20-5-centos ~]# file calc_md5.sh10calc_md5.sh: Bourne-Again shell script, UTF-8 Unicode text executable11
12[root@vm-20-5-centos ~]# file log.tar.gz13log.tar.gz: POSIX tar archive (GNU)
cp-复制文件或者目录
211[DESC]2 用于复制文件或目录。3
4[FORMAT]5 cp [选项] 源文件或目录 目标文件或目录6
7[EXAMPLE]8 ● cp f1 f2 # 复制单个文件9 ● cp f1 d1/ # 复制文件到目录10 ● cp f1 f2 f3 d1/ # 复制多个文件,目的位置必须是一个目录11 ● cp -r d1 d2 # 递归复制目录12 ● cp -p f1 f2 # 保留文件的修改时间、访问时间和权限等属性。13 ● cp -f f1 f2 # 强制覆盖目标文件14 ● cp -i f1 f2 # 交互式覆盖15 ● cp -v f1 f2 # 显示操作过程16 ● cp -d symlink backup/ # 复制符号链接本身17 ● cp -L symlink backup/ # 复制符号链接指向的目标文件18 19[root@vm-20-5-centos ~]# cp -rv log log220‘log’ -> ‘log2’21‘log/autoupdatesvn.log’ -> ‘log2/autoupdatesvn.log’
mv-移动文件或者目录
191[DESC]2 用于移动文件和目录的命令,也可以用来重命名文件和目录。3 4[FORMAT]5 mv [选项] 源文件或目录 目标文件或目录6
7[OPTIONS]8 ● -b :若需覆盖文件,则覆盖前先行备份。9 ● -f :force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖。10 ● -i :若目标文件 (destination) 已经存在时,就会询问是否覆盖。11 ● -u :若目标文件已经存在,且 source 比较新,才会更新(update)。12 13[EXAMPLE]14 ● mv file.txt backup/ # 移动单个文件15 ● mv file.txt newfile.txt # 重命名文件16 ● mv f1 f2 f3 d1/ # 移动多个文件17 ● mv -f f1 f2 # 强制覆盖目标文件18 ● mv -i f1 f2 # 交互式移动19 ● mv -v f1 f2 # 显示操作过程
rm-删除文件或者目录
191[DESC]2 删除文件或者目录。rm 命令删除文件时并不是把文件放到类似图形界面的“回收站”里,所以没有“撤销删除”操作可用。3 4[FORMAT]5 rm [OPTIONS] DIRECTORY _or_FILE6
7[OPTIONS]8 ● -i:进行交互式删除,在删除前进行询问,确认是否需要删除。9 ● -f:强制删除文件,不会询问而直接删除。10 ● -r:指示 rm 将参数中列出的全部目录和子目录均递归地删除。11 ● -v:详细显示进行的步骤。12 13[EXAMPLE]14 ● rm f1 # 删除单个文件15 ● rm f1 f2 # 删除多个文件16 ● rm -r f1 # 递归删除目录17 ● rm -f f1 # 强制删除文件18 ● rm -i f1 # 交互式删除19 ● rm -v f1 # 显示操作过程
find-精确查找文件
231[DESC]2 根据多种条件(如文件名、类型、大小、权限、修改时间等)来查找匹配的文件和目录。3 4[FORMAT]5 find [搜索路径] [选项] [表达式]6 7[OPTIONS]8 ● -name # 按照文件名查找文件。9 ● -perm # 按照文件权限来查找文件 。10 ● -user # 按照文件属主来查找文件 。11 ● -mtime -n +n # 按照文件的更改时间来查找文件。12 13[EXAMPLE]14 ● find / -name "file.txt" # 按文件名搜索,支持 * 通配符15 ● find . -type d # 按文件类型搜索,d 表示目录16 ● find . -mtime -7 # 按修改时间搜索,查找当前目录及其子目录中最近 7 天内修改过的文件17 ● find . -size +1M # 按文件大小搜索,查找当前目录及其子目录中大于 1MB 的文件18 ● find . -perm 755 # 按权限搜索,查找当前目录及其子目录中权限为 755 的文件19 ● find . -user user # 按用户搜索,查找当前目录及其子目录中属于用户 user 的文件20 ● find . -user user -size +1M # 组合条件,查找当前目录及其子目录中属于用户 user 且大小大于 1MB 的文件21 ● find . -name "*.txt" -exec rm {} \; # 执行操作,查找当前目录及其子目录中所有 .txt 文件,并删除它们22 ● find -size 0 # 查找大小为 0 的文件。23 ● find -empty -delete # 查找空文件或目录并将其删除。
locate-快速查找文件
81[DESC]2 用于快速查找文件。它通过搜索一个预先构建的数据库(通常是 /var/lib/mlocate/mlocate.db)来查找文件路径,而不是实时扫描文件系统。3 4[EXAMPLE]5 ● locate file.txt # 查找名为 file.txt 的文件6 ● locate -i file.txt # 忽略大小写7 ● locate -b file.txt # 只想匹配文件名 file.txt,不匹配路径8 ● sudo updatedb # 更新数据库
which-定位可执行文件
91[DESC]2 根据环境变量 $PATH 确定某个命令或程序的完整路径。3 4[FORMAT]5 which [ OPTIONS ] PROGRAM NAME6 7[EXAMPLE]8 ● which ls # 查找 ls 命令的路径9 ● which –a ls # 显示所有匹配的路径
gzip-gz压缩和解压
131[DESC]2 使用 Lempel-Ziv 编码(LZ77)算法压缩和解压缩文件,生成 .gz 文件。3
4[FORMAT]5 gzip [选项] 文件名6
7[EXAMPLE]8 ● gzip file.txt # 压缩单个文件,将 file.txt 压缩为 file.txt.gz,并删除原始文件9 ● gzip -k file.txt # 保留原始文件10 ● gzip -r mydirectory # 递归压缩目录下的所有文件11 ● gzip -v file.txt # 显示压缩进度12 ● gzip -t file.txt.gz # 测试压缩文件的完整性13 ● gzip -d file.txt.gz # 解压缩单个文件,将 file.txt.gz 解压缩为 file.txt
bzip2-bz2压缩和解压
131[DESC]2 用于压缩和解压缩文件的工具,它使用 Burrows-Wheeler 块排序文本压缩算法,通常比 bzip2 提供更高的压缩比,但压缩速度较慢,生成 .bz2 文件。3
4[FORMAT]5 bzip2 [选项] 文件名6
7[EXAMPLE]8 ● bzip2 file.txt # 压缩单个文件,将 file.txt 压缩为 file.txt.bz2,并删除原始文件9 ● bzip2 -k file.txt # 保留原始文件10 ● bzip2 -r mydirectory # 递归压缩目录下的所有文件11 ● bzip2 -v file.txt # 显示压缩进度12 ● bzip2 -t file.txt.bz2 # 测试压缩文件的完整性13 ● bzip2 -d file.txt.bz2 # 解压缩单个文件,将 file.txt.bz2 解压缩为 file.txt
zip/unzip-打包/解包文件
141[DESC]2 用于压缩和解压缩文件的命令,它支持将多个文件和目录打包成一个 .zip 文件,同时也支持对 .zip 文件进行解压缩。3
4[FORMAT]5 zip [选项] 压缩包名 文件或目录6 unzip 压缩包名字.zip [-d 解压目录]7
8[EXAMPLE]9 ● zip archive.zip file.txt # 压缩单个文件10 ● zip zip archive.zip file1.txt file2.txt # 压缩多个文件11 ● zip -r archive.zip mydirectory/ # 递归压缩目录12 ● zip -t archive.zip # 测试压缩包的完整性13 ● unzip archive.zip # 解压到当前目录14 ● unzip archive.zip -d ./d1 # 指定解压目录
rar/unrar-打包/解包文件
121[DESC]2 用于处理 RAR 压缩文件。3
4[INSTALL]5 apt-get install unrar rar # 基于 Debian 的系统(如 Ubuntu)6 yum install unrar rar # 基于 Red Hat 的系统(如 CentOS、Fedora)7 8[EXAMPLE]9 ● rar a archive.rar mydirectory/ # 打包10 ● unrar x 文件名.rar ./d1 # 解包11 ● unrar x -p密码 文件名.rar # 解包(带密码)12 ● unrar l 文件名.rar # 查看
tar-打包/解包文件
241[DESC]2 用于打包和压缩文件,通常和压缩工具(如 gzip、bzip2 或 xz)一起使用。3 4[FORMAT]5 tar [选项] [文件或目录]6 7[OPTIONS]8 ● -c:建立新的压缩文件。9 ● -x:从压缩的文件中提取文件。10 ● -t:显示压缩文件的内容。11 ● -z:支持 gzip 解压文件。12 ● -j:支持 bzip2 解压文件。13 ● -v:显示操作过程。14 15[EXAMPLE]16 ● tar -cvf archive.tar file1.txt file2.txt # 创建归档文件17 ● tar -xvf archive.tar # 解压归档文件18 ● tar -tvf archive.tar # 列出归档文件内容19 ● tar -czvf archive.tar.gz file1.txt file2.txt # 使用 gzip 压缩20 ● tar -xzvf archive.tar.gz # 解压 .tar.gz 文件21 ● tar -xzvf archive.tar.gz -C /path/to/destination # 指定解压目标目录22 ● tar -cjvf archive.tar.bz2 file1.txt file2.txt # 使用 bzip2 压缩23 ● tar -xjvf archive.tar.bz2 # 解压 .tar.bz2 文件24 ● tar -czvf archive.tar.gz --exclude='*.log' mydirectory/ # 排除文件或目录
6. 文本处理
vim-文件编辑
741[命令描述]2 对文本进行编辑、修改、保存等操作。3
4[打开文件] 5 # 打开一个文件,若该文件已存在,则会打开文件并显示文件内容,若该文件不存在,vim 会在下面提示 [New File],并且会在第一次保存时创建该文件。6 vim [OPTIONS] [FILE]7 ● -c # 打开文件前先执行指定的命令。8 ● -R # 以只读方式打开,但是可以强制保存。9 ● -M # 以只读方式打开,不可以强制保存。10 ● -r # 恢复崩溃的会话。11 ● + num # 从第 num 行开始。12
13[移动光标] 14 ● ←/↓/↑/→ # 光标向左/下/上/右移动一个字符(也可用h/j/k/l操作)15 ● HOME/END # 光标移动到本行行首/行尾(也可用0/$操作)16 ● PGUP/PGDN # 光标向上/向下翻页17 ● g0/g$ # 光标移动到所在屏幕行行首/行尾18 ● gg/G # 光标移动到文件头部/尾部19 ● :n # 光标移动到第n行20 21[插入模式] 22 # 使用 vim filename 打开文件后,进入的是普通模式。当想要修改文件时,可以按 i 键进入插入模式。进入插入模式时,会在最下面提示当前模式是 Insert。按 ecs 可以退出插入模式,回到普通模式。23 ● i # 在光标之前进行插入24 ● a # 在光标之后进行插入25 ● o # 在下一行进行插入26 ● O # 在上一行进行插入27
28[保存/退出] 29 # 在插入模式下按 esc 键即可回到普通模式下,在普通模式下输入 : 进入命令行模式,通过命令行模式输入的指令执行保存或退出命令。30 ● :w # 保存文档。31 ● :wq # 保存并退出文档。32 ● :q! # 强制退出但不保存,因此会造成文本丢失,需谨慎操作。33 ● :q # 仅退出,在未编辑过文本的情况下可以执行,但文本有修改会出现提示,修改过的文档需要通过其他指令如:wq 或:q!进行退出。34 ● :wq! # 强制保存并退出。35
36[快速编辑] 37 ● yy # 复制整行文本(也可以用y操作)38 ● y[n]y # 复制n行文本39 ● y[n]w # 复制n个词40 ● p # 粘贴在当前行之下41 ● P # 粘贴在当前行之上42 ● dd # 删除当前行43 ● d[n]d # 删除(剪切)n行44 ● d[n]w # 删除(剪切)n个单词45
46[查找/替换] 47 ● :/word # 在光标之后查找一个字符串 word,按 n 查找下一个,按 N 查找上一个。48 ● :?word # 在光标之前查找一个字符串 word,按 n 查找下一个(向前),按 N 查找上一个(向后)。49 ● :1,5s/word1/word2/g # 将文档中 1-5 行的 word1 替换为 word2(若不加 g 则只替换每行的第一个 word1)。50 ● :%s/word1/word2/gi # 将文档所有的 word1 替换为 word2,不区分大小写。51
52[撤销/重做] 53 ● u # 在普通模式下输入 u,撤销最近的改变。例如撤销已经输入的“hello openEuler”。54 ● U # 在普通模式下输入 U,撤销当前行自从光标定位在上面开始的所有改变。55 ● ctrl+r # 重做最后一次“撤销”改变。例如需要恢复刚撤销的“hello openEuler”56
57[行号显示]58 ● :set nu # 显示行号59 ● :set nonu # 取消显示行号60 61[搜索高亮] 62 # 在 vim 命令行模式下,可以临时设置搜索高亮,方便用户阅读,若需要进行永久设置,需要在/etc/vimrc 中配置,增加一行 set hlsearch,然后更新变量即可。63 ● :set hlsearch # 设置搜索高亮64 ● :set nohlsearch # 取消设置搜索高亮65
66[分屏操作]67 :sp 文件2 # 上下分屏68 :vsp 文件2 # 左右分屏69 Ctrl+w+w # 切换分屏70 Ctrl+w c # 关闭当前分屏71
72[其它]73 :!SHELL命令 # 在VIM执行SHELL命令74 gg=G # 格式化代码
cat/more/less-查看文件
211[DESC]2 一个文本文件查看和连接工具。3 4[FORMAT]5 cat [OPTIONS] [FILE]6 7[OPTIONS]8 ● -n:从 1 开始对所有行编号并显示在每行开头9 ● -b:从 1 开始对非空行编号并显示在每行开头10 ● -s:当有多个空行在一起时只输出一个空行11 ● -E:在每行结尾增加$12 13[EXAMPLE]14 ● cat file1 # 显示文件内容15 ● cat > file1 # 编辑文件16 ● cat file1 file2 > file3 # 合并文件17 ● cat -n /etc/profile # 显示行号18
19[EXAMPLE-more/less命令]20 ● cat example.txt | more # 简单分页展示21 ● cat example.txt | less # 高级分页展示
head/tail-文件摘选
131[DESC]2 用于查看文件的开头部分或结尾部分的内容。3
4[EXAMPLE-head]5 ● head /etc/passwd # 显示前10行6 ● head -20 /etc/passwd # 显示前20行,等同于:head -n -20 /etc/passwd7 ● head -c -5 /etc/passwd # 显示前5个字节8 9[EXAMPLE-tail]10 ● tail /etc/passwd # 显示后10行11 ● tail -20 /etc/passwd # 显示后20行,等同于:tail -n -20 /etc/passwd12 ● tail -c 100 /etc/passwd # 显示后100个字节13 ● tail -f /etc/passwd # 监控文件变化
wc-文本统计
111[DESC]2 用于统计文件的行数、单词数和字节数。3 4[OPTIONS]5 ● -l:显示统计的行数6 ● -w:显示统计的单词数(英文字母)7 ● -c:显示统计的字节数8
9[EXAMPLE]10 ● wc -l example.txt # 获取文件行数11 ● cat /etc/passwd | wc -lwc # 获取行数、单词数和字节数
tr-字符转译
411[DESC]2 用于对字符进行转换、删除或压缩。3 4[FORMAT]5 tr [-cdst] [第一字符集][第二字符集]6 7[OPTIONS]8 ● -c # 反选设定字符,也就是符合 set1 的部分不做处理,不符合的剩余部分才进行转换9 ● -d # 删除字符10 ● -s # 缩减连续重复的字符成指定的单个字符11 ● -t # 削减 set1 指定范围,使之与 set2 设定长度相等12
13[字符类]14 [:alnum:] # 字母和数字15 [:alpha:] # 字母16 [:cntrl:] # 控制(非打印)字符17 [:digit:] # 数字18 [:graph:] # 图形字符19 [:lower:] # 小写字母20 [:print:] # 可打印字符21 [:punct:] # 标点符号22 [:space:] # 空白字符23 [:upper:] # 大写字母24 [:xdigit:] # 十六进制字符25
26[EXAMPLE]27 ● cat /etc/passwd | tr a-z A-Z # 将小写字母转换为大写字母28 ● cat /etc/passwd | | tr [:lower:] [:upper:] # 将小写字母转换为大写字母29 ● echo "12345" | tr '0-9' 'a-j' # 将数字 0-9 替换为字母 a-j30 ● echo "first 123 blood 456" | tr -c '0-9 \n' '&' # 把除数字,空格,换行符之外的所有字符串,都替换成 &31 ● echo "first 123 blood 456" | tr -d "0-9" # 删除所有的数字32 ● echo "first 123 blood 456" | tr -d [:digit:] # 删除所有的数字33 ● echo "first 123 blood 456" | tr -dc '0-9 \n' # 删除除数字/空格/换行符之外的所有字符串34 ● echo "hello world" | tr -s ' ' # 压缩连续的空格35 ● echo -e "line1\n\n\nline2" | tr -s '\n' # 压缩连续的换行符36 ● echo "he'sssss age issssss 12222222222." | tr -s 's2' # 压缩连续的字符,s和237 38[REMARK]39 ● 只适用于单字节字符,不适用于中文等多字节字符。40 ● 如果字符集1长,则会重复字符集2的最后1个字符来补齐长度,如:echo "hello" | tr 'a-z' 'A'41 ● 如果字符集2长,则会将字符集2进行截断,保持长度一致。
sort-文本行排序
191[DESC]2 用于对文本文件中的文本行进行排序。3 4[FORMAT]5 sort [ OPTIONS ] [FILE]6 7[OPTIONS]8 ● -b:忽略每行前面开始的空格字符9 ● -c:检查文件是否已经按照顺序排序10 ● -d:排序时,处理英文字母、数字及空格字符外,忽略其他字符11 ● -f:排序时,将小写字母视为大写字母12 ● -n:依照数值的大小排序13 ● -r:降序排序14 ● -u:忽略相同行15
16[EXAMPLE]17 ● sort data.txt # 按字符的 ASCII 值进行排序18 ● cat /etc/passwd | sort -br # 忽略每行前的空格,然后反序排序19 ● sort -k 1,1 -k 2n data.txt # 高级用法,指定列多级排序
diff-文本行对比
181[DESC]2 以逐行的方式,比较文本文件的异同处。如果指定要比较目录,则 diff 会比较目录中相同文件名的文件,但不会比较其中子目录。3 4[FORMAT]5 diff [OPTIONS] FILE1_or_DIRECTORY1 FILE2_or_DIRECTORY26 7[OPTIONS]8 ● -B:忽略空白行的差异9 ● -b:忽略一行中多个空白的差异10 ● -c:显示全部内容,并标出不同之处11 ● -i:忽略大小写的不同12 ● -r:比较子目录中的文件13 ● -w:忽略全部的空格字符14
15[EXAMPLE]16 ● diff f1 f2 # 比较文件 f1 与文件 f2 的区别,仅列出不同的文本,用“---”符号分隔,之上是 f1 中不同的内容,之下是 f2 中不同的内容。17 ● diff -c f1 f2 # 比较文件 f1 与文件 f2 的区别,显示全部内容,并标出不同之处,有“---”符号上方是 f1 的所有内容,下方是 f2 的所有内容,用“!”表示不同的行。18 ● diff -r d1 d2 # 比较子目录 d1 与子目录 d2 的中文件的区别。
cut-文本行提取列
181[DESC]2 用于从文本文件或输入流中提取指定的列或字段。3 4[FORMAT]5 cut [选项] [文件]6 7[OPTIONS]8 ● -b:按字节显示,显示指定范围内的字节内容9 ● -c:按字符显示,显示指定范围内的字符内容10 ● -d:指定字段分隔符,默认为制表符(\t)。11 ● -f:显示指定第 num 个字段的内容,可以用逗号隔开显示多个字段。12 ● -s:仅输出包含分隔符的行。如果某行没有分隔符,则该行不会被输出13
14[EXAMPLE]15 ● cut -c 3-8 /etc/passwd # 显示/etc/passwd 文件中每行第 3 到第 8 个字符。16 ● cut -d: -f1 /etc/passwd # 每行以:分割,显示第1列。17 ● cut -d: -f1,2,4 /etc/passwd # 每行以:分割,显示第1,2,4列。18 ● cut -d: -f2-3 /etc/passwd # 每行以:分割,显示第2~3列。
grep-提取关键字
301[DESC]2 通过正则表达式匹配来搜索文本文件或输入流中的内容,并输出匹配的行。3 4[FORMAT]5 grep [选项] 搜索模式 [文件]6 7[OPTIONS]8 ● -i:忽略大小写,进行大小写不敏感的搜索。9 ● -v:反向搜索,输出不匹配指定模式的行。10 ● -w:仅匹配完整的单词。11 ● -r 或 -R:递归搜索目录中的所有文件。12 ● -n:在输出中显示匹配行的行号。13 ● -c:统计匹配的行数,而不是输出匹配的内容。14 ● -l:仅列出包含匹配行的文件名。15 ● -o:仅输出匹配的部分,而不是整行。16 ● -e:指定多个搜索模式,可以多次使用。17 ● -E:使用扩展正则表达式(ERE),支持更复杂的正则表达式语法。18 ● -F:将模式视为固定字符串,而不是正则表达式。19 ● -q:静默模式,不输出任何内容,仅返回状态码(0 表示找到匹配,1 表示未找到)。20
21[EXAMPLE]22 ● cat /etc/passwd | grep hyx # 基本搜索23 ● grep -i 'apple' data.txt # 忽略大小写24 ● grep -v 'apple' data.txt # 反向搜索25 ● grep -w 'apple' data.txt # 仅匹配完整单词26 ● grep -n 'apple' data.txt # 显示行号27 ● grep -c 'apple' data.txt # 统计匹配行数28 ● grep -r 'apple' . # 递归搜索当前目录及其子目录29 ● grep -E '^a' data.txt # 使用扩展正则表达式30 ● grep -e 'apple' -e 'banana' data.txt # 搜索包含 "apple" 或 "banana" 的行
sed-文本行编辑
391[DESC]2 用于对文本文件或输入流进行基本的文本转换和编辑操作(默认只修改缓冲区,不影响原文件)。3 4[FORMAT]5 sed [选项] '命令' [文件]6 7[OPTIONS]8 ● -e:允许在单次调用中执行多个编辑命令。9 ● -f:从文件中读取 sed 命令。10 ● -i:直接修改文件内容,而不是将结果输出到标准输出。11 ● -n:静默模式,仅输出匹配的行。12 ● -r 或 -E:使用扩展正则表达式(ERE),支持更复杂的正则表达式语法。13
14[常用命令]15 ● s/模式/替换内容/ # 替换文本中的模式。16 ● d # 删除匹配的行。17 ● p # 打印匹配的行。18 ● a\ # 在当前行后追加文本。19 ● i\ # 在当前行前插入文本。20 ● c\ # 替换当前行为指定文本。21 ● q # 退出 sed。22 ● = # 打印当前行的行号。23
24[EXAMPLE]25 ● sed 's/apple/orange/' data.txt # 将文件中的 "apple" 替换为 "orange"26 ● sed 's/a/A/g' data.txt # 全局替换,将文件中的所有 "a" 替换为 "A"27 ● sed '/banana/d' data.txt # 删除包含 "banana" 的行28 ● sed -n '/cherry/p' data.txt # 仅打印包含 "cherry" 的行29 ● sed '/apple/a\is a fruit' data.txt # 在行后追加文本,在包含 "apple" 的行后追加 "is a fruit"30 ● sed '/date/i\Today is' data.txt # 在行前插入文本,在包含 "date" 的行前插入 "Today is"31 ● sed '/banana/c\fruit' data.txt # 替换整行,将包含 "banana" 的行替换为 "fruit"32 ● sed -i 's/apple/orange/' data.txt # 直接修改文件,将文件中的 "apple" 替换为 "orange",并直接修改文件33 ● sed -E 's/^a.*/fruit/' data.txt # 使用扩展正则表达式,替换以 "a" 开头的行34 ● sed -n '/cherry/=' data.txt # 打印行号,打印包含 "cherry" 的行及其行号35 36[实践-替换URL中的IP和Port]37 # jdbc.url=jdbc:mysql://192.168.1.1:3306/mydatabase38 sed -i "s/\([0-9]+\.[0-9]+\.[0-9]+\.[0-9]+\)/${NEW_IP}/" config.properties39 sed -i "s/\([0-9]\{1,5\}\)/${NEW_PORT}/" config.properties
awk-文本行处理
311[DESC]2 一个强大的文本分析工具,简单来说 awk 就是把文件或者标准输入逐行读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。3 4[FORMAT]5 awk [选项] '模式 {动作}' [文件]6 7[OPTIONS]8 ● -F:指定字段分隔符,默认为任意空白字符(空格或制表符)9 ● -f:从文件中读取 awk 程序。10 ● -v:定义变量的初始值。11
12[内置变量]13 ● $0 # 当前行的完整内容。14 ● $1, $2, ... # 当前行的字段(以字段分隔符分割)。15 ● NF # 当前行的字段数。16 ● NR # 当前行的行号。17 ● FS # 字段分隔符,默认为空白字符。18 ● RS # 记录分隔符,默认为换行符。19 ● OFS # 输出字段分隔符,默认为空白字符。20 ● ORS # 输出记录分隔符,默认为换行符。21
22[EXAMPLE]23 ● awk '{print}' data.txt # 打印整个文件24 ● awk -F',' '{print $2}' data.txt # 打印第 2 列,以逗号分隔25 ● awk -F',' '{print $1, $3}' data.txt # 打印第 1 列和第 3 列26 ● awk -F',' '$2 > 2' data.txt # 打印第 2 列大于2的行27 ● awk 'NR % 2 == 1' data.txt # 打印行号为奇数的行28 ● awk 'END {print NR}' data.txt # 统计文件中的行数29 ● awk -F',' '{print NF}' data.txt # 计算每行的字段数30 ● awk -F":" '{ print "user: " $1 " uid:" $3 }' /etc/passwd # 以:分割,获取第1,3项拼接打印31 ● awk '{if(NR>=2 && NR<=5) print $0}' /etc/passwd # 筛选第2~5行进行打印
7. 用户管理
id-查看用户ID/组ID
221[DESC]2 用于显示用户和用户组的详细信息,包括用户标识(UID)、组标识(GID)以及所属的用户组信息。3 4[FORMAT]5 id [选项] [用户名]6 7[OPTIONS]8 ● -u:仅显示用户 ID(UID)。9 ● -g:仅显示用户的主要组 ID(GID)。10 ● -G:显示用户所属的所有组 ID(包括主要组和附加组)。11 ● -n:与 -u、-g 或 -G 选项结合使用时,显示用户名或组名,而不是 ID。12 ● -a:显示所有信息(默认行为)。13 14[EXAMPLE]15 ● id # 显示当前用户的详细信息16 ● id huangyuanxin # 显示指定用户的详细信息 17
18[root@vm-20-5-centos ~]# id root19uid=0(root) gid=0(root) groups=0(root)20
21[root@vm-20-5-centos ~]# id huangyuanxin22uid=1000(huangyuanxin) gid=1000(huangyuanxin) groups=1000(huangyuanxin),10(wheel)
useradd-新建用户
411[DESC]2 用于创建新用户。3 4[FORMAT]5 useradd [选项] 用户名6 7[OPTIONS]8 ● -c:添加用户注释(如用户的真实姓名或描述信息)。9 ● -d:指定用户的家目录(默认为 /home/用户名)。10 ● -e:设置用户账户的过期日期(格式为 YYYY-MM-DD)。11 ● -f:设置密码失效日期(天数,-1 表示密码永不过期)。12 ● -g:指定用户的主要用户组(组名或 GID)。13 ● -G:指定用户所属的附加用户组(多个组用逗号分隔)。14 ● -m:自动创建用户的家目录(默认行为)。15 ● -M:不创建用户的家目录。16 ● -p:设置用户的密码(通常不推荐直接使用,因为密码会以明文形式存储)。17 ● -r:创建系统用户(通常用于服务账户,UID 通常小于 1000)。18 ● -s:指定用户的默认 Shell(默认为 /bin/bash 或 /bin/sh)。19 ● -u:指定用户的用户 ID(UID)。20
21[EXAMPLE]22 ● useradd hyx001 # 创建一个普通用户(默认创建家目录)23 ● useradd -r -s /bin/nologin myservice01 # 创建一个系统用户24 ● useradd -m -g developers -G sudo,adm hyx02 # 创建用户并指定用户组25
26[REMARK-注意事项] 27 ● 不建议使用 -p 选项设置明文密码,应在用户创建后需要使用 passwd 命令设置密码。28 ● 一般情况下,root 用户的 UID 和 GID 为 0,系统用户的 UID 小于 1000,普通用户的 UID 从 1000 开始。29 ● 如果不指定 -u 和 -g 选项,系统会自动分配默认的 UID 和 GID,通常和UID一致。30 31[REMARK-用户及用户组相关文件] 32 ● /etc/passwd # 用户账号信息文件33 ● /etc/shadow # 用户账号信息加密文件34 ● /etc/default/useradd # 定义默认设置文件35 ● /etc/login.defs # 系统广义设置文件36 ● /etc/skel # 默认的初始配置文件目录37 ● /etc/group # 用户组信息文件38 ● /etc/gshadow # 用户组信息加密文件39 40[REMARK-adduser命令]41 ● 用于创建新用户的工具,它与 useradd 命令类似,但通常提供更友好的交互界面和更灵活的配置选项。
userdel-删除用户
131[DESC]2 用于删除用户。3 4[FORMAT]5 userdel [选项] 用户名6
7[OPTIONS]8 ● -f:强制删除用户,即使用户的进程正在运行。9 ● -r:删除用户的同时,删除用户的家目录(默认为 /home/用户名)和邮件文件夹(默认为 /var/mail/用户名)。10
11[EXAMPLE]12 ● userdel hyx001 # 删除用户但保留家目录13 ● userdel -r hyx001 # 删除用户并删除家目录和邮件文件夹
passwd-修改用户密码
171[DESC]2 用于修改用户密码。3 4[FORMAT]5 passwd [选项] [用户名]6
7[EXAMPLE]8 ● passwd # 修改当前用户的密码9 ● passwd hyx001 # 修改指定用户的密码(新增的用户必须设置密码后才能登录)10 ● passwd -e hyx001 # 强制用户在下次登录时更改密码11 ● passwd -d hyx001 # 删除用户的密码12 ● passwd -l hyx001 # 锁定用户账户13 ● passwd -u hyx001 # 解锁用户账户14 ● passwd -n 7 -x 90 -w 7 -i 14 john # 设置密码使用期限。密码使用7~90天,提前7天提醒,过期后有14天宽限期。15
16[root@vm-20-5-centos hyx01]# passwd -S root17root PS 2024-06-19 0 99999 7 -1 (Password set, MD5 crypt.)
usermod-修改用户信息
331[DESC]2 用于修改用户信息。3 4[FORMAT]5 usermod [选项] 用户名6 7[OPTIONS]8 ● -a:追加用户到附加用户组(必须与 -G 选项一起使用)。9 ● -c:修改用户注释(如用户的真实姓名或描述信息)。10 ● -d:修改用户的家目录。11 ● -e:设置用户账户的过期日期(格式为 YYYY-MM-DD)。12 ● -f:设置密码失效日期(天数,-1 表示密码永不过期)。13 ● -g:修改用户的主要用户组。14 ● -G:修改用户所属的附加用户组。15 ● -l:修改用户名。16 ● -m:在修改家目录时,将旧家目录中的内容移动到新的家目录(必须与 -d 选项一起使用)。17 ● -s:修改用户的默认 Shell。18 ● -u:修改用户的用户 ID(UID)。19 ● -L:锁定用户账户(禁止用户登录)。20 ● -U:解锁用户账户(允许用户重新登录)。21 22[EXAMPLE]23 ● usermod -l hyx01 hyx001 # 修改用户名24 ● usermod -u 1500 hyx001 # 修改用户的用户UID(用户主目录下的所有文件都将自动修改UID,但主目录之外拥有的文件除外)25 ● usermod -s /bin/csh hyx001 # 修改用户默认shell(也可用 chsh 命令)26 ● usermod -d /home/hyx001_new hyx001 # 修改用户家目录27 ● usermod -d /home/hyx001_new -m hyx001 # 转移用户家目录28 ● usermod -g developers hyx001 # 修改用户的主要用户组29 ● usermod -G sudo,adm hyx001 # 修改用户所属的附加用户组30 ● usermod -a -G sudo hyx001 # 追加用户到附加用户组31 ● usermod -L hyx001 # 锁定用户账户32 ● usermod -U hyx001 # 解锁用户账户33 ● usermod -e 12/30/2029 hyx001 # 修改账号的有效期
groupadd-新增用户组
181[DESC]2 用于创建用户组。3 4[FORMAT]5 groupadd [选项] 组名6
7[OPTIONS]8 ● -f:如果组已经存在,则不报错并退出。如果组不存在,则创建组。9 ● -g:指定组 ID(GID)。如果不指定,系统会自动分配一个未使用的 GID。10 ● -r:创建系统组(通常用于服务账户,GID 通常小于 1000)。11 ● -K:覆盖默认的 GID 范围(通常用于自定义 GID 范围)。12 ● -o:允许创建具有重复 GID 的组(不推荐,除非有特殊需求)。13
14[EXAMPLE]15 ● groupadd g01 # 创建一个普通用户组16 ● groupadd -r sysadmins # 创建一个系统组,GID 通常小于 100017 ● groupadd -g 1500 mygroup # 建一个指定 GID 的用户组18 ● groupadd -f mygroup # 创建一个组,即使组已存在也不报错
groupdel-删除用户组
111[DESC]2 用于删除用户组。3 4[FORMAT]5 groupdel [选项] 组名6 7[OPTIONS]8 ● -f # 不能直接删除用户的主组,如需强制删除需添加 -f 选项9 10[EXAMPLE]11 ● groupdel g01 # 删除用户组
groupmod-修改用户组信息
91[DESC]2 用于修改用户组(组ID、组名等)。3 4[FORMAT]5 groupmod [选项] 组名6
7[EXAMPLE]8 ● groupmod -g 666 g01 # 修改用户组的 GID9 ● groupmod -n g001 g01 # 修改用户组的名称
gpasswd-管理用户组成员
61[DESC]2 用于管理用户组的密码和成员关系(组密码使用较少,略)。3
4[EXAMPLE]5 ● gpasswd -a hyx001 g01 # 将用户添加到组6 ● gpasswd -d hyx001 g01 # 从组中删除用户
su-切换用户
241[DESC]2 用于切换用户身份。 3 4 注:5 1. su为swith user的简称,使用权限为所有用户,但除 root 外,其它用户切换身份需要键入该使用者的密码。6 2. openEuler操作系统中,普通用户不支持切换至 root 用户。 7
8[OPTIONS]9 ● - 或 -l 或 --login:以目标用户的登录环境启动新的 Shell,加载目标用户的环境变量(如 .bashrc 或 .profile)。10 ● -c 或 --command:执行指定的命令后立即退出,不切换到目标用户的 Shell。11 ● -s 或 --shell:指定要使用的 Shell,而不是目标用户的默认 Shell。12 ● -m 或 -p 或 --preserve-environment:保留当前用户的环境变量,不加载目标用户的环境变量。13
14[EXAMPLE]15 ● su # 切换到 root 用户16 ● su root # 切换到 root 用户17 ● su - root # 切换到 root 用户,且 shell 环境也切换为 root 用户18 ● su - huangyuanxin # 切换 huangyuanxin 用户19 ● su - john -c "ls -l" # 以指定用户执行单个命令20 ● su -m john # 保留当前环境变量切换用户21
22[REMARK-注意事项]23 ● 切换到 root 用户或执行需要 root 权限的命令时,需要输入目标用户的密码(通常是 root 密码)24 ● 使用 su 时,建议使用 - 或 --login 选项,以确保加载目标用户的完整环境。
newgrp-切换用户组
51[DESC]2 用于切换当前用户所属的活动组(active group),以便具有其他用户组的权限。3
4[EXAMPLE]5 ● newgrp g02 # 切换当前用户到组g02
8. 权限管理
sudo-以root用户身份执行命令
101[DESC]2 以超级用户(root)或其他用户的身份执行命令。3 4[EXAMPLE]5 ● sudo -l 列出目前的SUDO权限6 ● sudo ls 以 root 身份执行 ls 命令7 ● sudo -u hyx01 ls -l 以 hyx01 用户的身份执行 ls -l 命令8
9[REMARK-注意事项]10 ● 哪些用户可以使用sudo命令由 /etc/sudoers 文件控制(推荐使用visudo命令编辑)。
chmod-修改文件/目录权限
351[DESC]2 用于修改文件或目录权限。3 4[FORMAT]5 chmod [选项] 权限数和 文件或目录6 chmod [选项] 权限符号 文件或目录7
8[OPTIONS]9 ● -R:递归更改目录及其所有子目录和文件的权限。10 11[EXAMPLE]12 ● chmod 765 file01 # 修改文件的权限为“rwxrw_r_x”。13 ● chmod +x file01 # 添加执行权限14 ● chmod -x file01 # 移除执行权限15 ● chmod =x file01 # 添执行权限,并删除其它所有权限16 ● chmod u=rwx,g=rx,o=r file01 # 属主添加rwx权限,属组添加rx权限,其它用户添加r权限17 ● chmod a+x file01 # 属主/属组/其它用户都添加执行权限18 ● chmod -R 644 ./bin # 递归更改权限19 ● chmod --reference=ref_file file.txt # 将目标文件的权限设置为与指定文件相同的权限20
21[REMARK-特殊权限-SUID]22 set_uid:仅针对可执行文件,表现为属主的x权限变为s,其它用户以属主的身份执行该命令,如passwd、sudo等命令。23 ● chmod u+s /usr/bin/ls # 修改ls命令的属主x权限为s,其它用户将以root身份执行该命令,如可查看/root目录24 ● chmod u-s /usr/bin/ls # 去掉ls命令的s权限25 ● chmod u=rws /usr/bin/ls # 设置ls命令的执行权限为S(但是没有x权限)26 27[REMARK-特殊权限-SGID]28 set_gid:针对可执行文件,表现为属组的x权限变为s,其它用户以属组的身份执行该命令,如locate等命令。29 ● chmod g+s /usr/bin/ls # 修改ls命令的属组x权限为s30 针对目录,则任何用户在该目录下新建的目录或文件所属组跟该目录是一样的31 ● chmod g+s ./abc # 修改abc目录的属组x权限为s,在其下建立的所有文件或目录属组都将与该目录的属组一致32
33[REMARK-特殊权限-SBIT]34 stick_bit:防止删除非当前用户的目录/文件(root用户除外,可随意删),如“drwxrwxrwt. 46 root root 12288 7月 1 11:05 tmp”35 ● chmod o+t /tmp # 为/tmp目录添加SBIT权限,防止删掉非当前用户的文件
chown-修改文件属主/属组
251[DESC]2 用于更改文件或目录的所有者(属主)和所属组(属组)。3 4[FORMAT]5 chown [选项] 新属主[:新属组] 文件或目录6 7[OPTIONS]8 ● -c:显示详细信息,仅在权限实际更改时显示。9 ● -f:静默模式,不显示错误信息。10 ● -h:仅更改符号链接本身的所有者,而不是链接指向的目标文件的所有者。11 ● -R:递归更改目录及其所有子目录和文件的所有者。12 ● --from=旧属主[:旧属组]:仅更改当前所有者为指定用户的文件或目录的所有者。13 ● -v:显示详细信息,显示每次更改的详细内容。14
15[EXAMPLE]16 ● chown hyx001 test.txt # 更改文件的所有者17 ● chown :g001 test.txt # 仅更改文件的所属组18 ● chown hyx001:g001 test.txt # 同时更改文件的所有者和所属组19 ● chown -R hyx001:g001 ./bin # 递归更改目录及其所有子目录和文件的所有者20 ● chown --from=olduser:newuser oldgroup:newgroup file.txt # 限定原属主和属组21
22[REMARK-chgrp命令]23 仅修改文件属组。24 ● chgrp g001 test.txt # 更改文件的所属组25 ● chgrp -R g001 ./bin # 递归更改目录及其所有子目录和文件的所属组
umask-查看/修改文件权限掩码
251[DESC]2 umask是一个命令和环境变量,用于控制新创建文件和目录的默认权限,即从完全权限中“屏蔽”掉某些权限。3 4[FORMAT]5 umask [-S][权限掩码]6 7[OPTIONS]8 ● -S 以文字的方式来表示权限掩码。9 10[EXAMPLE]11 ● umask # 获取当前权限掩码,如“0022”。12 ● umask 002 # 临时设置 umask 值,仅对当前终端会话有效。13 ● echo 'umask 002' >> ~/.bashrc # 永久设置 umask 值,设置后:source ~/.bashrc14
15[REMARK-完全权限]16 ● 文件:666(所有用户都有读写权限)17 ● 目录:777(所有用户都有读、写和执行权限)18 19[REMARK-默认权限]20 当 umask 为 022 时:21 ● 文件默认权限:666 - 022 = 644(所有者读写,组和其他用户只读)22 ● 目录默认权限:777 - 022 = 755(所有者读写执行,组和其他用户读执行)23 当 umask 为 002 时:24 ● 文件默认权限:666 - 002 = 664(所有者和组读写,其他用户只读)25 ● 目录默认权限:777 - 002 = 775(所有者和组读写执行,其他用户读执行)
getfacl-查看 ACL 权限
251[DESC]2 用于显示文件或目录访问控制列表(ACL),提供了比传统 Unix 文件权限更细粒度的权限控制,允许为特定用户或组分配特定权限。3 4[FORMAT]5 getfacl [选项] 文件或目录名6 7[OPTIONS]8 ● -a 或 --access:显示文件的 ACL 策略(默认行为)。9 ● -d 或 --default:显示目录的默认 ACL 策略。10 ● -c 或 --omit-header:不显示注释标题。11 ● -e 或 --all-effective:显示所有有效权限。12 ● -n 或 --numeric:以数字形式显示用户 ID 和组 ID。13 ● -t 或 --omit-acl-header:不显示 ACL 的头部信息。14 ● -R 或 --recursive:递归处理所有子文件。15 ● -L 或 --logical:跟随符号链接,显示链接目标的 ACL。16 ● -P 或 --physical:不跟随符号链接,显示链接本身的 ACL(默认行为)。17 ● -h 或 --help:显示帮助信息。18 ● -v 或 --version:显示版本信息。19
20[EXAMPLE]21 ● getfacl a.txt # 查看文件的 ACL22 ● getfacl -d directory # 查看目录的默认 ACL23 ● getfacl -R directory # 递归查看目录及其子文件的 ACL24 ● getfacl -t file.txt # 以表格形式显示 ACL25 ● getfacl -e file.txt # 显示有效权限
setfacl-设置 ACL 权限
411[DESC]2 用于设置文件或目录访问控制列表(ACL)注意:需确保文件系统支持 ACL(如 ext4、XFS),可以通过 mount | grep acl 命令检查。3 4[FORMAT]5 setfacl [-bkRd] [{-m|-x} acl参数] 文件/目录名6
7[OPTIONS]8 ● -m:修改(添加或修改)ACL 条目。9 ● -x:删除指定的 ACL 条目。10 ● -b:删除所有扩展的 ACL 条目(保留基本权限)。11 ● -d 或 --default:设置默认 ACL(仅对目录有效)。12 ● -k 或 --remove-default:移除默认 ACL。13 ● -R 或 --recursive:递归设置 ACL。14 ● -L 或 --logical:跟随符号链接,设置链接目标的 ACL。15 ● -P 或 --physical:不跟随符号链接,设置链接本身的 ACL(默认行为)。16 ● -n 或 --no-mask:不自动更新掩码(mask)。17 ● -M 或 -X:从文件中读取 ACL 条目。18 ● -v 或 --version:显示版本信息。19 ● -h 或 --help:显示帮助信息。20 21[EXAMPLE]22 ● setfacl -m u:kimi:rw- file.txt # 给指定用户增加权限23 ● setfacl -x u:kimi file.txt # 给指定用户删除权限24 ● setfacl -m g:developers:r-- file.txt # 给指定用户组设增加权限25 ● setfacl -m d:u:kimi:rw- directory # 给目录设置默认 ACL 权限26 ● setfacl -R -m u:kimi:rw- directory # 递归设置 ACL 权限27 ● setfacl -b file.txt # 移除所有扩展的 ACL,但保留基本权限28 ● setfacl -m mask::rwx directory # 设置掩码29
30[REMARK-ACL权限的备份与恢复]31 ● getfacl -R acldir > acldir.acl # 备份acldir目录及其子文件的ACL权限到acldir.acl文件中32 ● setfacl -R -b acldir # 删除acldir目录的所有权限33 ● setfacl --restore acldir.acl # 从acldir.acl文件恢复ACL权限34
35[EXAMPLE-关于权限掩码]36 ● 掩码限制了所有用户的最大权限。例如,如果掩码为 r-x,则用户即使被设置了 rw- 权限,实际也只会获得 r-x 权限。37 ● 默认 ACL 仅对目录有效,新创建的文件或目录会继承这些默认权限。38 ● 默认情况下,setfacl 不会修改符号链接的目标文件。如果需要修改目标文件的 ACL,可以使用 -L 选项。39 40[EXAMPLE-chacl命令]41 用于更改文件或目录访问控制列表(ACL),主要用于 IRIX 和 XFS 文件系统的兼容性场景。
9. 服务管理
rpm-RedHat系列二进制包工具
121[DESC]2 rpm(Red Hat Package Manager)是 Red Hat 及其衍生发行版(如:CentOS等)中用于管理和操作 .rpm 包的命令行工具。3
4[EXAMPLE]5 ● rpm -i package.rpm # 安装 RPM 包6 ● rpm -i --nodeps package.rpm # 强制安装包(忽略依赖关系)7 ● rpm -U package.rpm # 升级 RPM 包8 ● rpm -qa | grep lvm2 # 查询已安装的包9 ● rpm -e package # 删除已安装的包10 ● rpm -ql package # 列出包中的文件11 ● rpm -qi package # 显示包的详细信息12 ● rpm -V package # 验证已安装的包是否与原始包一致
dpkg-Debian系列二进制包工具
121[DESC]2 dpkg(Debian Package Manager)是 Debian 及其衍生发行版(如:Ubuntu等)中用于管理和操作 .deb 包的命令行工具。3
4[EXAMPLE]5 ● dpkg -i xxx.deb # 安装deb软件包命令6 ● dpkg -r xxx.deb # 删除软件包命令7 ● dpkg -r --purge xxx.deb # 连同配置文件一起删除命令8 ● dpkg -info xxx.deb # 查看软件包信息命令9 ● dpkg -L xxx.deb # 查看文件拷贝详情命令10 ● dpkg -l # 查看系统中已安装软件包信息命令11 ● dpkg-reconfigure xxx # 重新配置软件包命令12
yum-rpm包管理工具
451[DESC]2 yum(Yellowdog Updater Modified)是一个基于 RPM 的包管理工具,用于在基于 Red Hat 的 Linux 发行版(如 CentOS、Fedora 和 RHEL)中安装、更新、查询和删除软件包。3 4 它提供了自动处理依赖关系的功能,并且可以管理软件仓库(repositories),使得软件包的管理更加方便和高效。5
6[EXAMPLE]7 # 安装/更新8 ● yum install package_name # 安装单个包9 ● yum install package1 package2 # 安装多个包10 ● yum update package_name # 更新单个包11 ● yum update # 更新所有已安装的包12 13 # 移除14 ● yum remove package_name # 移除单个包15 ● yum remove package1 package2 # 移除多个包16 17 # 查看/搜索18 ● yum list available # 列出所有可用的包19 ● yum list installed # 列出所有已安装的包20 ● yum list updates # 列出所有可更新的包21 ● yum search keyword # 搜索包含特定关键字的包22 ● yum info package_name # 显示包信息23 24 # 下载25 ● yumdownloader --resolve --destdir=./ freetds26 27 # 其它28 ● yum clean all # 清理所有缓存29 ● yum makecache # 刷新软件仓库30 ● yum groupinstall "Group Name" # 安装软件组31 ● yum groupremove "Group Name" # 移除软件组32 ● yum history # 查看 yum 操作历史33
34[REMARK-配置]35 ● 配置文件:/etc/yum.conf36 ● 源目录:/etc/yum.repos.d/*.repo37
38[REMARK-换源]39 ● yum -y install wget # 安装wget40 ● cd /etc/yum.repos.d/ # 进入yum源目录下41 ● mv CentOS-Base.repo CentOS-Base.repo.bak # 重命名yum源42 ● wget http://mirrors.163.com/.help/CentOS7-Base-163.repo # 下载yum源(需联网;备用:http://mirrors.aliyun.com/repo/Centos-7.repo)43 ● mv CentOS7-Base-163.repo CentOS-Base.repo # 将下载的yum源的名修改为系统默认的yum源名称44 ● yum makecache # 生成yum缓存45 ● yum -y update # 更新yum源包
apt-get-deb包管理工具
401[DESC]2 apt-get 是 Debian 及其衍生发行版(如 Ubuntu、Linux Mint 等)中用于管理和操作软件包的命令行工具。3 4 它可以自动处理依赖关系,并且可以管理软件仓库(repositories),使得软件包的管理更加方便和高效。5
6[EXAMPLE]7 # 安装/更新8 ● apt-get install package_name # 安装软件包9 ● apt-get install <package_name> --reinstall # 重新安装包10 ● apt-get -f install # 修复安装11 ● apt-get install --install-recommends package_name # 安装软件包及其推荐的依赖包12 ● apt-get update # 更新软件包列表13 ● apt-get upgrade # 升级所有已安装的软件包14 15 # 移除16 ● apt-get remove package_name # 移除已安装的软件包17 ● apt-get purge package_name # 彻底移除已安装的软件包(包括配置文件)18 ● apt-get autoremove # 自动移除不再需要的依赖包19
20 # 查看/搜索 21 ● apt-get search keyword # 搜索包含特定关键字的软件包22 ● apt-get show package_name # 显示软件包信息23
24 # 其它: 25 ● apt-get clean # 清理本地缓存26 ● apt-get autoclean # 清理本地缓存中不再需要的部分文件27 28[REMARK-配置]29 ● 配置文件:/etc/apt/sources.list30 ● 源目录:/etc/apt/sources.list.d/31 32[REMARK-换源]33 cp /etc/sources.list /etc/apt/sources.list.bak # 备份原有源34 vim /etc/apt/sources.list # 打开源配置文件,准备替换源35 # 修改文件替换为清华大学的apt-get源36 deb https://mirrors.t.tsinghua.edu.cn/ubuntu/ial main restricted universe multiverse37 deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse38 deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse39 deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted universe multiverse40 apt-get update # 刷新源
dnf-新一代rpm包管理工具
711[DESC]2 dnf(Dandified YUM)是新一代的软件包管理器,用于在基于 Red Hat 的 Linux 发行版(如 Fedora、CentOS 和 RHEL)中安装、更新、卸载软件包。3 4 它是 yum 的替代品,旨在解决 yum 的一些性能瓶颈。5
6[EXAMPLE]7 # DNF配置8 ● dnf config-manager --dump # 显示dnf配置信息9 ● dnf repolist # 查询RepoId10 ● dnf config-manager --dump <RepoId> # 查看指定软件源配置(RepoId支持正则表达式)11 12 # 查看RPM包信息 13 ● dnf search httpd # 搜索RPM包(使用RPM包名称、缩写或者描述搜索)14 ● dnf info httpd # 显示软件包信息15 ● dnf list all # 列出系统中所有已安装的以及可用的RPM包(dnf list)16 ● dnf list <glob_expression> # 列出系统中指定的RPM包17 ● dnf info httpd # 显示RPM包详细信息18 19 # 在线安装软件包20 ● dnf install httpd # 安装httpd21 ● dnf install httpd tree --setopt=strict=0 # 同时安装httpd和tree多个软件包22 23 # 下载软件包24 ● dnf download httpd # 下载httpd软件包25 ● dnf download --resolve httpd # 下载httpd软件包及未安装的依赖 26 27 # 删除软件包28 ● dnf remove httpd # 删除httpd29 ● dnf purge httpd # 彻底删除httpd(包括配置文件)30 ● dnf autoremove # 自动移除孤立的依赖包31 32 # 软件包组33 ● dnf groups summary # 列出系统中所有已安装软件包组、可用的组,可用的环境组的数量34 ● dnf group list # 列出所有软件包组和它们的组 ID35 ● dnf group info "Development Tools" # 列出Development Tools包组信息36 ● dnf group install "Development Tools" # 安装包组(通过包组名)37 ● dnf group install development # 安装包组(通过包组ID)38 ● dnf group remove "Development Tools" # 删除包组(通过包组名) 39 ● dnf group remove development # 删除包组(通过包组ID)40 41 # 检查更新42 ● dnf check-update # 显示当前系统可用的更新43 ● dnf update anaconda-gui.aarch64 # 升级 anaconda-gui.aarch6444 ● dnf group update <group_name> # 升级包组45 ● dnf update # 更新所有的包和它们的依赖46
47 # 其它48 ● dnf clean all # 清理缓存49
50[REMARK-配置]51 ● 配置文件:/etc/dnf/dnf.conf52 53[REMARK-常用软件源] 使用 root 权限在 /etc/yum.repos.d/openEuler_aarch64.repo 文件中添加 openEuler repo 源:54 [OS]55 name=openEuler-$releasever - OS56 baseurl=https://repo.openEuler.org/openEuler-20.03-LTS/OS/$basearch/57 enabled=158 gpgcheck=159 gpgkey=https://repo.openEuler.org/openEuler-20.03-LTS/OS/$basearch/RPM-GPG-KEY-openEuler60 [update]61 name=openEuler-$releasever - Update62 baseurl=http://repo.openEuler.org/openEuler-20.03-LTS/update/$basearch/63 enabled=164 gpgcheck=165 gpgkey=http://repo.openEuler.org/openEuler-20.03-LTS/update/$basearch/RPM-GPG-KEY-openEuler66 [extras]67 name=openEuler-$releasever - Extras68 baseurl=http://repo.openEuler.org/openEuler-20.03-LTS/extras/$basearch/69 enabled=070 gpgcheck=171 gpgkey=http://repo.openEuler.org/openEuler-20.03-LTS/extras/$basearch/RPM-GPG-KEY-openEuler
service-基于 sysvinit 的服务管理命令
271[DESC]2 用于管理和控制系统服务(守护进程),允许用户启动、停止、重启和查询服务的状态。3 4 通常用于传统的 System V init 系统,但在许多现代 Linux 发行版中,systemctl 已逐渐取代了 service,成为管理服务的主要工具。5
6[EXAMPLE]7 # 查看服务状态8 ● service network status # 检查服务的运行状态。9 ● chkconfig network # 用来检查一个服务在当前环境下被配置为启用还是禁用。10 11 # 运行和关闭服务 12 ● service network start # 用来启动一个服务 (并不会重启现有的)。13 ● service network stop # 用来停止一个服务 (并不会重启现有的)。14
15 # 重启服务16 ● service network restart # 用来停止并启动一个服务。17 18 # 启用和禁用服务19 ● chkconfig network on # 在下次启动时或满足其他触发条件时设置服务为启用。20 ● chkconfig network off # 在下次启动时或满足其他触发条件时设置服务为禁用。21
22 # 其它功能23 ● service network reload # 当支持时,重新装载配置文件而不中断等待操作。24 ● service network condrestart # 如果服务正在运行那么重启它。25 ● chkconfig --list # 输出在各个运行级别下服务的启用和禁用情况。26 ● chkconfig network –list # 用来列出该服务在哪些运行级别下启用和禁用。27 ● chkconfig network –add # 当您创建新服务文件或者变更设置时使用。
systemctl-基于 systemd 的服务管理命令
411[DESC]2 systemctl 是现代 Linux 系统中用于管理系统服务(守护进程)和系统状态的核心工具。3 4 它是 systemd 系统和服务管理器的一部分,提供了强大的功能来管理服务、单元文件、系统启动目标等。5 6 systemctl 替代了传统的 service 和 chkconfig 命令,成为现代 Linux 发行版中管理服务的标准工具。7 8 9[EXAMPLE]10 # 查看服务状态11 ● systemctl status network.service # 检查服务的运行状态。12 ● systemctl is-enabled network.service # 用来检查一个服务在当前环境下被配置为启用还是禁用。13 14 # 运行和关闭服务 15 ● systemctl start network.service # 用来启动一个服务 (并不会重启现有的)。16 ● systemctl stop network.service # 用来停止一个服务 (并不会重启现有的)。17
18 # 重启服务19 ● systemctl restart network.service # 用来停止并启动一个服务。20 21 # 启用和禁用服务22 ● systemctl enable network.service # 启用服务(开机自启)23 ● systemctl disable network.service # 禁用服务(取消开机自启)24
25 # 系统管理26 ● systemctl halt # 关闭系统27 ● systemctl poweroff # 关闭电源(关闭系统并下电,会给给当前所有的登录用户发送一条提示消息)28 ● systemctl --no-wall poweroff # 关闭电源,并不发送上述消息29 ● systemctl reboot # 重启系统(会给当前所有的登录用户发送一条提示消息)30 ● systemctl --no-wall reboot # 重启系统,并不发送上述消息31 ● systemctl suspend # 使系统待机32 ● systemctl hibernate # 使系统休眠33 ● systemctl hybrid-sleep # 使系统待机且处于休眠状态34 35 # 其它功能36 ● systemctl reload network.service # 当支持时,重新装载配置文件而不中断等待操作。37 ● systemctl condrestart network.service # 如果服务正在运行那么重启它。38 ● systemctl list-unit-files --type=service # 输出在各个运行级别下服务的启用和禁用情况。39 ● ls /etc/systemd/system/*.wants/network.service # 用来列出该服务在哪些运行级别下启用和禁用。40 ● systemctl daemon-reload # 当您创建新服务文件或者变更设置时使用。41
10. 存储管理
逻辑卷管理(LVM)
逻辑卷管理(LVM,Logical Volume Manager)是 Linux 环境下对磁盘分区进行管理的一种机制。它通过在磁盘和文件系统之间添加一个逻辑层,来为文件系统屏蔽下层磁盘分区布局,提高磁盘分区管理的灵活性。
使用 LVM 管理磁盘的基本过程如下:
1) 物理存储:存储系统最低层的存储单元,如hda~hdd(IDE磁盘)、sda~sdz(SCSI/SATA/USB磁盘)、vda(virtio磁盘)、fda(软驱)等。
2) 磁盘分区(fdisk):1个磁盘最多可划分4个主分区(或3个主分区+1个扩展分区),命名为sda1~sda4;其中扩展分区又可划分多个逻辑分区,从sda5开始命名。
3) 物理卷(pvcreate):指磁盘分区或从逻辑上与磁盘分区具有同样功能的设备(如RAID),可由物理存储直接创建,也可由多个磁盘分区组合,命名和磁盘分区类似。
特殊标签:包含物理卷的随机唯一识别符(UUID),记录块设备的大小和 LVM 元数据在设备中的存储位置。
物理块:物理卷以大小相等的“块”为单位存储,块的大小与卷组中逻辑卷块的大小相同。
卷组(vgcreate):多个物理卷组合(可跨磁盘),屏蔽了底层物理卷细节。
逻辑卷(lvcreate):卷组不能直接用,需要划分成逻辑卷才能使用。逻辑卷可以格式化成不同的文件系统,挂载后直接使用。
逻辑块:逻辑卷以“块”为单位存储,在一卷组中的所有逻辑卷的块大小是相同的。
fdisk-管理分区
21fdisk -l # 查看磁盘及分区2fdisk /dev/sda # 管理分区(m-查看菜单 n-新建分区 d-删除分区 t-设置分区类型)
pvXxxx-管理物理卷
51pvcreate /dev/sdb /dev/sdc # 将磁盘创建为物理卷(-f 强制创建 -u 指定设备的UUID -y 所有问题回答yes)2pvcreate /dev/sdb1 /dev/sdb2 # 将磁盘分区创建为物理卷3pvdisplay /dev/sdb # 显示物理卷的基本信息(要求分区类型为8e-Linux LVM)(-s 以短格式输出 -m 显示PE到LE的映射)4pvchange -x n /dev/sdb # 禁止分配/dev/sdb 物理卷上的PE(-u 生成新的UUID -x 是否允许分配PE)5pvremove /dev/sdb # 删除物理卷(-f 强制删除 -y 所有问题回答yes)
vgXxxx-管理卷组
111vgcreate vg1 /dev/sdb /dev/sdc # 创建卷组:创建卷组vg1,并且将物理卷/dev/sdb 和/dev/sdc 添加到卷组中2 -l 卷组上允许创建的最大逻辑卷数 3 -p 卷组中允许添加的最大物理卷数 4 -s 卷组上的物理卷的 PE 大小5vgdisplay vg1 # 查看卷组:显示卷组 vg1 的基本信息(-s 以短格式输出 -A 仅显示活动卷组的属性)6vgchange -ay vg1 # 修改卷组属性:将卷组 vg1 状态修改为活动(-a 设置卷组的活动状态)7vgextend vg1 /dev/sdb # 扩展卷组:将卷组 vg1 中添加物理卷/dev/sdb(-d 调试模式 -t 仅测试)8vgreduce vg1 /dev/sdb2 # 收缩卷组:从卷组 vg1 中移除物理卷/dev/sdb29 -a 删除所有的空物理卷 10 --removemissing 删除卷组中丢失的物理卷,使卷组恢复正常状态11vgremove vg1 # 删除卷组:删除卷组 vg1(-f 强制删除)
lvXxxx-管理逻辑卷组
111lvcreate -L 10G -n lv1 vg1 # 在卷组 vg1 中创建 10G 大小的逻辑卷2 -L 指定逻辑卷的大小,单位为“kKmMgGtT”字节。3 -l 指定逻辑卷的大小(LE 数)。4 -n 指定要创建的逻辑卷名称。5 -s 创建快照。6lvdisplay /dev/vg1/lv1 # 显示逻辑卷 lv1 的基本信息(-v 显示LE到PE的映射)7lvresize -L +200 /dev/vg1/lv1 # 为逻辑卷/dev/vg1/lv1 增加 200M 空间(-L 指定逻辑卷字节大小 -l 指定逻辑卷的大小(LE数) -f 强制调整)8lvresize -L -200 /dev/vg1/lv1 # 为逻辑卷/dev/vg1/lv1 减少 200M 空间(注意:可能导致数据丢失)9lvextend -L +100M /dev/vg1/lv1 # 动态在线扩展逻辑卷的空间大小,而不中断应用程序对逻辑卷的访问(-L -l -f)10lvreduce -L -100M /dev/vg1/lv1 # 减少逻辑卷占用的空间大小(注意:可能会删除逻辑卷上已有的数据)(-L -l -f)11lvremove /dev/vg1/lv1 # 删除逻辑卷/dev/vg1/lv1(注意:被挂载的逻辑卷不能被删除)(-f 强制删除)
mkfs-创建文件系统
21mkfs -t ext4 /dev/vg1/lv1 # 在逻辑卷 /dev/vg1/lv1 上创建 ext4 文件系统(-t 指定系统类型ext2(默认)/ext3/ext4等)2
mount-挂载文件系统
111# 临时挂载/卸载2mount /dev/vg1/lv1 /mnt/data # 将逻辑卷/dev/vg1/lv1 挂载到/mnt/data 目录(临时挂载,重启失效)3umount /dev/vg1/lv1 # 卸载逻辑卷4
5# 自动挂载6blkid /dev/vg1/lv1 # 查询逻辑卷的UUID和TYPE(需先在逻辑卷创建文件系统),如:/dev/vg1/lv1: UUID="ccbe203f-544a-4e89-b3b3-6753d4628da1" TYPE="ext4"7vim /etc/fstab # 配置fstab文件,追加一行:UUID=ccbe203f-544a-4e89-b3b3-6753d4628da1 /mnt/lv1 ext4 defaults 0 08 各字段分别表示:blkid命令查询的UUID、挂载目录、文件系统类型 、挂载选项、是否自动对该文件系统进行备份、在启动时自动对该文件系统进行扫描)9mount -a # 重新加载fstab文件10mount | grep /mnt/ # 查询文件系统挂载信息,如:/dev/mapper/vg1-lv1 on /mnt/lv1 type ext4 (rw,relatime,seclabel)11
11. 其它命令
echo-回写文字
191[DESC]2 用于在终端输出文本或变量内容。3 4[FORMAT]5 echo [选项] [字符串]6 7[OPTIONS]8 ● -n:不输出换行符。9 ● -e:解释转义字符(如 \n、\t 等)。10 ● -E:禁用转义字符的解释(默认行为)。11 12[EXAMPLE]13 ● echo "Hello, World!" # 输出普通文本14 ● echo "My name is $name" # 输出变量内容15 ● echo "My name is ${name}" # 输出变量内容16 ● echo -n "Hello, " # 在最后不输出换行符17 ● echo -e "Hello,\nWorld!" # 解释转义字符18 ● echo -E "Hello,\nWorld!" # 禁用转义字符的解释19 ● echo "Hello, World!" > file.txt # 输出重定向到文件中
tee-显示程序的输出并将其复制到一个文件中
141[DESC]2 用于将命令的输出同时写入到标准输出(终端)和一个或多个文件中。3 4[FORMAT]5 command | tee [选项] [文件名]6
7[OPTIONS]8 ● -a 或 --append:将输出追加到文件,而不是覆盖文件。9 ● -i 或 --ignore-interrupts:忽略中断信号(如 Ctrl+C),确保 tee 命令继续运行。10
11[EXAMPLE]12 ● ls -l | tee output.txt # 将命令输出同时写入终端和文件13 ● ls -l | tee -a output.txt # 将输出追加到文件,而不是覆盖文件 14 ● ls -l | tee output1.txt output2.txt # 同时写入多个文件
clear-清除屏幕画面
51[DESC]2 用于清除终端屏幕上的内容,将光标移回屏幕顶部。3 4[EXAMPLE]5 ● clear # 清除终端屏幕,等效于快捷键 Ctrl+L
alias-设置命令别名
161[DESC]2 用于创建命令的别名。3
4[EXAMPLE]5 ● alias ll='ls -l' # 创建一个简单的别名6 ● alias grep='grep --color=auto' # 创建一个带参数的别名7 ● alias update='sudo apt-get update && sudo apt-get upgrade -y' # 创建一个命令组合的别名8 ● echo "alias ll='ls -l'" >> ~/.bashrc # 别名永久生效9 ● alias # 查看所有别名10 ● alias ll # 查看特定别名11 ● unalias ll # 删除特定别名12 ● unalias -a # 删除所有别名13
14[REMARK-注意事项]15 ● 如果别名与系统命令冲突,别名会覆盖默认命令。16 ● 别名不支持直接传递参数。如果需要更复杂的参数处理,可以使用函数。
sync-将在内存的数据写回硬盘
81[DESC]2 用于刷新文件系统缓冲区,将内存中的数据同步到磁盘中。3 4[EXAMPLE]5 ● sync # 将所有挂载的文件系统的缓冲区数据同步到磁盘6 ● sync -v # 显示同步的详细信息7 ● sync -f /path/to/file # 同步指定文件的缓冲区8 ● sync -d /path/to/directory # 同步指定目录的缓冲区
expr-表达式计算
291[DESC]2 用于计算表达式的值,支持字符串操作、数值计算以及逻辑运算等功能。3 4 现代的 shell(如 Bash)提供了更强大的内置运算符(如 $((...)) 和 ${...})。5 6[EXAMPLE]7 # 算术运算8 ● expr 5 + 3 # 加法9 ● expr 10 - 4 # 减法10 ● expr 2 \* 3 # 乘法(注意:* 在 shell 中表示通配符,需要转义)11 ● expr 10 / 2 # 除法12 ● expr 10 % 3 # 取模13
14 # 字符串操作15 ● expr length "Hello, World" # 字符串长度16 ● expr "apple" = "apple" # 字符串比较17 ● expr "apple" != "orange" # 字符串比较18 ● expr "Hello, World" : "Hello, \(.*\)" # 提取子字符串19 20 # 逻辑运算21 ● expr 5 \> 3 # 大于22 ● expr 5 \< 3 # 小于23 ● expr 5 \> 3 \& 10 \> 5 # 逻辑与24 ● expr 5 \> 3 \| 10 \> 15 # 逻辑或25 26[REMARK-注意事项]27 ● 空格分隔:expr 命令要求操作符和操作数之间必须有空格。例如,expr 5+3 是错误的,应该写成 expr 5 + 3。28 ● 转义特殊字符:某些字符(如 *、>、< 等)在 shell 中有特殊含义,需要使用反斜杠 \ 进行转义。29 ● 返回值:expr 命令的返回值是一个字符串。如果需要在脚本中使用返回值,可以将其赋值给变量,例如:result=$(expr 5 + 3)。
nslookup-DNS解析
111[DESC]2 用于查询域名系统(DNS),帮助用户查看域名的 IP 地址、解析域名、查询 DNS 记录等信息。3 4[FORMAT]5 nslookup [选项] [域名或IP地址] [DNS服务器]6
7[EXAMPLE]8 ● nslookup baidu.com # 查询域名的 IP 地址9 ● nslookup 93.184.216.34 # 查询 IP 地址的反向解析10 ● nslookup -type=MX baidu.com # 查询特定类型的 DNS 记录11 ● nslookup -debug baidu.com # 显示调试信息
telnet-远程登录
91[DESC]2 连接到远程主机并登录 或 检查特定端口是否开放。3 4[FORMAT]5 telnet [选项] [主机名或IP地址] [端口号]6 7[EXAMPLE]8 ● telnet example.com # 远程登录到服务器,默认为23端口9 ● telnet example.com 80 # 连接到特定端口
help-查看内置命令的帮助信息
211[DESC]2 主要针对 Bash 的内部命令(如 cd、echo、for 等)提供简要的使用说明3 4[FORMAT]5 help [选项] [命令]6 7[OPTIONS]8 ● 无选项:列出所有可用的 Bash 内置命令。9 ● -d:显示每个内置命令的简短描述。10 ● -m:显示特定命令的完整帮助信息。11 ● -s:显示特定命令的简短语法。12 13[EXAMPLE]14 ● help # 列出所有 Bash 内置命令15 ● help cd # 显示特定命令的帮助信息16 ● help –d pwd # 显示简短描述17 ● help –s pwd # 显示简短语法18
19[REMARK]20 ● 许多外部命令支持 --help 选项,用于显示简要的帮助信息,如:ls --help。21
man-查看帮助信息
211[DESC]2 man 命令用于显示指定命令、函数或文件格式的手册页。手册页通常分为多个章节,每个章节对应不同类型的内容:3 1:可执行程序和 shell 命令。4 2:系统调用。5 3:库函数。6 4:特殊文件(通常是设备驱动程序)。7 5:文件格式和约定。8 6:游戏。9 7:杂项(包括宏包、约定等)。10 8:系统管理命令和守护进程。11 12[FORMAT]13 man [选项] [章节] 命令或主题14
15[EXAMPLE]16 ● man ls # 查看命令的手册页17 ● man 2 open # 查看特定章节的手册页18 ● man -k ls # 查找包含关键字的手册页19 ● man -f ls # 显示命令的简要描述20 ● man -a ls # 显示所有匹配的手册页21 ● man -w ls # 显示手册页的文件路径
12. GDB调试
1) GDB简介
GDB(GNU Debugger)是一个开源的、功能强大的调试工具,用于调试程序,帮助开发者查找和修复代码中的错误。
在编译时,可以通过-g参数生成调试信息,否则,将看不见程序的函数名、变量名,所代替的全是运行时的内存地址。
21gcc -g hello.c -o hello2g++ -g hello.cpp -o hello在启动程序时,可以通过 gdb 模式进行启动:
111# 通过 GDB 模式启动2gdb myProgram3
4# 设置运行参数5set args 10 20 30 40 50 # show args 可以查看设置好的运行参数6
7# 设置工作目录8cd /xxx/xxx # 可通过 pwd 命令查看当前的所在目录9
10# 运行程序11run # 简写为r
2) 设置断点
221# 查询所有断点2info b3
4# 单文件程序断点5break # 设置断点,可以简写为b6b 10 # 设置断点,在源程序第10行7b func # 设置断点,在func函数入口处8
9# 多文件程序断点10break filename:linenum # 在源文件filename的linenum行处停住11break filename:function # 在源文件filename的function函数的入口处停住12break class::function/function(type,type) # 在类class的function函数的入口处停住13break namespace::class::function # 在名称空间为namespace的类class的function函数的入口处停住14
15# 条件断点16b test.c:8 if intValue = 517
18# 启用/禁用/删除断点19delete 3-7 # 删除指定断点,默认空删除全部断点,简写为d20disable 3-7 # 禁用指定断点21enable 3-7 # 启用指定断点22
3) 调试代码
61run # 运行程序,可简写为r2next # 单步跟踪,函数调用当作一条简单语句执行,可简写为n3step # 单步跟踪,函数调进入被调用函数体内,可简写为s4finish # 退出进入的函数5until # 在一个循环体内单步跟踪时,这个命令可以运行程序直到退出循环体,可简写为u6continue # 继续运行程序,可简写为c
4) 查看变量
61print var1 # 打印变量、字符串、表达式等的值,可简写为p2display var1 # 设置自动显示变量(可通过 info display 查看设置自动显示的变量)3undisplay num # 关闭自动显示变量4delete display 2-5 # 删除自动显示变量5disable display # 禁用自动显示变量6enable display # 启用自动显示变量
5) 修改变量
21ptype var1 # 打印变量类型2set var var1=47 # 设置变量值
6) 显示源代码
51 list # 显示当前行后面的源程序2 list - # 显示当前行前面的源程序3 list linenum # 显示源代码,linenum为显示行数,默认为10,可通过 set listsize num1 和 show listsize 查看和设置4 list func1 # 显示函数名为function的函数的源程序5
第二节 Shell脚本
1. 快速入门
1) 什么是Shell?
Shell是在Linux内核的基础上编写的一个应用程序,它连接了用户和Linux内核,从而让用户能够更加便捷、高效、安全的使用Linux内核。
Shell脚本就是由Shell命令组成的可执行文件,将一些命令整合到一个文件中,进行处理业务逻辑,脚本不用编译即可运行。
2) 入门案例
一个简单的Shell脚本示例如下:
31echo hello3
可以使用./hello.sh(需要x权限)、. hello.sh、source hello.sh或sh hello.sh命令执行。
3) 脚本调试
Shell 提供了一些用于调试脚本的选项,如:
| 选项 | 作用 |
|---|---|
| -n | 读一遍脚本中的命令但不执行,用于检查脚本中的语法错误。 |
| -v | 一边执行脚本,一边将执行过的脚本命令打印到标准错误输出。 |
| -x | 提供跟踪执行信息,将执行的每一条命令和结果依次打印出来。 |
这些选项有三种常见的使用方法:
171# 1. 在命令行提供参数2sh -x ./script.sh3
4# 2. 在脚本开头提供参数5
7# 3. 在脚本中用 set 命令启用或禁用参数,这样可以只对脚本中的某一段进行跟踪调试8if [ -z "$1" ]; then10 # 启用-x参数11 set -x12 echo "ERROR: Insufficient Args."13 exit 114 # 禁用-x参数15 set +x16fi17
2. 变量
1) 变量类型
Shell中有三种类型的变量:
局部变量:在脚本或命令中定义的变量,仅在当前Shell实例中有效。
环境变量:可以在Shell实例之间共享的变量。
Shell变量:由Shell程序设置的特殊变量,可以是局部变量,也可以是环境变量。
2) 定义和使用变量
211# 定义变量2# 注意:变量名必须以字母开头,中间没有空格(可以使用下划线),且不能为bash的保留关键字!3name="hyx"4
5# 使用变量6echo $name7echo ${name}8echo ${var:-word} # 如果变量 var 为空或已被删除(unset),那么返回 word,但不改变var 的值9echo ${var:=word} # 如果变量 var 为空或已被删除(unset),那么返回 word,并将 var 的值设置为 word。10echo ${var:?message} # 如果变量 var 为空或已被删除(unset),那么将消息 message 送到标准错误输出,可以用来检测变量 var 是否可以被正常赋值。若此替换出现在 Shell 脚本中,那么脚本将停止运行。11echo ${var:+word} # 如果变量 var 被定义,那么返回 word,但不改变 var 的值。12
13# 变量只读14readonly name15
16# 删除变量(注意:不能删除只读变量)17unset name18
19# Local变量(只能在函数中定义和访问)20local name="hyx"21
3) 参数变量
| 变量 | 含义 |
|---|---|
$0 | 代表执行的文件名 |
$n | 代表传入的第n个参数,如$1 |
$# | 参数个数 |
$* | 以一个单字符串显示所有向脚本传递的参数 |
$@ | 与$*相同,但是使用时加引号,并在引号中返回每个参数 |
$$ | 脚本运行的当前进程号 |
$! | 后台运行的最后一个进程的ID |
$? | 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误 |
151# $*演示,结果为:3# 1 2 34for i in "$*"; do5 echo $i6done7
8# $@演示,结果为:9# 1 10# 2 11# 312for i in "$@"; do13 echo $i14done15
使用参数时一般需判断参数是否存在(注意$1需要加双引号)。
51if [ -n "$1" ]; then2 echo "包含第一个参数"3else4 echo "没有包含第一参数"5fi
4) 字符串
351# 不支持转义的字符串变量(特殊的,可以跨行,即文本块)2str01='test'3echo 'abc4> cde'5
6# 支持转义的字符串变量(会解析${}变量和转义字符)7str02="str01 is ${str01}" 8
9# 转义字符10echo \$SHELL # $SHELL11echo \\ # \12touch \$\ \$ # 创建一个文件名为“$ $”的文件($间含有空格)13touch ./-hello # 创建一个文件名以-号开头的文件14touch -- -hello # 创建一个文件名以-号开头的文件15ls \ # 续行16> -l17
18# 字符串拼接19str03="1"'2'"3"20str03=${str01}${str02}21str03="${str01} ${str02}"22str03=`date`"." # date命令需要使用``来引用23
24# 获取字符串长度25echo ${#str02}26
27# 字符串截取28var=aabbccddaabbccdd.jpg29echo ${var#*bb} # 截取第一个bb后的字符串30echo ${var##*bb} # 截取最后一个bb后的字符串31echo ${var:0:3} # 截取第0-3位32
33# 查找子串34str="runoob is a great site"35echo `expr index "$str" is` # 输出 8
5) 数组
241# 定义数组2arr=(1 2 3 4 5 6)3arr2=("abc" "def")4
5# 数组元素赋值6arr[0]=6667arr=(1=999 2=9999)8
9# 读取数组元素10echo ${arr[0]}11
12# 读取数组全部元素13echo ${arr[*]}14echo ${arr[@]}15
16# 数组长度17echo ${#arr[*]}18
19# 合并数组20echo "${arr[*]} ${arr2[*]}"21
22# 删除数组元素23unset arr[2]24
3. 运算符
1) 算数运算符 + - \* / % == !=
原生的bash并不支持简单的数学运算,通常要通过其它命令来实现。
| 运算 | 格式 |
|---|---|
| 加法 | expr $a + $b |
| 减法 | expr $a - $b |
| 乘法 | expr $a \* $b |
| 除法 | expr $b / $a |
| 取余 | expr $b % $a |
| 赋值 | a=$b |
| 相等 | [ $a == $b ] |
| 不相等 | [ $a != $b ] |
271a=102b=203
4val=`expr $a + $b`5echo "a + b : $val"6
7val=`expr $a - $b`8echo "a - b : $val"9
10val=`expr $a \* $b`11echo "a * b : $val"12
13val=`expr $b / $a`14echo "b / a : $val"15
16val=`expr $b % $a`17echo "b % a : $val"18
19if [ $a == $b ]20then21 echo "a 等于 b"22fi23if [ $a != $b ]24then25 echo "a 不等于 b"26fi27
下面是其它一些可用的运算指令:
121# $[]2echo $[$a+$b]3
4# $(())5$((var=$a+$b))6
7# let8let var=$a+$b9
10# bc(小数运算)11var=$(echo "(1.1+2.1)"|bc)12
注意:
左括号
[也是一个命令,位于/usr/bin/[,在书写命令参数时注意使用空格分开。
2) 关系运算符 -eq -gt -lt
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
| 运算 | 格式 |
|---|---|
| 检测两个数是否相等 | [ $a -eq $b ] |
| 检测两个数是否不相等 | [ $a -ne $b ] |
| 检测左边的数是否大于右边的 | [ $a -gt $b ] |
| 检测左边的数是否小于右边的 | [ $a -lt $b ] |
| 检测左边的数是否大于等于右边的 | [ $a -ge $b ] |
| 检测左边的数是否小于等于右边的 | [ $a -le $b ] |
391a=102b=203
4if [ $a -eq $b ]5then6 echo "$a -eq $b : a 等于 b"7else8 echo "$a -eq $b: a 不等于 b"9fi10if [ $a -ne $b ]11then12 echo "$a -ne $b: a 不等于 b"13else14 echo "$a -ne $b : a 等于 b"15fi16if [ $a -gt $b ]17then18 echo "$a -gt $b: a 大于 b"19else20 echo "$a -gt $b: a 不大于 b"21fi22if [ $a -lt $b ]23then24 echo "$a -lt $b: a 小于 b"25else26 echo "$a -lt $b: a 不小于 b"27fi28if [ $a -ge $b ]29then30 echo "$a -ge $b: a 大于或等于 b"31else32 echo "$a -ge $b: a 小于 b"33fi34if [ $a -le $b ]35then36 echo "$a -le $b: a 小于或等于 b"37else38 echo "$a -le $b: a 大于 b"39fi
3) 布尔运算符 ! -o -a
| 运算 | 格式 |
|---|---|
| 非运算 | [ ! false ] |
| 或运算 | [ $a -lt 20 -o $b -gt 100 ] |
| 与运算 | [ $a -lt 20 -a $b -gt 100 ] |
271a=102b=203
4if [ $a != $b ]5then6 echo "$a != $b : a 不等于 b"7else8 echo "$a == $b: a 等于 b"9fi10if [ $a -lt 100 -a $b -gt 15 ]11then12 echo "$a 小于 100 且 $b 大于 15 : 返回 true"13else14 echo "$a 小于 100 且 $b 大于 15 : 返回 false"15fi16if [ $a -lt 100 -o $b -gt 100 ]17then18 echo "$a 小于 100 或 $b 大于 100 : 返回 true"19else20 echo "$a 小于 100 或 $b 大于 100 : 返回 false"21fi22if [ $a -lt 5 -o $b -gt 100 ]23then24 echo "$a 小于 5 或 $b 大于 100 : 返回 true"25else26 echo "$a 小于 5 或 $b 大于 100 : 返回 false"27fi
4) 逻辑运算符 && ||
| 运算 | 格式 |
|---|---|
| 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]] |
| 逻辑的 OR | [[ $a -lt 100 || $b -gt 100 ]] |
161a=102b=203
4if [[ $a -lt 100 && $b -gt 100 ]]5then6 echo "返回 true"7else8 echo "返回 false"9fi10
11if [[ $a -lt 100 || $b -gt 100 ]]12then13 echo "返回 true"14else15 echo "返回 false"16fi注意:逻辑运算具有特殊的短路功能!
5) 字符串运算符 = != -z -n
| 运算 | 格式 |
|---|---|
| 检测两个字符串是否相等 | [ $a = $b ] |
| 检测两个字符串是否不相等 | [ $a != $b ] |
| 检测字符串长度是否为0 | [ -z $a ] |
| 检测字符串长度是否不为 0 | [ -n $a" ] |
| 检测字符串是否为空 | [ $a ] |
451a="abc"2b="efg"3
4if [ $a = $b ]5then6 echo "$a = $b : a 等于 b"7else8 echo "$a = $b: a 不等于 b"9fi10
11if [ $a != $b ]12then13 echo "$a != $b : a 不等于 b"14else15 echo "$a != $b: a 等于 b"16fi17
18if [ -z $a ]19then20 echo "-z $a : 字符串长度为 0"21else22 echo "-z $a : 字符串长度不为 0"23fi24
25if [ -n "$a" ]26then27 echo "-n $a : 字符串长度不为 0"28else29 echo "-n $a : 字符串长度为 0"30fi31
32if [ $a ]33then34 echo "$a : 字符串不为空"35else36 echo "$a : 字符串为空"37fi38
39a=""40if [ -n "$a" ]41then42 echo "-n $a : 字符串长度不为 0"43else44 echo "-n $a : 字符串长度为 0"45fi
6) 文件测试运算符 -b -s -e
| 运算 | shell中的实现 |
|---|---|
| 检测文件是否是块设备文件 | [ -b $file ] |
| 检测文件是否是字符设备文件 | [ -c $file ] |
| 检测文件是否是目录 | [ -d $file ] |
| 检测文件是否是普通文件(既不是目录,也不是设备文件) | [ -f $file ] |
| 检测文件是否设置了 SGID 位 | [ -g $file ] |
| 检测文件是否设置了粘着位(Sticky Bit) | [ -k $file ] |
| 检测文件是否是有名管道 | [ -p $file ] |
| 检测文件是否设置了 SUID 位 | [ -u $file ] |
| 检测文件是否可读 | [ -r $file ] |
| 检测文件是否可写 | [ -w $file ] |
| 检测文件是否可执行 | [ -x $file ] |
| 检测文件是否为空(文件大小是否大于0) | [ -s $file ] |
| 检测文件(包括目录)是否存在 | [ -e $file ] |
441file="/var/www/runoob/test.sh"2if [ -r $file ]3then4 echo "文件可读"5else6 echo "文件不可读"7fi8if [ -w $file ]9then10 echo "文件可写"11else12 echo "文件不可写"13fi14if [ -x $file ]15then16 echo "文件可执行"17else18 echo "文件不可执行"19fi20if [ -f $file ]21then22 echo "文件为普通文件"23else24 echo "文件为特殊文件"25fi26if [ -d $file ]27then28 echo "文件是个目录"29else30 echo "文件不是个目录"31fi32if [ -s $file ]33then34 echo "文件不为空"35else36 echo "文件为空"37fi38if [ -e $file ]39then40 echo "文件存在"41else42 echo "文件不存在"43fi44
扩展:文件名通配符
*:匹配 0 个或多个任意字符,如:ls /dev/ttyS*。
?:匹配一个任意字符,如:ls ch0?.doc。
[若干字符]:匹配方括号中任意一个字符的一次出现,如:ch[012] [0-9].doc。
7) 命令执行符
61# `命令`2echo `date`3
4# $(命令)5echo $(date)6
4. 控制语句
1) if-fi
101
3a="check"4
5if [ $a == "check" ]6then7 echo "check..."8fi9
10
2) if-else-fi
121
3a=104
5if [ $a -eq 10 ]6then7 echo "相等"8else9 echo "不相等"10fi11
12
3) if else-if else
151
3file="./t1.sh"4
5if [ -b $file ]6then7 echo "块设备"8elif [-c $file ]9then10 echo "字符设备"11else12 echo "其它文件"13fi14
15
4) for循环
331
3# 遍历多个值4for item in 1 2 3 4 55do6 echo "This value is $item"7done8
9# 显示主目录下以 .bash 开头的文件10for FILE in $HOME/.bash*11do12 echo $FILE13done14
15# 从文件中读取每行信息,并输出s16for Name in $(cat ./namefile)17do18 echo $Name19done20
21# 遍历数组22arr=("a" "b" "c" "d")23for item in ${arr[*]}24do25 echo $item26done27
28# 遍历数组29for((i=0; i<${#arr[*]}; i++))30do31 echo "arr[$i] = ${arr[$i]}"32done33
5) while循环
81var=03while(($var<5))4do5 echo $var6 let var=var+17done8
6) 死循环
121for (( ; ; ))2
3while :4do5 command6done7
8while true9do10 command11done12
7) until循环
until 循环执行一系列命令直至条件为 true 时停止。
61until condition2do3 command4done5
6
8) 退出循环
301
3var=04
5while(($var < 5))6do7 if [ $var == 3 ]8 then9 break10 fi11
12 echo $var13 let var=$var+114done15
16
17
18var=019
20while(($var < 5))21do22 let var=$var+123 if [ $var == 3 ]24 then25 continue26 fi27
28 echo $var29done30
9) case-esac多选择语句
321var=$12var=${1:-stop}3echo "\$1 is $var"4
5case $var in6start)7 echo "start..."8 ;;9stop)10 echo "stop..."11 ;;12*)13 echo "不支持的命令"14 ;;15esac16
17var2=${2:-10}18echo "\$2 is $var2"19
20case $var2 in2110)22 echo "this is first item."23 ;;2420)25 echo "this is second item."26 ;;27*)28 echo "other."29 ;;30esac31
32
10) select-in语句
131
3echo "Please select..."4
5select var in "Linux" "Windwos" "Other"6do7 break;8done9
10echo "you have selected $var"11
12
13
5. 函数
1) 定义和调用函数
181
3# 函数定义时无需声明参数、无需声明返回值,function关键字也可以省略4function func01(){5 # 定义局部变量6 local var=107 8 # 函数参数9 echo "参数1:$1"10 echo "参数2:$2"11 12 # 也可以使用echo进行返回13 echo "ret is $var"14}15
16result=$(func01 1 2)17echo $result18
注意:
当函数没有return时,默认返回最后一个命令的运行结果作为返回值。
$10不能返回第十个参数,当n>10的时候,需要使用$(n)来获取参数。函数内部的定义的变量在外部也可以访问,可以使用
local关键字限制。
6. 重定向
1) 重定向简介
一般情况下,每个Linux命令运行时都会打开三个文件:
标准输入文件(stdin):文件描述符为0,程序默认从stdin读取数据。
标准输出文件(stdout):文件描述符为1,程序默认向stdout输出数据。
标准错误文件(stderr):文件描述符为2,程序会向stderr流中写入错误信息。
但有些时候我们可能需要将数据从其它文件读入或读出,这就需要我们重定向。
2) 标准流重定向
151# 输入流重定向到文件2command < file3
4# 输出流重定向到文件5command > file6
7# 错误流重定向到文件8command 2>file9
10# 输出和错误流重定向到文件11command > file 2>&112
13# 重定向到null文件(即输出被丢弃)14command > /dev/null15
7. 常用命令
1) echo
91# 显式字符串2echo "It is a test"3
4# 换行5echo -e "OK! \n" # -e 开启转义6
7# 不换行8echo -e "OK! \c" # -e 开启转义 \c 不换行9
2) read
read 命令用于获取键盘输入信息。
31read -p "input a val:" a #获取键盘输入的 a 变量数字2read -p "input b val:" b #获取键盘输入的 b 变量数字3r=$[a+b] #计算a+b的结果 赋值给r 不能有空格
3) 管道
可以通过 | 把一个命令的输出传递给另一个命令做输入。
31cat myfile | more2ls -l | grep "myfile"3df -k | awk '{print $1}' | grep -v "文件系统"
第三节 Windos脚本
1. 什么是批处理?
批处理是使用批处理文件(Batch File,简称BAT文件)进行批量的命令处理的过程。批处理文件从内容上来看包含了大量的基本DOS命令,是一种可执行文件。批处理文件运行时会按照规则从逐一执行文件中的命令,本质上是一些命令的集合。
2. 基础DOS命令介绍
1) 文件与目录相关命令 dir...
| 命令 | 说明 |
|---|---|
| dir | 展示路径下的目录和文件信息 |
| cd | 切换路径。可以用cd ..来切换到上层路径。 |
| 盘符: | 切换盘符。如d:。 |
| md | 创建文件夹 |
| rd | 删除文件夹 |
| copy | 复制文件到指定路径 |
| move | 移动文件到指定路径 |
| ren | 文件重命名 |
| del | 删除文件 |
| type | 查看文件 |
| edit | 编译文件 |
2) 显示相关命令 echo...
| 命令 | 说明 |
|---|---|
| title | 修改cmd窗口标题 |
| prompt | 修改命令提示符 |
| echo | 回显。可以使用echo on/off来打开/关闭命令回显。也可以使用@echo作用于单条命令。 |
3) 赋值命令 set
| 命令 | 说明 |
|---|---|
| set [变量名] | 查看变量的值。可以省略变量名来查看所有变量。 |
| set [变量名]=[变量值] | 定义一个字符串类型的变量,并给它赋值。如set var1=abc。注意,=两边最好不要有空格。 |
| set /a [变量名]=[变量值] | 定义一个数值型变量,并给它赋值。 |
| set /p [变量名]=[提示信息] | 从标准输入设备获取值,并给予用户提示信息。 |
4) 取值命令 %%
| 命令 | 说明 |
|---|---|
| %变量名% | 获取操作系统变量值 |
| %变量名:源串=目的串% | 读取变量的值做替换后返回,且原变量的值不变。 |
| %变量名:~m,n% | 读取变量的值截取某一片段返回,且原变量的值不变。 |
有var=1234567890,有如下:
91%var% 1234567890 显示所有 2%var:23=bc% 1bc4567890 替换23为bc3%var:~4% 567890 从第4个字符以后开始显示 4%var:~4,3% 567 从第4个字符以后开始显示,并只显示前3个 5%var:~-4% 7890 从倒数第4个字符开始显示 6%var:~-4,3% 789 从倒数第4个字符开始显示,并只显示前3个 7%var:~4,-2% 5678 从第4个字符以后开始显示,显示到还剩2个为止8%var:~0,3% 123 从头开始显示,并只显示前3个字符 9%var:~0,-3% 1234567 从头开始显示,显示到还剩3个字符为止
5) 组合命令 & && ||
| 命令 | 说明 |
|---|---|
| 命令1 & 命令2 | 命令1执行完后按顺序执行命令2。 |
| 命令1 && 命令2 | 命令1执行完后,如果结果正确,才执行命令2。 |
| 命令1 |
案例:
31dir "D:\test" & echo Seems it does not exist。2dir "D:\test" && echo Seems it does not exist。3dir "D:\test" || echo Seems it does not exist.
6) 重定向命令 > >> |
| 命令 | 说明 |
|---|
>|将命令的输出进行重定向,并覆盖原有内容
>>|将命令的输出进行重定向,但不覆盖原有内容
| |将命令1的输出作为命令2的输入
管道命令还有 < 、<& 和 >& ,它们并不常见,在此暂时不讨论了。
7) 调用命令
| 命令 | 说明 |
|---|---|
| call [标签] | 用于调用另一个批处理文件,调用完成后继续返回执行。 |
| start [标签] | 也用于调用另一个批处理文件,特点是会为其新开一个线程,从而不影响原线程执行。 |
标签的定义以
:开头。批处理文件也有一些固定的标签。如:EOF
8) 其它命令
| 命令 | 说明 |
|---|---|
| help [命令] | 查看命令的帮助信息。命令 /? 也可以达到相同效果 |
| rem | 注释该行命令 |
| cls | 清空屏幕显示 |
| color | 改变命令窗口颜色 |
3. 参数传递
1) 输入参数
在命令行执行批处理文件时,可以传递一些参数。如:
11test01.bat arg1 arg2 那么在批处理中可以通过%参数位置的方式来获取传入的参数。如:%1、%2等,值得注意的是,批处理文件最多只能传递9个参数。
test01的文件可以是如下所示:
51set arg1=%12set arg2=%23
4echo %arg1%5echo %arg2%通常的,批处理文件在头部定义一些变量,来接受外部传入的参数
2) 输出参数
输出参数一般不常用,但还是可以了解下它们。请看如下bat文件(num_add.bat):
41set /a arg1=%12set /a arg2=%23
4set /a %3=arg1+arg2可以进行一个简单的加法操作,下面是一组用于测试的命令:
31set /a num_val=02num_add.bat 1 2 num_val3echo %num_val%
3) 在call/start时使用参数
有下面一个批处理文件:
131@echo 开始测试...2call :lable1 abc3
4:lable25echo 然后显示这句6pause7
8goto :EOF9
10:lable111echo 首先显示这句,后面跟的参数为 %112pause13
goto命令是不可以携带参数的
4. 条件语句 if-else
1) 基础if-else用法
if-else的基本语法格式如下:
91if 条件表达式2(3 语句;4) 5else6(7 语句;8) 9
再附加上一个案例,相信你一看就能明白:
71if "%TIME:~0,2%" lss "12" 2(3 echo 现在是上午4) else 5(6 echo 现在是下午7)变量 TIME 是动态环境变量之一,表示当前时间。 lss 是if命令扩展用法,表示小于的意思。更多信息可以在
if/?中获得。
这里有一个小提示,为了防止出现某些意料之外的错误,请勿在if语句进行比较处加一些不必要的空格。
2) 延迟变量扩充
这是一个很有意思的特性。下面的例子可以很好的说明直接变量扩充与延迟变量扩充的区别。
151@echo off2setlocal EnableDelayedExpansion3
4set /a num=55
6if %num% == 5 (7 set /a num*=38
9 echo 在 if 语句之前,变量 num 等于 %num%10 echo 但变量 num 在经过运算后,且由于延迟变量扩充被启用,变量 num 等于 !num!11)12
13echo 但最终变量 num 还是等于 %num%14
15pausesetlocal EnableDelayedExpansion 表示开启延迟变量扩充,此时的 !num! 才有意义。
3) if exist和if defined
if 还有其他的用法。其中if exist用于判断文件是否存在,就像下面这样:
51if exist "D:\test my folder\a.txt" (2del "D:\test my folder\a.txt"3) else (4echo 您所要删除的文件不存在5)在对文件进行操作之前进行判断其是否存在很有意义,这使得代码更加健壮。
而if defined也与之类似,只不过判断对象不是文件,而是变量,它用于判断环境变量是否被定义。
5. 循环语句 for-in
for-in大致有三种常用的用法,分别是作用于文件、数字、以及字符串。
1) for-in 之于文件
下面是一个批量修改文件名的批处理文件。
121@echo off2setlocal EnableDelayedExpansion3
4set /p zpath=请输入目标文件所在的路径:5set /p prefix=请输入文件名前缀(不能包含以下字符\/:*?"<>|):6set /p ext=请输入文件的扩展名(例如 .txt):7set /a num=18
9for %%i in (%zpath%\*%ext%) do (10 ren "%%i" "%prefix%!num!.%ext%"11 set /a num+=112)%%i表示迭代变量。值得注意的是,在批处理文件中(而不是命令行),必须使用双%来标识。
2) for-in 之于数字
如果想对一系列有规律的数字进行循环,或是在一定的次数内对某个操作进行循环重复的执行,使用 for 也能够实现。下面是一个很好的例子:
141@echo off2setlocal EnableDelayedExpansion3
4set var=¥5for /l %%i in (1,1,7) do set var=%var%!var!6rem 此时变量 var 已经变成一行连续的8个¥了7
8for /l %%i in (1,1,8) do (9 echo 这是第 %%i 份>输出结果%%i.txt10 for /l %%j in (1,1,8) do echo %var%>>输出结果%%i.txt11)12
13echo 8 X 8 的 ¥ 矩阵已经画好,并保存到8份文本文件里了14pause/l 是可以跟在 for 后面的重要参数之一。用于标识作用于数字的for-in循环。in中的三个值分为为起始值、步长和结束值。
3) for-in 之于字符串
for 也可以对指定范围内的文字进行循。for 后面跟参数 /f ,/f 后面跟选项,所指定的范围 in 里可以是一个文件里的文字,可以是一个字符串,也可以是一条命令的输出结果。我们首先以一个文件里的文字作为循环对象,循环时,每一行将被循环一次。
291@echo off2echo 测试 文字筛选.txt 里每一行的首单词3for /f %%i in (文字筛选.txt) do echo %%i4pause5
6echo.7echo skip=2 表示前两行被跳过8for /f "skip=2" %%i in (文字筛选.txt) do echo %%i9pause10
11echo.12echo tokens=2,4-6 表示提取每行的第2个、以及第4到6个单词13for /f "skip=2 tokens=2,4-6" %%i in (文字筛选.txt) do echo %%i, %%j, %%k, %%l.14pause15
16echo.17echo eol=N 表示当此行的首字母为 N 时,就忽略该行18for /f "eol=N skip=2 tokens=2,4-6" %%i in (文字筛选.txt) do echo %%i, %%j, %%k, %%l.19pause20
21echo.22echo delims=e 表示不再以空格区分每个词,而是以字母 e 作为间隔23for /f "eol=N skip=2 tokens=2,4-6 delims=e" %%i in (文字筛选.txt) do echo %%i, %%j, %%k, %%l.24pause25
26echo.27echo usebackq 表示双引号里的东西是文件名而不是字符串28for /f "usebackq eol=N skip=2 tokens=2,4-6 delims=e" %%i in ("文字筛选.txt") do echo %%i, %%j, %%k, %%l.29pause作为测试,可以在上述批处理文件的同一路径下创建一个用于测试的文本文件 文字筛选.txt ,其内容为:
51Hello there!2This text is an example of test for the batch file 文字筛选.bat.3Notice the first letter in this line, N.4If the eol charactor was set to be letter N.5The third line will not be considered by the batch.
6. 跳转语句 goto call
goto和call可以无条件的改变命令的执行顺序。下面是一个使用goto的案例
121@echo off2goto :FirstLable3
4:SecondLable5echo 然后显示这句6pause7goto :EOF8
9:FirstLable10echo 首先显示这句11pause12goto :SecondLablecall与goto的使用方式类似,但call执行完后依然会回到call之前的位置继续执行剩下的代码,案例可以参考上章节。
第02章_虚拟化
第一节 Docker简介
1. 什么是Docker?
Docker是一种轻量级的虚拟化技术,它允许开发人员将应用程序及其依赖项打包到一个可移植的容器中,便于部署和运行。
2. 安装Docker
291# 移除旧版本2yum remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-engine3
4# 配置 docker yum 源5yum install -y yum-utils6yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo7
8# 安装docker9yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin10
11# 启动&开机启动12systemctl enable docker --now13
14# 配置加速15mkdir -p /etc/docker16vim /etc/docker/daemon.json17{18 "registry-mirrors": ["https://mirror.ccs.tencentyun.com"]19}20systemctl daemon-reload21systemctl restart docker22
23# 启动一个MySql24docker run -d -p 3306:3306 \25 -v /app/myconf:/etc/mysql/conf.d \26 -v /app/mydata:/var/lib/mysql \27 -e MYSQL_ROOT_PASSWORD=123456 \28 mysql:8.0.37-debian29
3. 常用Docker命令
1) 镜像相关命令
221# 搜索镜像2docker search nginx3
4# 下载镜像5docker pull nginx6
7# 下载指定版本镜像8docker pull nginx:1.26.09
10# 查看所有镜像11docker images12
13# 删除指定id的镜像14docker rmi e784f456044815docker rmi bde7d154a67f 94543a6c1aef e784f456044816
17# 查看镜像构建历史18docker image history nginx19
20# 查看镜像详情21docker image inspect nginx22
2) 容器相关命令
401# 查看所有容器2docker ps -a3
4# 查看运⾏中的容器5docker ps6
7# 运⾏⼀个新容器8docker run nginx9
10# 停⽌容器11docker stop keen_blackwell12
13# 启动容器14docker start 59215
16# 重启容器17docker restart 59218
19# 查看容器资源占⽤情况20docker stats 59221
22# 查看容器⽇志23docker logs 59224
25# 删除指定容器26docker rm 59227docker rm -f $(docker ps -aq)28
29# 强制删除指定容器30docker rm -f 59231
32# 后台启动容器33docker run -d --name mynginx nginx34
35# 后台启动并暴露端⼝36docker run -d --name mynginx -p 80:80 nginx37
38# 进⼊容器内部39docker exec -it mynginx /bin/bash40
3) 分享镜像
171# 文件发布2# 提交容器变化打成⼀个新的镜像3docker commit -m "update index.html" mynginx mynginx:v1.04# 保存镜像为指定⽂件5docker save -o mynginx.tar mynginx:v1.06# 加载镜像7docker load -i mynginx.tar 8
9# DcokerHub发布10# 登录11docker hub12docker login13# 重新给镜像打标签14docker tag mynginx:v1.0 leifengyang/mynginx:v1.015# 推送镜像16docker push leifengyang/mynginx:v1.017
4) 存储映射
111 # 映射数据目录和配置目录2 docker run -d -p 99:80 \3 -v /app/nghtml:/usr/share/nginx/html \ # 使用“⽬录挂载”映射数据目录(目录默认为空)4 -v ngconf:/etc/nginx \ # 使用“卷映射”映射配置目录(目录默认为容器内部目录文件)5 --name app03 nginx6
7# docker卷操作8docker volume ls9docker volume create volume0110docker volume inspect ngconf11
5) Docker网络
231# ⾃定义Dcoker⽹络2docker network create mynet3
4# 使用Dcoker⽹络建立Redis主从集群5# 主节点6docker run -d -p 6379:6379 \7 -v /app/rd1:/bitnami/redis/data \8 -e REDIS_REPLICATION_MODE=master \9 -e REDIS_PASSWORD=123456 \10 --network mynet --name redis01 \11 bitnami/redis12 13# 从节点14docker run -d -p 6380:6379 \15 -v /app/rd2:/bitnami/redis/data \16 -e REDIS_REPLICATION_MODE=slave \17 -e REDIS_MASTER_HOST=redis01 \18 -e REDIS_MASTER_PORT_NUMBER=6379 \19 -e REDIS_MASTER_PASSWORD=123456 \20 -e REDIS_PASSWORD=123456 \21 --network mynet --name redis02 \22 bitnami/redis23
4. Docker Compose
1) 简介
Docker Compose 是用于定义和运行多容器应用程序的工具。 它是解锁简化和高效的开发和部署体验的关键。
参考文档:
2) 常用命令
61# 上线2docker compose -f compose.yml up -d3
4# 下线5docker compose -f compose.yml down # 移除网络和容器,不移除卷6docker compose -f compose.yml down --rmi all -v # 移除网络和容器,并移除卷
3) 简单示例
641# compose.yml2
3# 名称4namemyblog5
6# 服务列表7services8
9# 数据库10 mysql11 # 名称12 container_namemysql13 # 镜像14 imagemysql8.015 # 端口映射16 ports17"3306:3306"18 # 配置信息19 environment20MYSQL_ROOT_PASSWORD=12345621MYSQL_DATABASE=wordpress22 # 卷映射(注意:使用的卷需在根节点声明)23 volumes24mysql-data:/var/lib/mysql25/app/myconf:/etc/mysql/conf.d26 # 开机自启27 restartalways28 # 加入的网络29 networks30blog31
32# 博客应用33 wordpress34 # 镜像35 imagewordpress36 # 端口映射37 ports38"8080:80"39 # 配置信息40 environment41 WORDPRESS_DB_HOSTmysql42 WORDPRESS_DB_USERroot43 WORDPRESS_DB_PASSWORD12345644 WORDPRESS_DB_NAMEwordpress45 # 卷映射(注意:使用的卷需在根节点声明)46 volumes47wordpress:/var/www/html48 # 开机自启49 restartalways50 # 加入的网络51 networks52blog53 # 依赖的服务54 depends_on55mysql56
57# 卷映射声明58volumes59 mysql-data60 wordpress61
62# Docker网络63networks64 blog
4) 安装常用开发组件
系统配置
161#Disable memory paging and swapping performance2sudo swapoff -a3
4# Edit the sysctl config file5sudo vi /etc/sysctl.conf6
7# Add a line to define the desired value8# or change the value if the key exists,9# and then save your changes.10vm.max_map_count=26214411
12# Reload the kernel parameters using sysctl13sudo sysctl -p14
15# Verify that the change was applied by checking the value16cat /proc/sys/vm/max_map_count
compose.yml
准备一个 compose.yml文件,内容如下:
2461namedevsoft2services3 redis4 imagebitnami/redislatest5 restartalways6 container_nameredis7 environment8REDIS_PASSWORD=1234569 ports10'6379:6379'11 volumes12redis-data:/bitnami/redis/data13redis-conf:/opt/bitnami/redis/mounted-etc14/etc/localtime:/etc/localtime:ro15
16 mysql17 imagemysql8.0.3118 restartalways19 container_namemysql20 environment21MYSQL_ROOT_PASSWORD=12345622 ports23'3306:3306'24'33060:33060'25 volumes26mysql-conf:/etc/mysql/conf.d27mysql-data:/var/lib/mysql28/etc/localtime:/etc/localtime:ro29
30 rabbit31 imagerabbitmq3-management32 restartalways33 container_namerabbitmq34 ports35"5672:5672"36"15672:15672"37 environment38RABBITMQ_DEFAULT_USER=rabbit39RABBITMQ_DEFAULT_PASS=rabbit40RABBITMQ_DEFAULT_VHOST=dev41 volumes42rabbit-data:/var/lib/rabbitmq43rabbit-app:/etc/rabbitmq44/etc/localtime:/etc/localtime:ro45 opensearch-node146 imageopensearchproject/opensearch2.13.047 container_nameopensearch-node148 environment49cluster.name=opensearch-cluster # Name the cluster50node.name=opensearch-node1 # Name the node that will run in this container51discovery.seed_hosts=opensearch-node1,opensearch-node2 # Nodes to look for when discovering the cluster52cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Nodes eligibile to serve as cluster manager53bootstrap.memory_lock=true # Disable JVM heap memory swapping54"OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Set min and max JVM heap sizes to at least 50% of system RAM55"DISABLE_INSTALL_DEMO_CONFIG=true" # Prevents execution of bundled demo script which installs demo certificates and security configurations to OpenSearch56"DISABLE_SECURITY_PLUGIN=true" # Disables Security plugin57 ulimits58 memlock59 soft-1 # Set memlock to unlimited (no soft or hard limit)60 hard-161 nofile62 soft65536 # Maximum number of open files for the opensearch user - set to at least 6553663 hard6553664 volumes65opensearch-data1:/usr/share/opensearch/data # Creates volume called opensearch-data1 and mounts it to the container66/etc/localtime:/etc/localtime:ro67 ports689200:9200 # REST API699600:9600 # Performance Analyzer70
71 opensearch-node272 imageopensearchproject/opensearch2.13.073 container_nameopensearch-node274 environment75cluster.name=opensearch-cluster # Name the cluster76node.name=opensearch-node2 # Name the node that will run in this container77discovery.seed_hosts=opensearch-node1,opensearch-node2 # Nodes to look for when discovering the cluster78cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Nodes eligibile to serve as cluster manager79bootstrap.memory_lock=true # Disable JVM heap memory swapping80"OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Set min and max JVM heap sizes to at least 50% of system RAM81"DISABLE_INSTALL_DEMO_CONFIG=true" # Prevents execution of bundled demo script which installs demo certificates and security configurations to OpenSearch82"DISABLE_SECURITY_PLUGIN=true" # Disables Security plugin83 ulimits84 memlock85 soft-1 # Set memlock to unlimited (no soft or hard limit)86 hard-187 nofile88 soft65536 # Maximum number of open files for the opensearch user - set to at least 6553689 hard6553690 volumes91/etc/localtime:/etc/localtime:ro92opensearch-data2:/usr/share/opensearch/data # Creates volume called opensearch-data2 and mounts it to the container93
94 opensearch-dashboards95 imageopensearchproject/opensearch-dashboards2.13.096 container_nameopensearch-dashboards97 ports985601:5601 # Map host port 5601 to container port 560199 expose100"5601" # Expose port 5601 for web access to OpenSearch Dashboards101 environment102'OPENSEARCH_HOSTS=["http://opensearch-node1:9200","http://opensearch-node2:9200"]'103"DISABLE_SECURITY_DASHBOARDS_PLUGIN=true" # disables security dashboards plugin in OpenSearch Dashboards104 volumes105/etc/localtime:/etc/localtime:ro106 zookeeper107 imagebitnami/zookeeper3.9108 container_namezookeeper109 restartalways110 ports111"2181:2181"112 volumes113"zookeeper_data:/bitnami"114/etc/localtime:/etc/localtime:ro115 environment116ALLOW_ANONYMOUS_LOGIN=yes117
118 kafka119 image'bitnami/kafka:3.4'120 container_namekafka121 restartalways122 hostnamekafka123 ports124'9092:9092'125'9094:9094'126 environment127KAFKA_CFG_NODE_ID=0128KAFKA_CFG_PROCESS_ROLES=controller,broker129KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://0.0.0.0:9094130KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://119.45.147.122:9094131KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT132KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093133KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER134ALLOW_PLAINTEXT_LISTENER=yes135"KAFKA_HEAP_OPTS=-Xmx512m -Xms512m"136 volumes137kafka-conf:/bitnami/kafka/config138kafka-data:/bitnami/kafka/data139/etc/localtime:/etc/localtime:ro140 kafka-ui141 container_namekafka-ui142 imageprovectuslabs/kafka-uilatest143 restartalways144 ports1458080:8080146 environment147 DYNAMIC_CONFIG_ENABLEDtrue148 KAFKA_CLUSTERS_0_NAMEkafka-dev149 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERSkafka9092150 volumes151kafkaui-app:/etc/kafkaui152/etc/localtime:/etc/localtime:ro153
154 nacos155 imagenacos/nacos-serverv2.3.1156 container_namenacos157 ports1588848:88481599848:9848160 environment161PREFER_HOST_MODE=hostname162MODE=standalone163JVM_XMX=512m164JVM_XMS=512m165SPRING_DATASOURCE_PLATFORM=mysql166MYSQL_SERVICE_HOST=nacos-mysql167MYSQL_SERVICE_DB_NAME=nacos_devtest168MYSQL_SERVICE_PORT=3306169MYSQL_SERVICE_USER=nacos170MYSQL_SERVICE_PASSWORD=nacos171MYSQL_SERVICE_DB_PARAM=characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true172NACOS_AUTH_IDENTITY_KEY=2222173NACOS_AUTH_IDENTITY_VALUE=2xxx174NACOS_AUTH_TOKEN=SecretKey012345678901234567890123456789012345678901234567890123456789175NACOS_AUTH_ENABLE=true176 volumes177/app/nacos/standalone-logs/:/home/nacos/logs178/etc/localtime:/etc/localtime:ro179 depends_on180 nacos-mysql181 conditionservice_healthy182 nacos-mysql183 container_namenacos-mysql184 build185 context.186 dockerfile_inline187 FROM mysql:8.0.31188 ADD https://raw.githubusercontent.com/alibaba/nacos/2.3.2/distribution/conf/mysql-schema.sql /docker-entrypoint-initdb.d/nacos-mysql.sql189 RUN chown -R mysql:mysql /docker-entrypoint-initdb.d/nacos-mysql.sql190 EXPOSE 3306191 CMD ["mysqld", "--character-set-server=utf8mb4", "--collation-server=utf8mb4_unicode_ci"]192 imagenacos/mysql8.0.30193 environment194MYSQL_ROOT_PASSWORD=root195MYSQL_DATABASE=nacos_devtest196MYSQL_USER=nacos197MYSQL_PASSWORD=nacos198LANG=C.UTF-8199 volumes200nacos-mysqldata:/var/lib/mysql201/etc/localtime:/etc/localtime:ro202 ports203"13306:3306"204 healthcheck205 test "CMD" "mysqladmin" "ping" "-h" "localhost" 206 interval5s207 timeout10s208 retries10209 prometheus210 imageprom/prometheusv2.52.0211 container_nameprometheus212 restartalways213 ports2149090:9090215 volumes216prometheus-data:/prometheus217prometheus-conf:/etc/prometheus218/etc/localtime:/etc/localtime:ro219
220 grafana221 imagegrafana/grafana10.4.2222 container_namegrafana223 restartalways224 ports2253000:3000226 volumes227grafana-data:/var/lib/grafana228/etc/localtime:/etc/localtime:ro229
230volumes231 redis-data232 redis-conf233 mysql-conf234 mysql-data235 rabbit-data236 rabbit-app237 opensearch-data1238 opensearch-data2239 nacos-mysqldata240 zookeeper_data241 kafka-conf242 kafka-data243 kafkaui-app244 prometheus-data245 prometheus-conf246 grafana-data注意:
将
kafka的119.45.147.122改为你自己的服务器IP。
启动
21# 在 compose.yaml 文件所在的目录下执行2docker compose -f compose.yml up -d
访问
| 组件(容器名) | 介绍 | 访问地址 | 账号/密码 | 特性 |
|---|---|---|---|---|
| Redis(redis) | k-v 库 | 你的ip:6379 | 单密码模式:123456 | 已开启AOF |
| MySQL(mysql) | 数据库 | 你的ip:3306 | root/123456 | 默认utf8mb4字符集 |
| Rabbit(rabbit) | 消息队列 | 你的ip:15672 | rabbit/rabbit | 暴露5672和15672端口 |
| OpenSearch(opensearch-node1/2) | 检索引擎 | 你的ip:9200 | 内存512mb;两个节点 | |
| opensearch-dashboards | search可视化 | 你的ip:5601 | ||
| Zookeeper(zookeeper) | 分布式协调 | 你的ip:2181 | 允许匿名登录 | |
| kafka(kafka) | 消息队列 | 你的ip:9092 外部访问:9094 | 占用内存512mb | |
| kafka-ui(kafka-ui) | kafka可视化 | 你的ip:8080 | ||
| nacos(nacos) | 注册/配置中心 | 你的ip:8848 | nacos/nacos | 持久化数据到MySQL |
| nacos-mysql(nacos-mysql) | nacos配套数据库 | 你的ip:13306 | root/root | |
| prometheus(prometheus) | 时序数据库 | 你的ip:9090 | ||
| grafana(grafana) | 你的ip:3000 | admin/admin |
5. Dockerfile
1) 简介
Dockerfile 是 Docker 镜像的构建描述文件,常用指令如下:
| 指令 | 描述 |
|---|---|
ADD | 添加本地或远程文件和目录。 |
ARG | 使用构建时变量。 |
CMD | 指定 default 命令。 |
COPY | 复制文件和目录。 |
ENTRYPOINT | 指定默认可执行文件。 |
ENV | 设置环境变量。 |
EXPOSE | 描述您的应用程序正在侦听的端口。 |
FROM | 从基础映像创建新的构建阶段。 |
HEALTHCHECK | 在启动时检查容器的运行状况。 |
LABEL | 将元数据添加到图像中。 |
MAINTAINER | 指定图像的作者。 |
ONBUILD | 指定何时在构建中使用映像的说明。 |
RUN | 执行生成命令。 |
SHELL | 设置镜像的默认 shell。 |
STOPSIGNAL | 指定退出容器的系统调用信号。 |
USER | 设置用户和组 ID。 |
VOLUME | 创建卷挂载。 |
WORKDIR | 更改工作目录。 |
参考文档:
Dockerfile reference | Docker Docs
2) 常用命令
31# 构建镜像(注意:最后有一个点,表示基于当前目录构建对象)2docker build -f Dockerfile -t myjavaapp:v1.0 .3
3) 简单示例
141# 基础环境2FROM openjdk:173
4# 标签5LABEL author=leifengyang6
7# 拷贝文件8COPY app.jar /app.jar9
10# 暴露端口11EXPOSE 808012
13# 启动命令14ENTRYPOINT ["java","-jar","/app.jar"]
第二节 K8S简介
1. 什么是K8S?
Kubernetes(通常简称为K8s)是一个开源的容器编排平台,用于自动化容器化应用程序的部署、扩展和管理。
第03章_Web服务器
第一节 Web服务器概述
1. 什么是Web服务器?
Web服务器是一种在互联网上提供网页内容的服务器程序,主要功能是接收客户端(如浏览器)的请求,然后将网页内容(如HTML、CSS、JavaScript等)发送给客户端进行展示。
2. 常用的Web服务器有哪些?
webLogic:Oracle公司,大型的JavaEE服务器,支持所有的JavaEE规范,收费的。
webSphere:IBM公司,大型的JavaEE服务器,支持所有的JavaEE规范,收费的。
JBOSS:JBOSS公司的,大型的JavaEE服务器,支持所有的JavaEE规范,收费的。
Tomcat:Apache基金组织,中小型的JavaEE服务器,仅仅支持少量的JavaEE规范servlet/jsp。开源的,免费的。
第二节 Tomcat安装部署
1. 下载安装
安装:解压压缩包即可。注意,安装目录建议不要有中文和空格。
2. 部署项目
1) JavaWeb项目结构
一个JavaWeb项目的目录结构类似如下:
301JavaWebProject/2│3├── src/ # 源代码目录4│ ├── main/ # 主要源代码5│ │ ├── java/ # Java源代码6│ │ │ └── com/example/ # 包名空间,存放Java类文件7│ │ │ ├── controller/ # 控制器类8│ │ │ ├── service/ # 服务层类9│ │ │ ├── model/ # 模型类(如实体类)10│ │ │ └── util/ # 工具类11│ │ └── resources/ # 配置文件12│ │ ├── application.properties # 应用配置文件13│ │ └── logback.xml # 日志配置文件14│ └── test/ # 测试代码15│ ├── java/ # 测试Java代码16│ └── resources/ # 测试配置文件17│18├── webapp/ # Web应用资源19│ ├── WEB-INF/ # Web应用的私有目录20│ │ ├── classes/ # 编译后的类文件21│ │ ├── lib/ # 项目依赖的JAR文件22│ │ └── web.xml # Web应用的部署描述符23│ ├── index.html # 首页HTML文件24│ ├── css/ # CSS样式文件25│ ├── js/ # JavaScript脚本文件26│ └── images/ # 图片资源27│28├── pom.xml # Maven项目的配置文件(如果是Maven项目)29│30└── README.md # 项目说明文档
2) 直接部署
直接将 webapp 目录放到 Tomcat 的
webapps目录下即可,第一层目录就是虚拟目录。也可以将项目打包成war包直接放在webapps目录下,tomcat会自动进行解压。
3) 静态部署
配置
conf/server.xml文件,在<Host>标签体中配置<Context docBase="D:\hello" path="/hehe" />。其中 docBase 是项目存放的实际路径,path 是项目的虚拟目录。
4) 动态部署
在
conf\Catalina\localhost目录下创建任意名称的xml文件。在文件中编写
<Context docBase="D:\hello" />,此时文件名就是项目的虚拟目录。
3. 启停项目
启动:双击bin目录下的
startup.bat文件即可。访问:浏览器输入协议名://ip:端口/虚拟目录/文件名,如http://localhost:8080/Demo/helloword.html。
关闭:可以使用bin目录下的
shutdown.bat脚本或ctrl+c正常关闭,也可以直接关闭窗口强制关闭。
注意:Tomcat启动可能遇到的问题
黑窗口一闪而过:可能是没有正确配置JAVA_HOME目录。
启动报错:可能是端口被占用。可以直接使用netstat -ano查找所在进程然后打开任务管理器杀死,也可以修改自身端口。
4. 与IDEA集成
配置步骤:参考:https://blog.csdn.net/HughGilbert/article/details/56424137等一些其它教程。
注意事项:
IDEA会为每一个 tomcat 部署的项目单独建立一份配置文件,这个配置文件可以通过控制台的log查看,如:Using CATALINA_BASE:"C:\Users\fqy.IntelliJIdea2018.1\system\tomcat_itcast"。
工作空间项目所在目录和 tomcat 部署项目所在的目录不是同一个目录,前者对应着后者的web目录下的所有资源。
web项目也可以开启断点调试:使用"小虫子"(dubug模式)启动即可,并且在设置了xx选项后每次修改都不需要重启服务器。
第04章_IDEA
第一节 IDEA简介
1. 什么是IDEA?
IntelliJ IDEA 是一款由 JetBrains 公司开发的集成开发环境(IDE),主要用于 Java、Kotlin、Groovy 等软件开发。
2. 安装IDEA
3. 基础配置
打开配置菜单
IDEA主题与字体
启动时打开上次项目/关闭时进行确认
开启滚轮调整字体大小
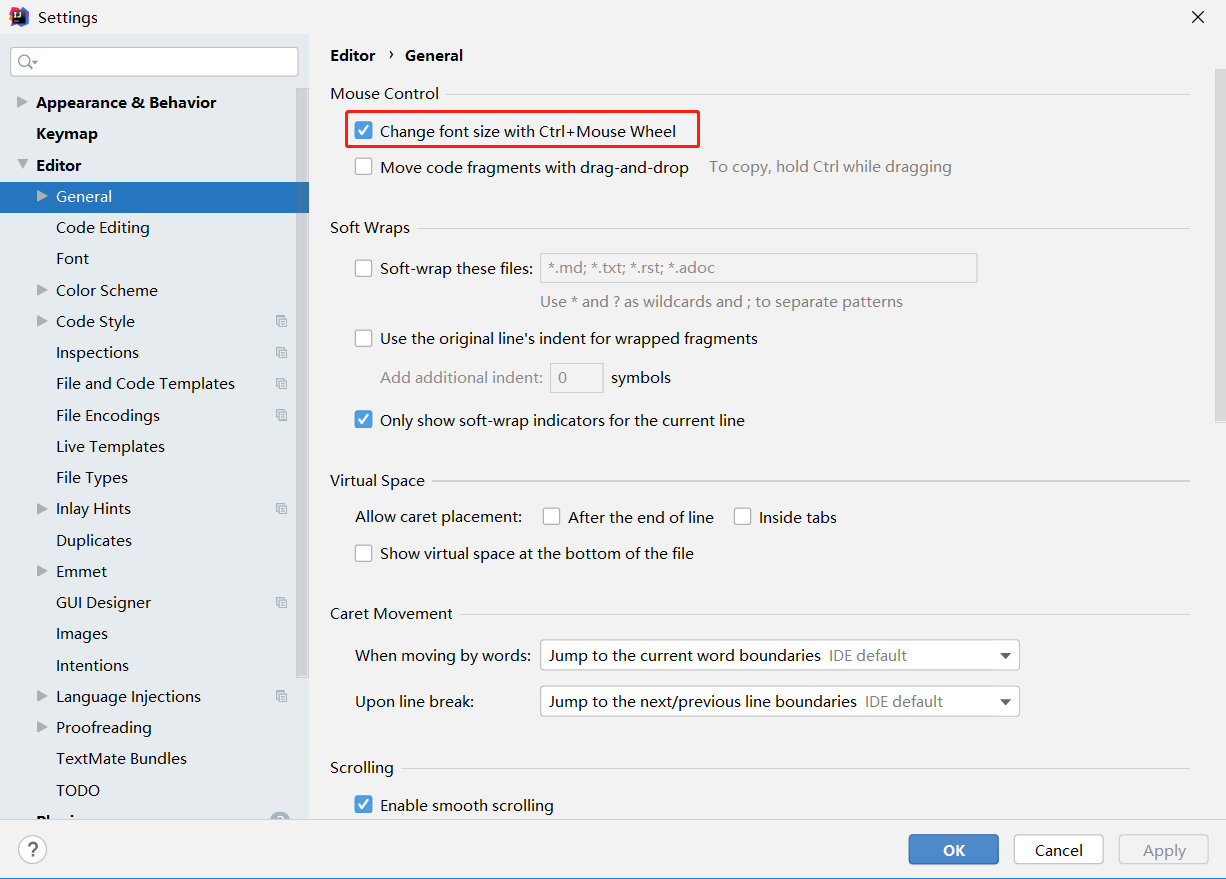
开启自动导入
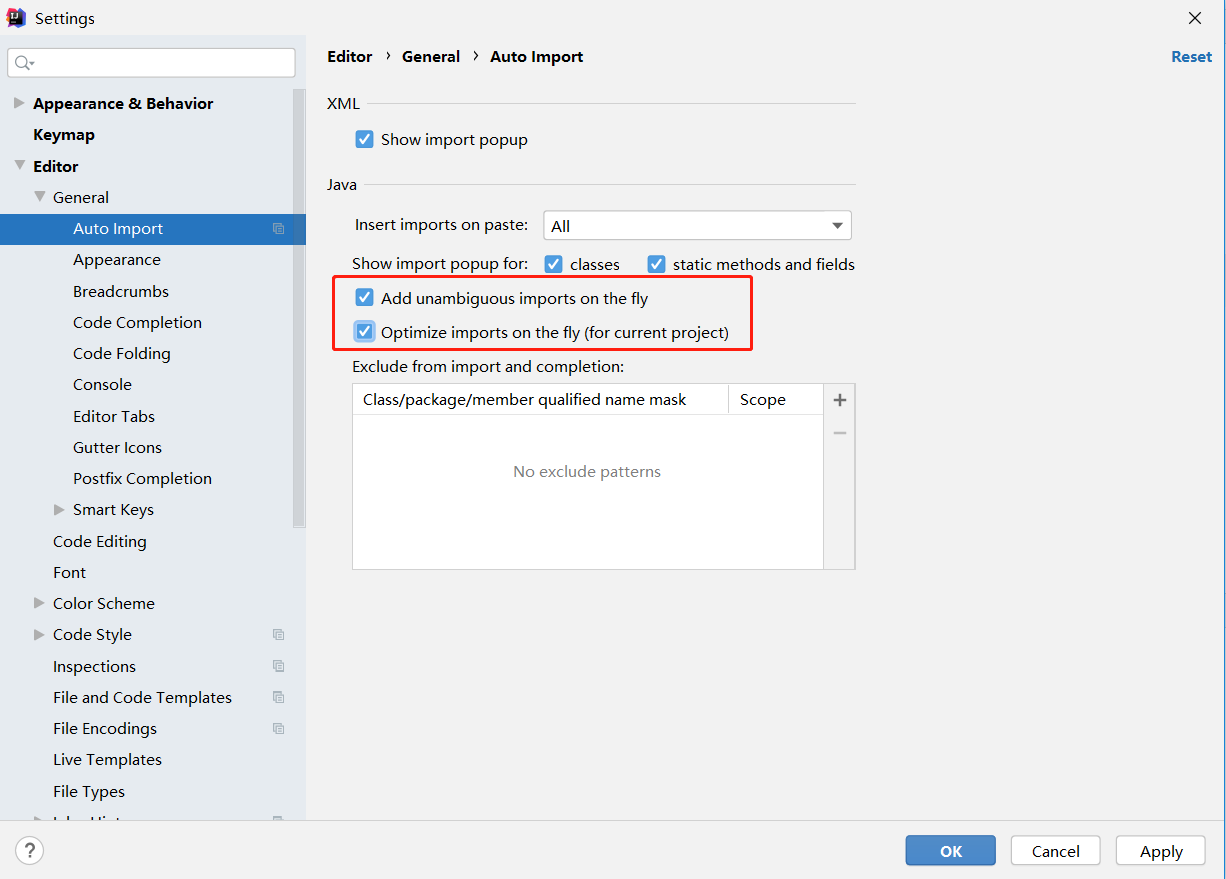
展示行号和方法分割线
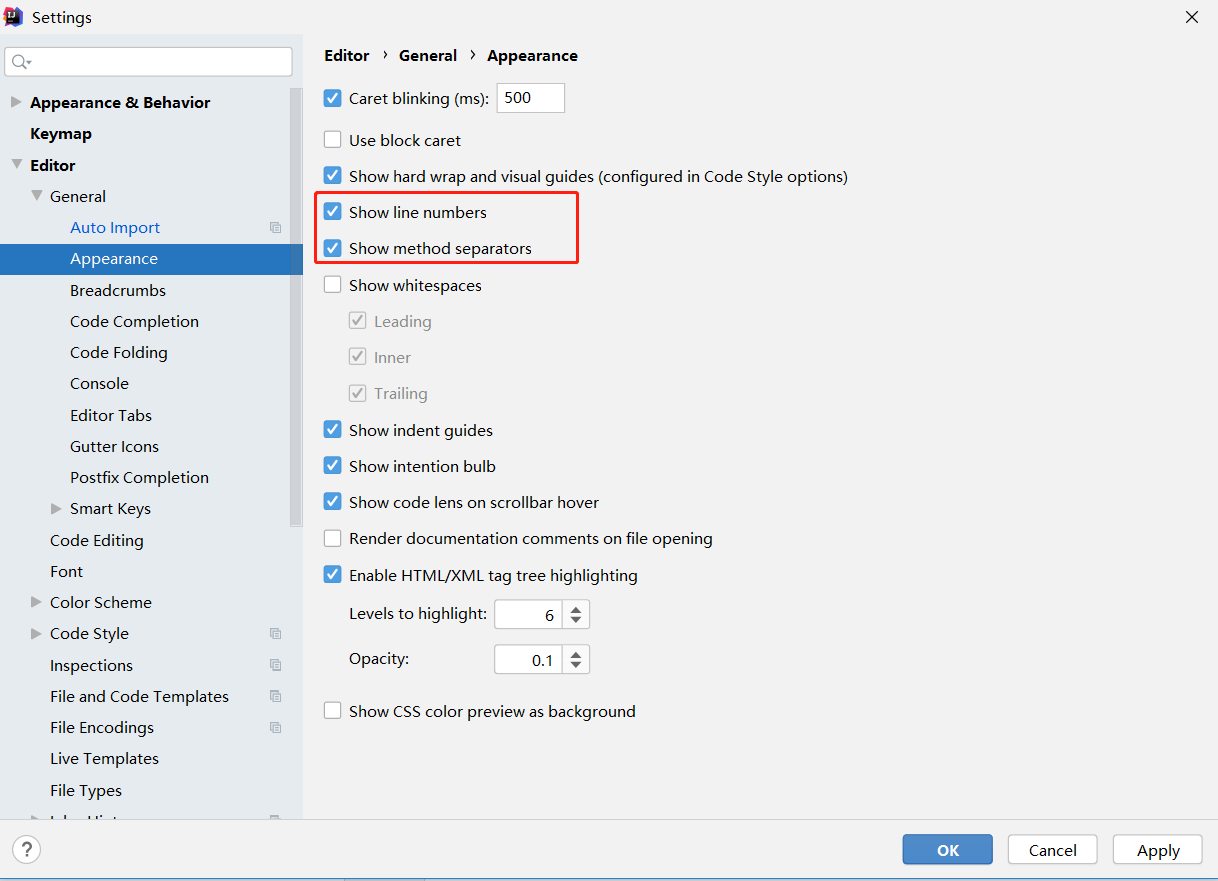
开启代码联想
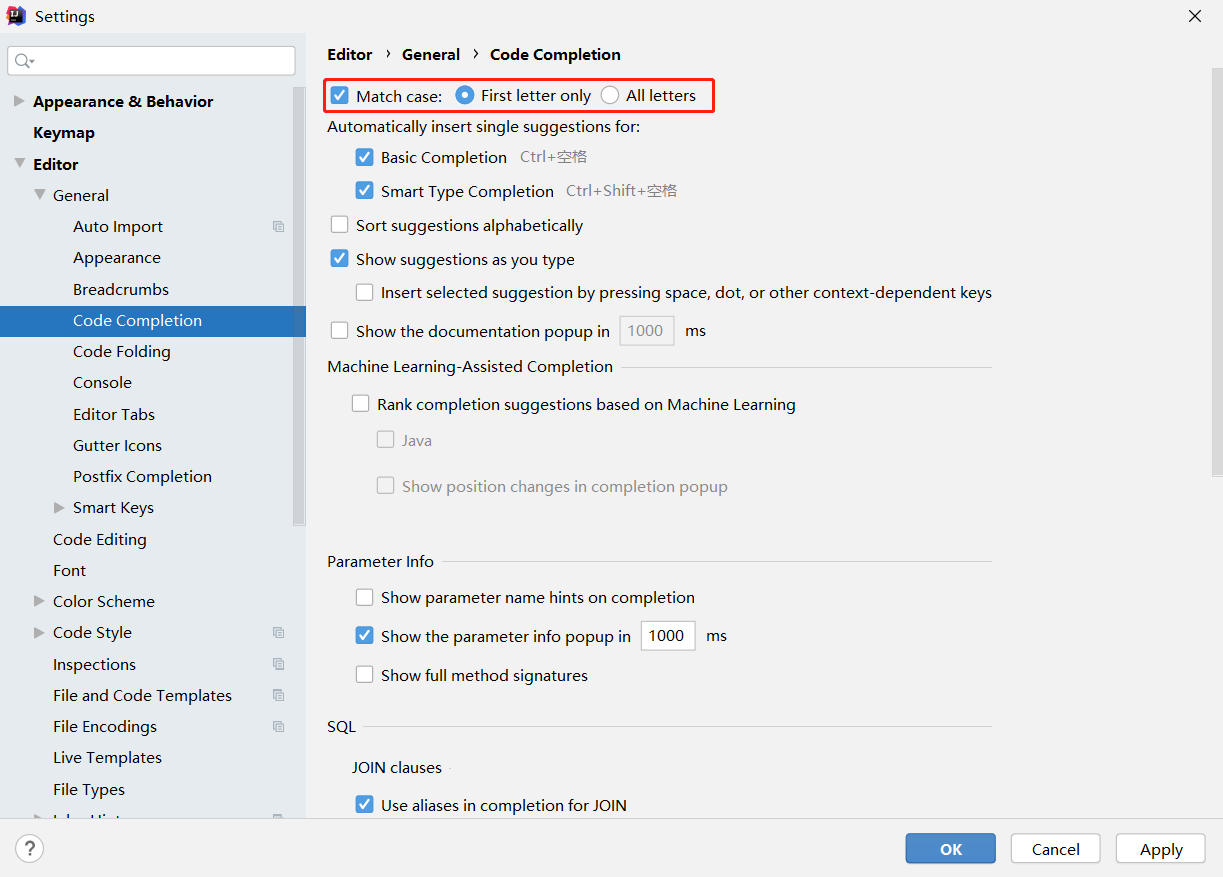
调整字体字号行间距
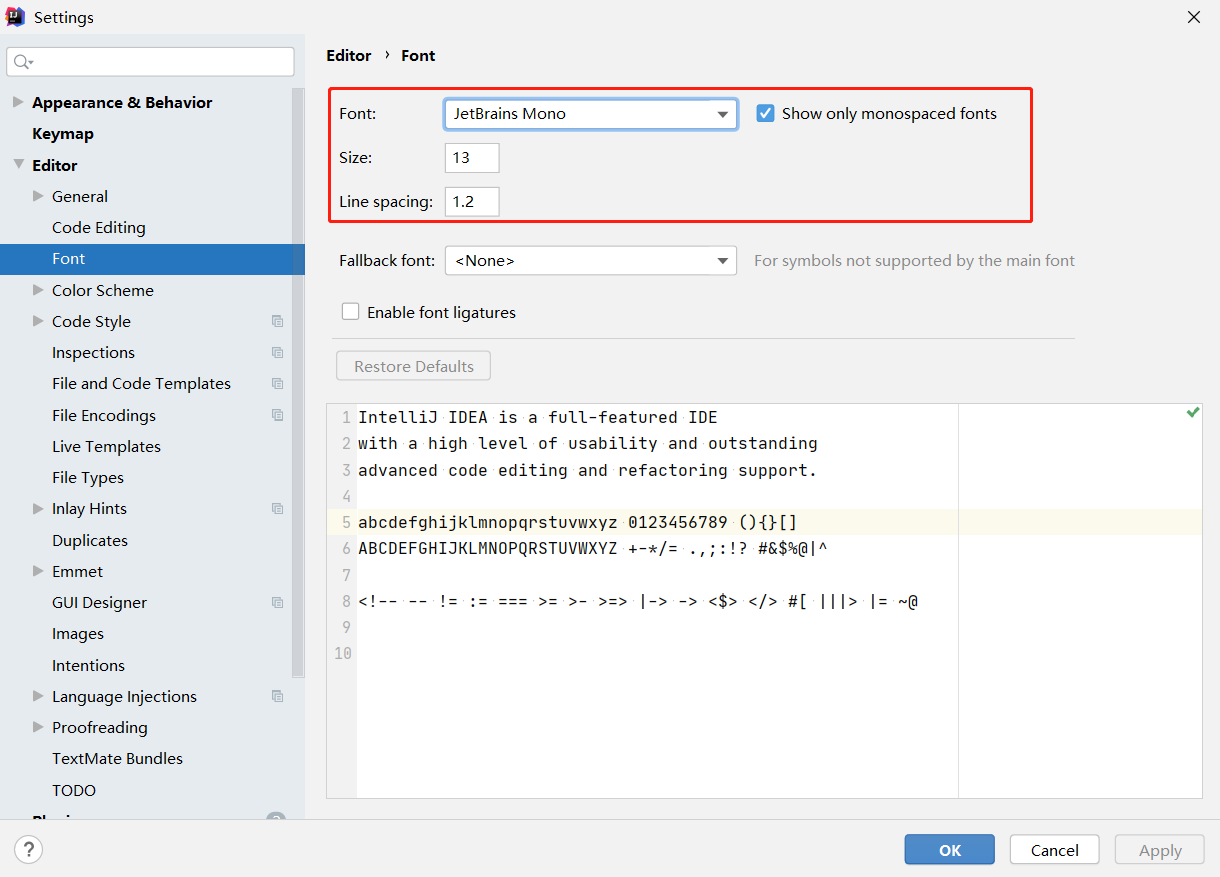
修改行结尾符
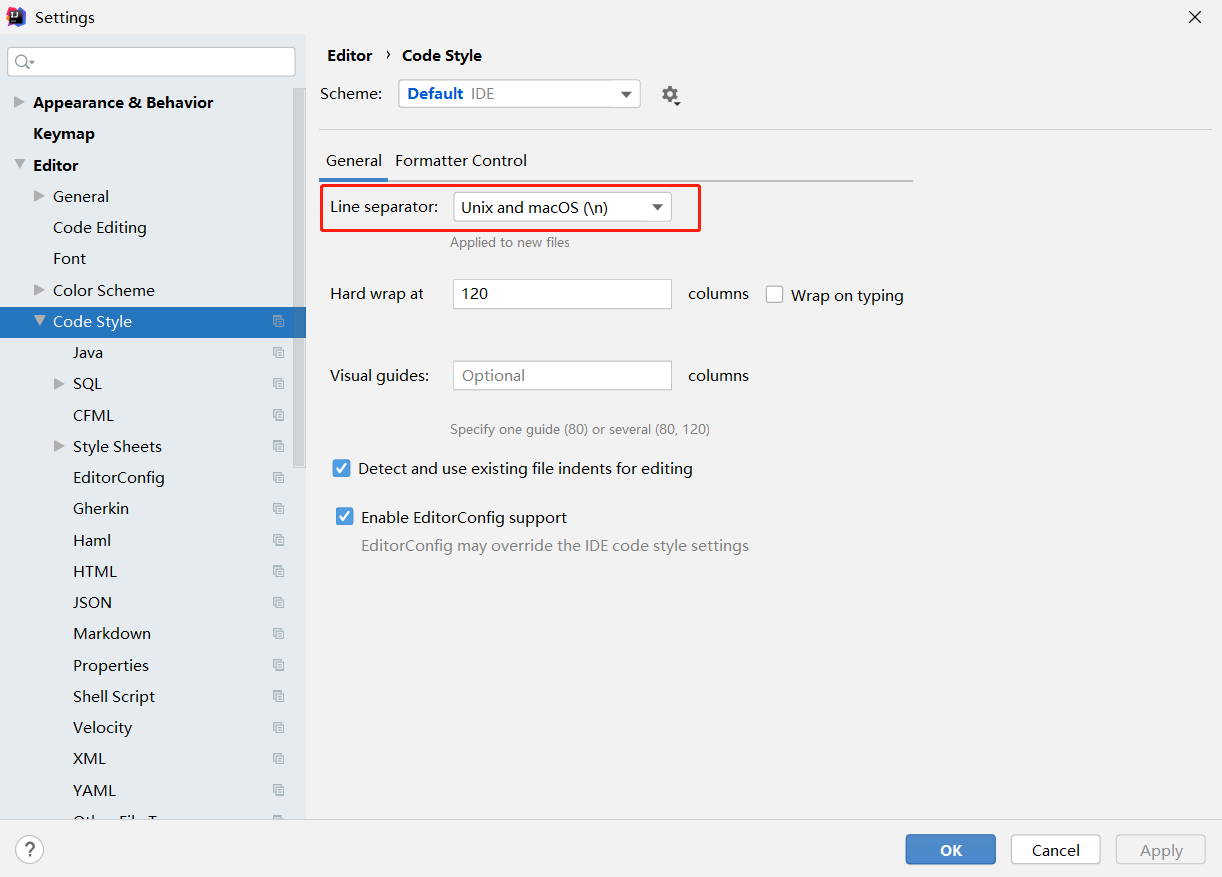
禁用TAB/开启空格缩进
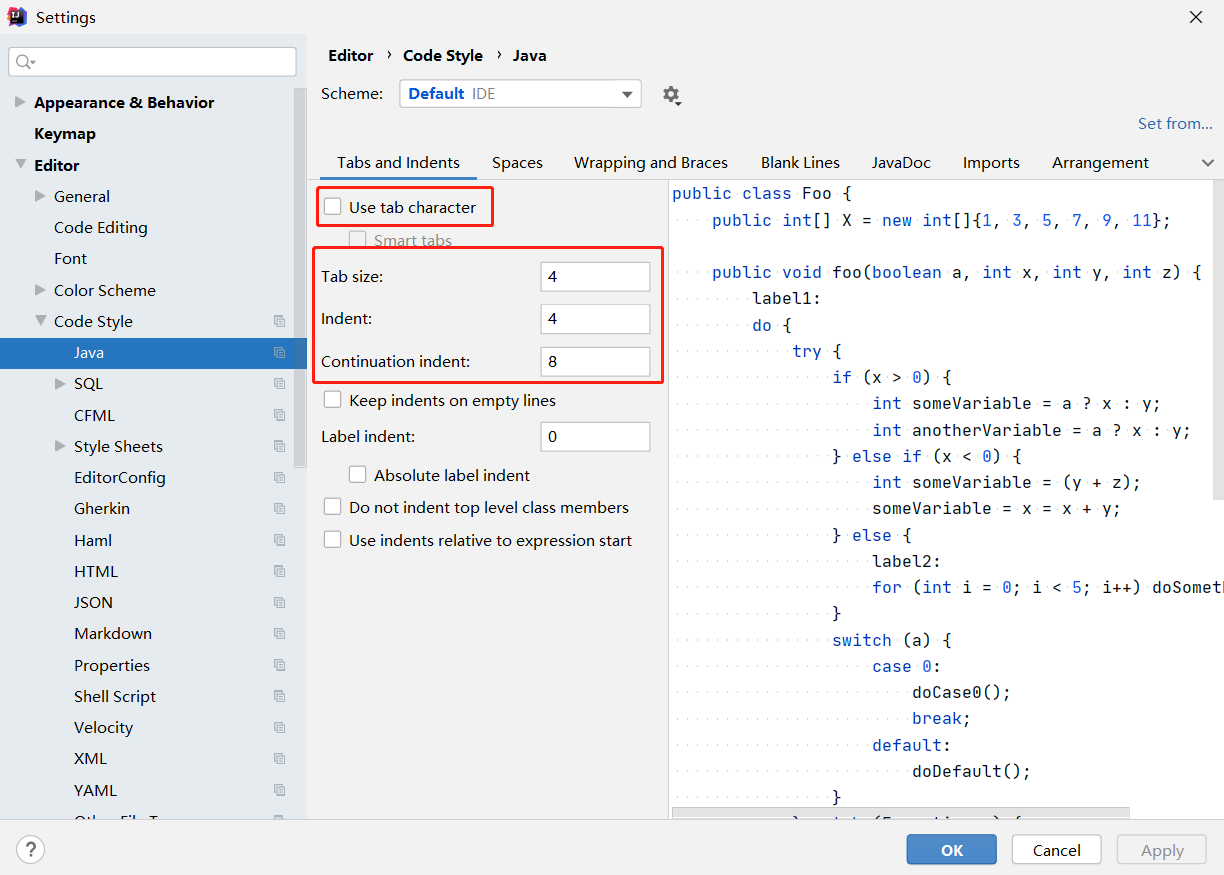
配置智能提示
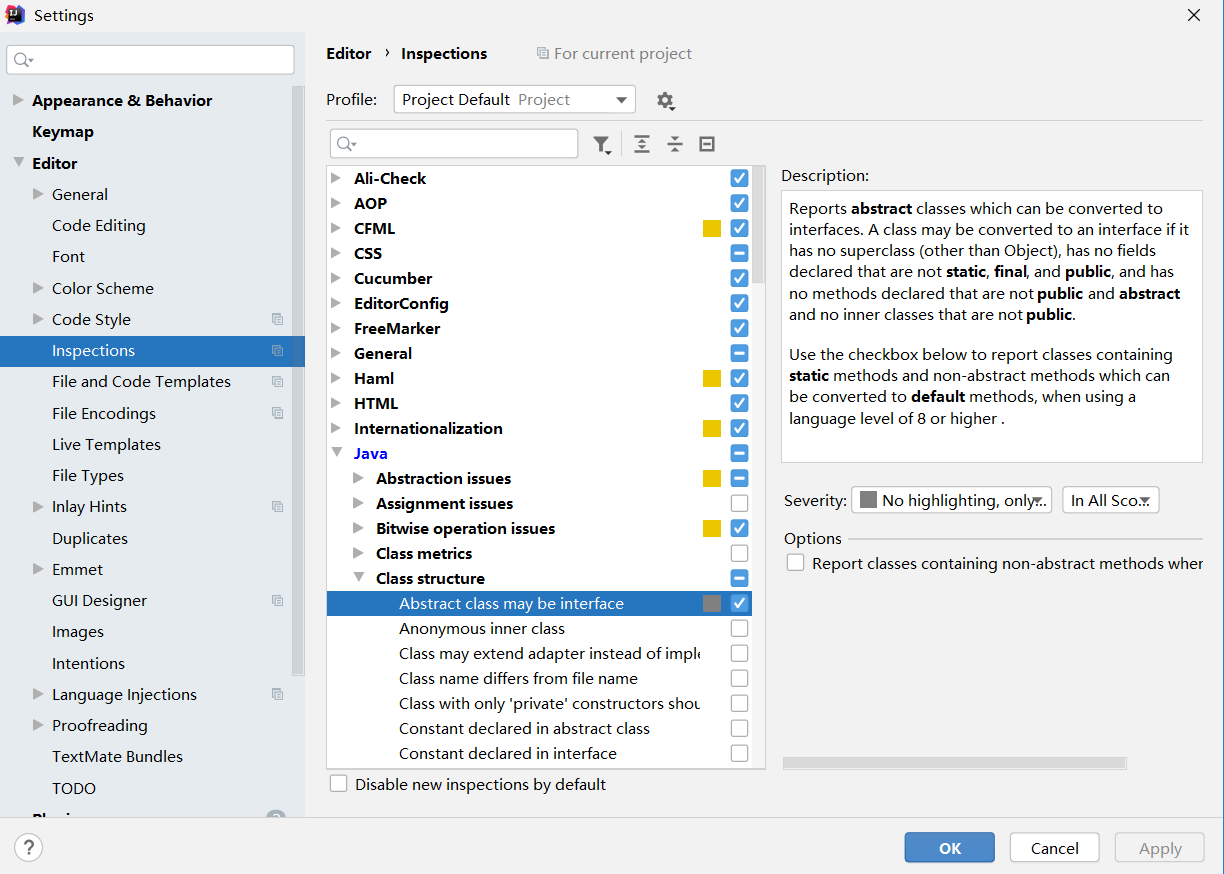
修改文件和代码模板
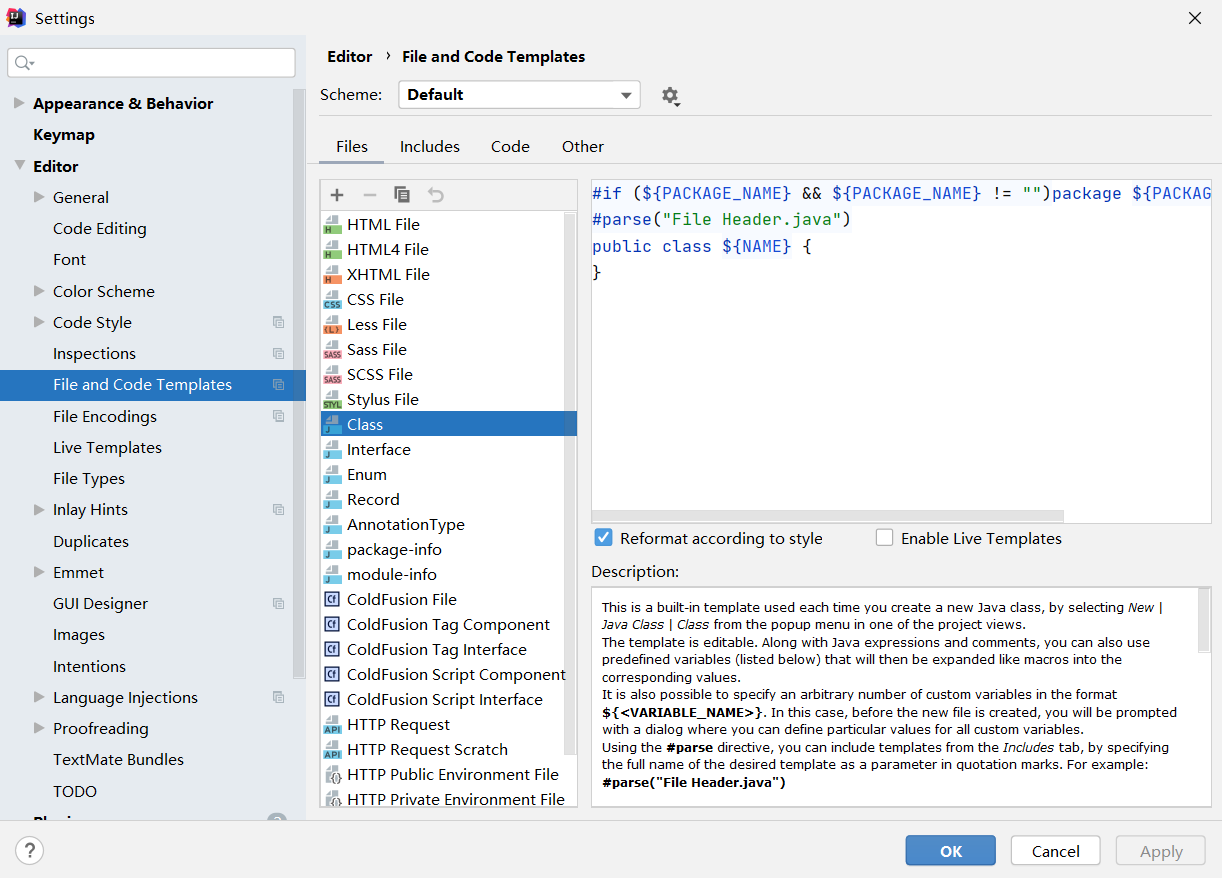
修改文件字符编码
修改快捷输入模板
4. 快捷键配置
1) 修改快捷键
2) 常用快捷键
151# 基础快捷键3Ctrl + S # 保存4Ctrl + F/R # 查找/替换文本5Ctrl + Shift + F/R # 全局查找/替换文本6Shift + Shift # 查找文件/类/方法7Ctrl + Shift + < # 跳转上一位置8Ctrl + Shift + > # 跳转下一位置9# 代码操作11Ctrl + 单击 # 跳转实现/查看引用12Ctrl + Alt + L # 格式化代码13Ctrl + H # 查找类实现(等效Ctrl+Alt+左键)14Ctrl + E # 查找最近使用文件15
5. 常用插件
安装插件
从插件市场安装或从本地磁盘安装:
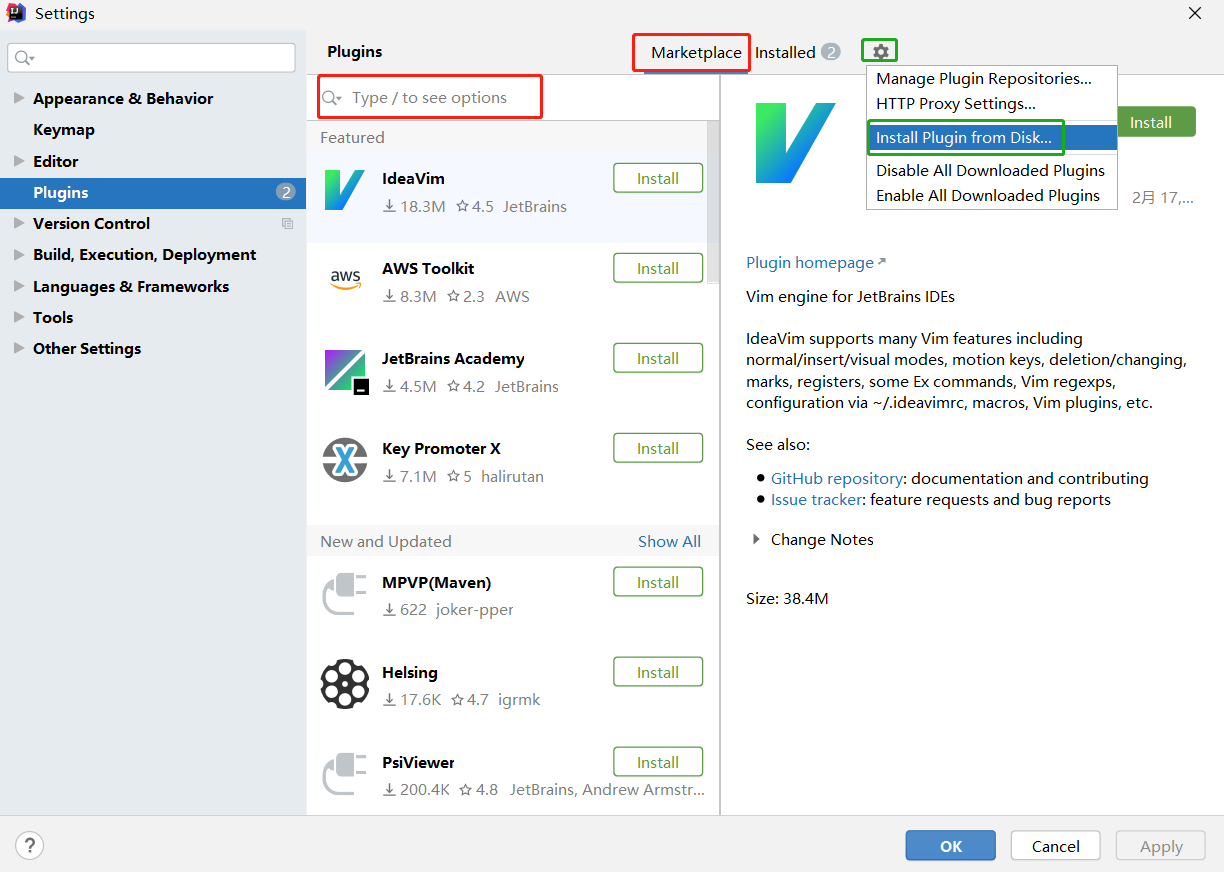
Lombok
通过注解自动生成Getter/Setter/ToString等方法,大幅减少样板代码(需配合项目依赖使用)。
Alibaba Java Coding Guidelines
遵循阿里Java开发规范,实时检测命名、注释等问题。
Jrebel and XRebel
热部署工具,修改完代码之后Ctrl+F9生效。
SonarLint
静态代码分析工具,检测潜在漏洞(如空指针异常)。
Maven Helper
可视化分析依赖冲突,快速定位问题。
Smart Input Pro
自动切换输入法及通过光标的颜色提示输入法以及大小写状态。
arthas idea
快捷生成 arthas 命令。
Free Mybatis plugin
MyBatis开发必备,实现Mapper接口与XML文件双向跳转。
Key Promoter X
可以使用快捷键操作的地方提醒你用快捷键操作。
Grep Console
可以自定义设置控制台输出颜色和过滤控制台输出。

Rainbow Brackets
使用各种鲜明的颜色来展示你的括号,效果图如下。
CodeGlance
提供一个代码的微型地图,当你的类比较多的时候可以帮忙你快速定位到要去的位置。
Save Actions
可以帮助我们在保存文件的时候:
优化导入;
格式化代码;
执行一些 quick fix
......
jclasslib
点击 View -> Show Bytecode With jclasslib可以直观地查看某个类对应的字节码文件,还可以查看类的基本信息、常量池、接口、属性、函数等信息。
Sequence Diagram
序列图可以查看调用目标方法涉及的相关类的调用关系(注意在方法名上右击)。
Statistic
可以对项目的 代码的总行数、单个文件的代码行数、注释行数等信息进行统计。
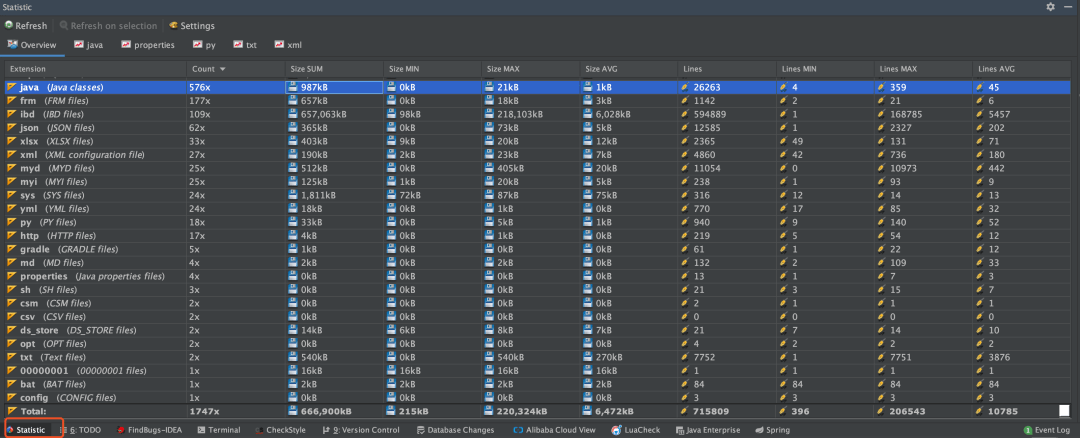
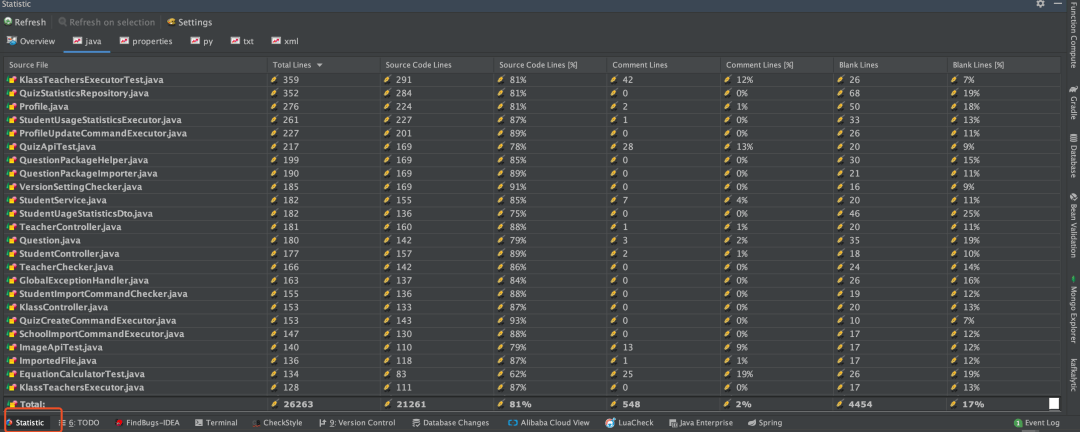
第二节 开发Java项目
1. 工程配置
SDK和Level
非maven库
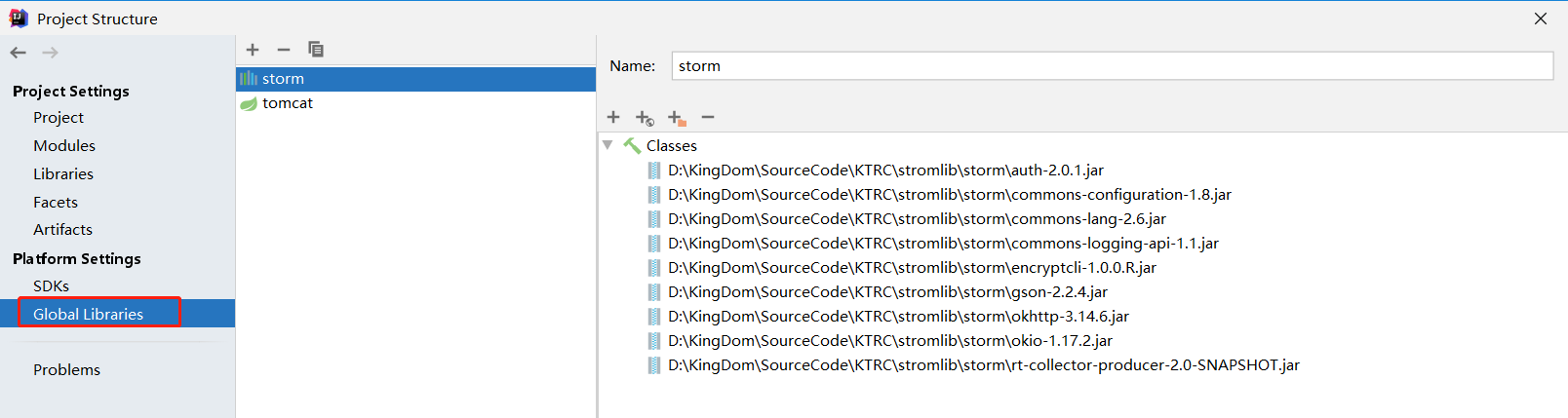
展示类成员
2. 新建项目
3. 运行项目
支持长命令行
允许允许多实例
4. 调试技巧
基本调试
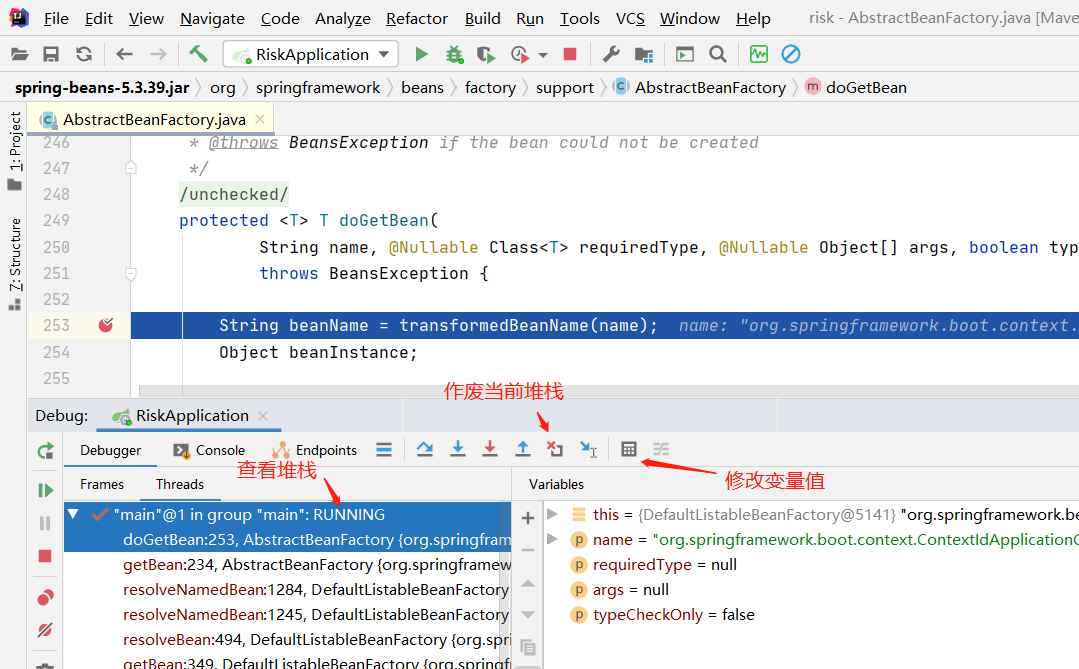
条件断点
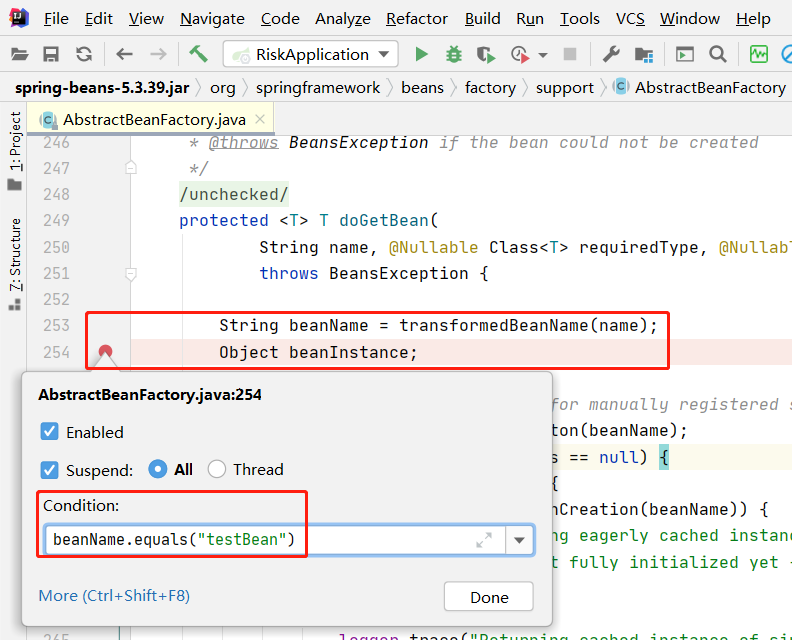
异常断点
使用Ctrl + Shift + F8可进入断点编辑窗口,点击+可以新增异常断点:
字段监视
方法监视
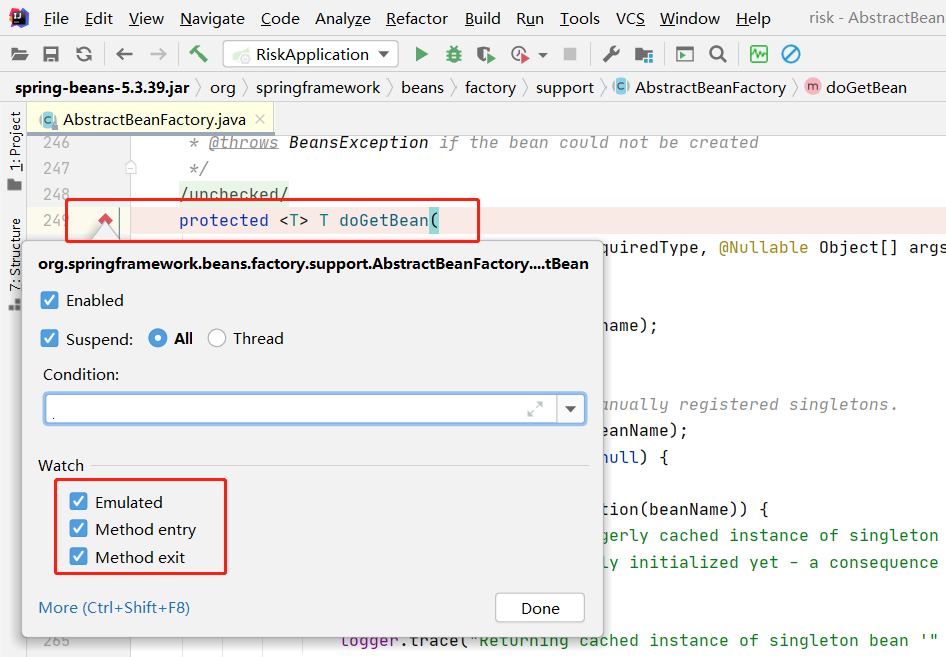
多线程调试
右击断点选择按线程挂起,中断后可选择调试的线程:
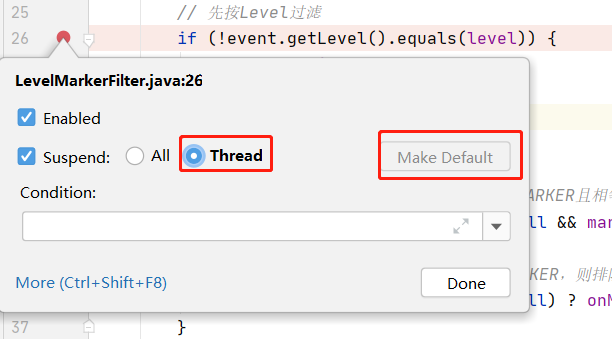
远程调试
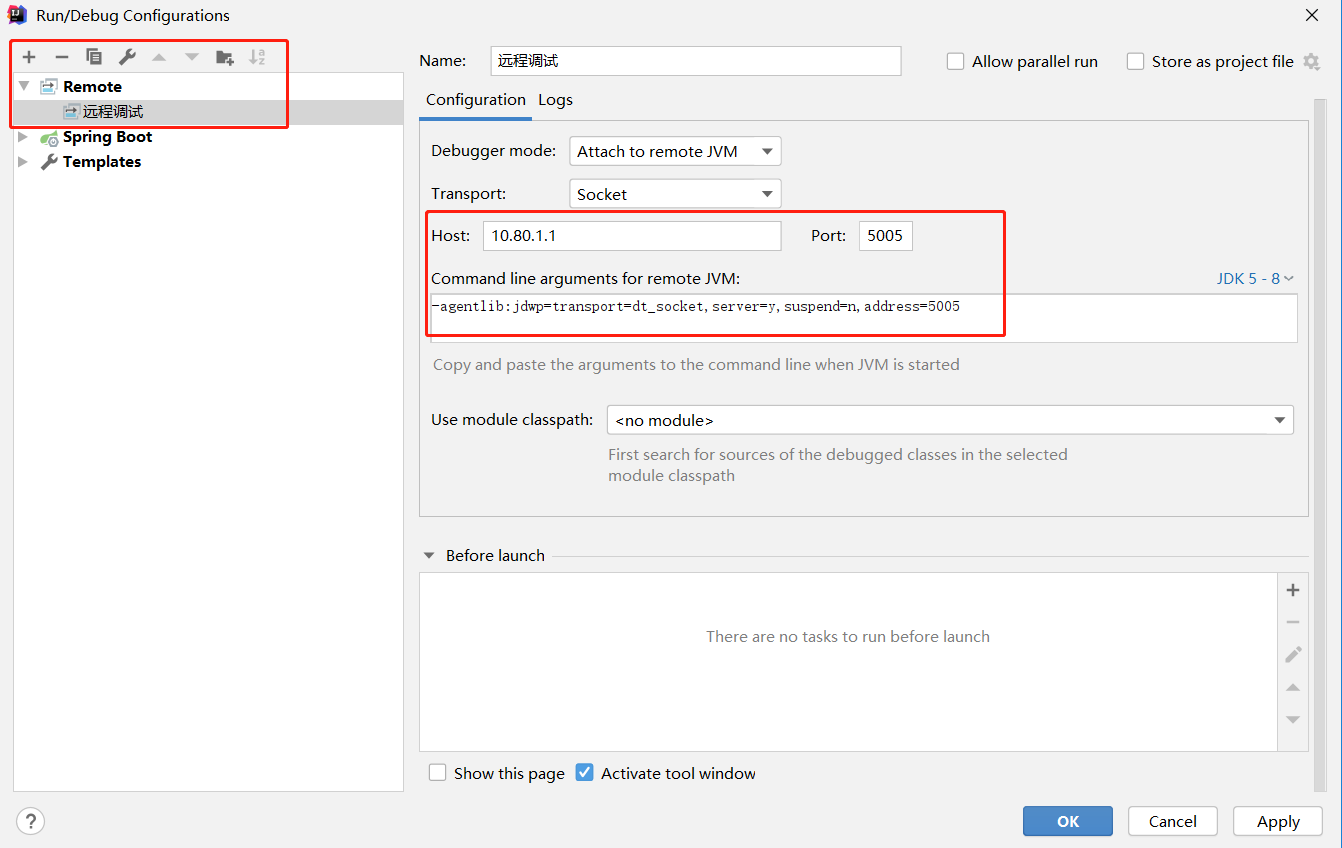
注:
远程程序需添加JVM参数:
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005。
Stream调试
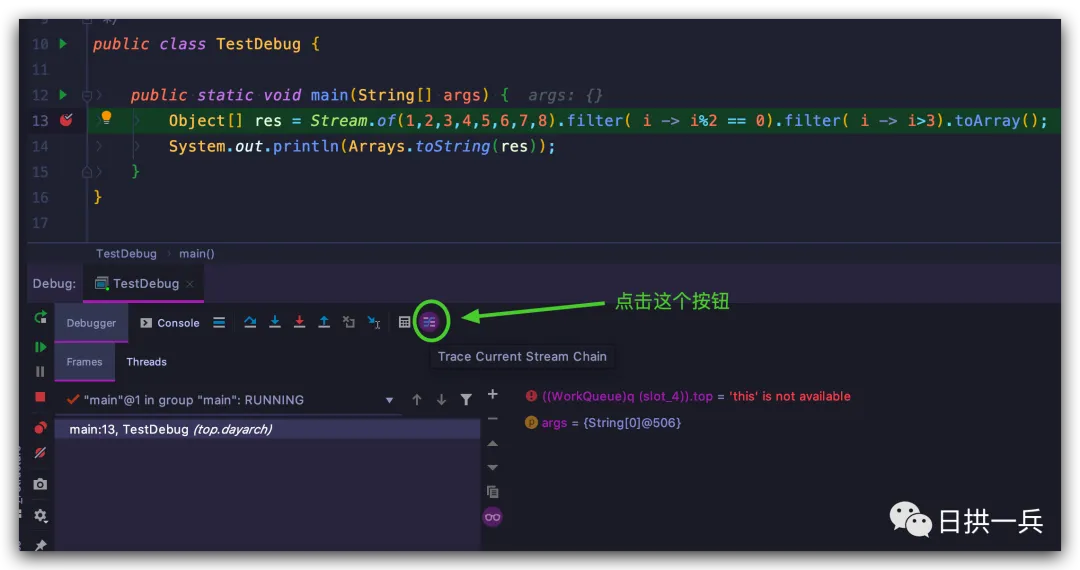
第三节 IDEA插件开发
docs/tips/plug-in-development-intro.md · SnailClimb/awesome-idea - 码云 - 开源中国
第05章_Maven
第一节 Maven简介
1. 什么是Maven?
Maven 是 Apache 开源的一款项目管理工具,主要用于依赖管理和自动化构建。
依赖管理:本地仓库+远程仓库+中央仓库提供依赖,项目/工程检索和使用依赖,并对依赖进行管理。
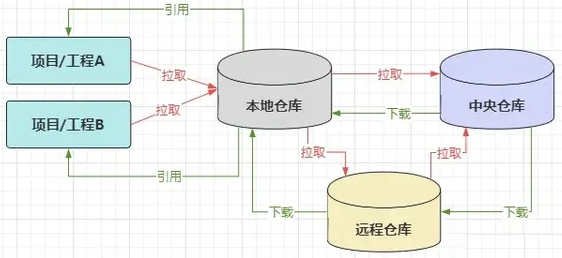
一键构建:Maven提供了三套生命周期,来对项目进行清理、构建、报告等工作。
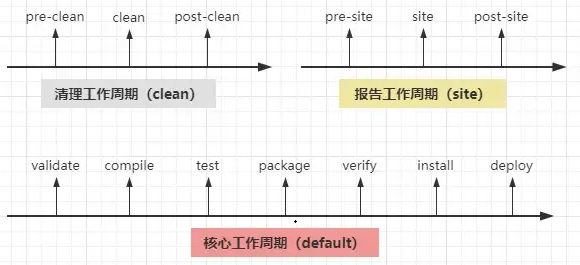
其它功能:属性管理、多模块开发、聚合工程等。
2. 安装Maven
1) 本地安装Maven
2) 解压安装:apache-maven-3.6.3-bin.zip
3) 建议配置
MAVEN_HOME:D:\Application\Apache\maven-3.6.3\bin,然后使用mvn -v查看Maven版本
4) 在IDEA中选择新安装的Maven,并按需调整配置文件和Maven仓库位置
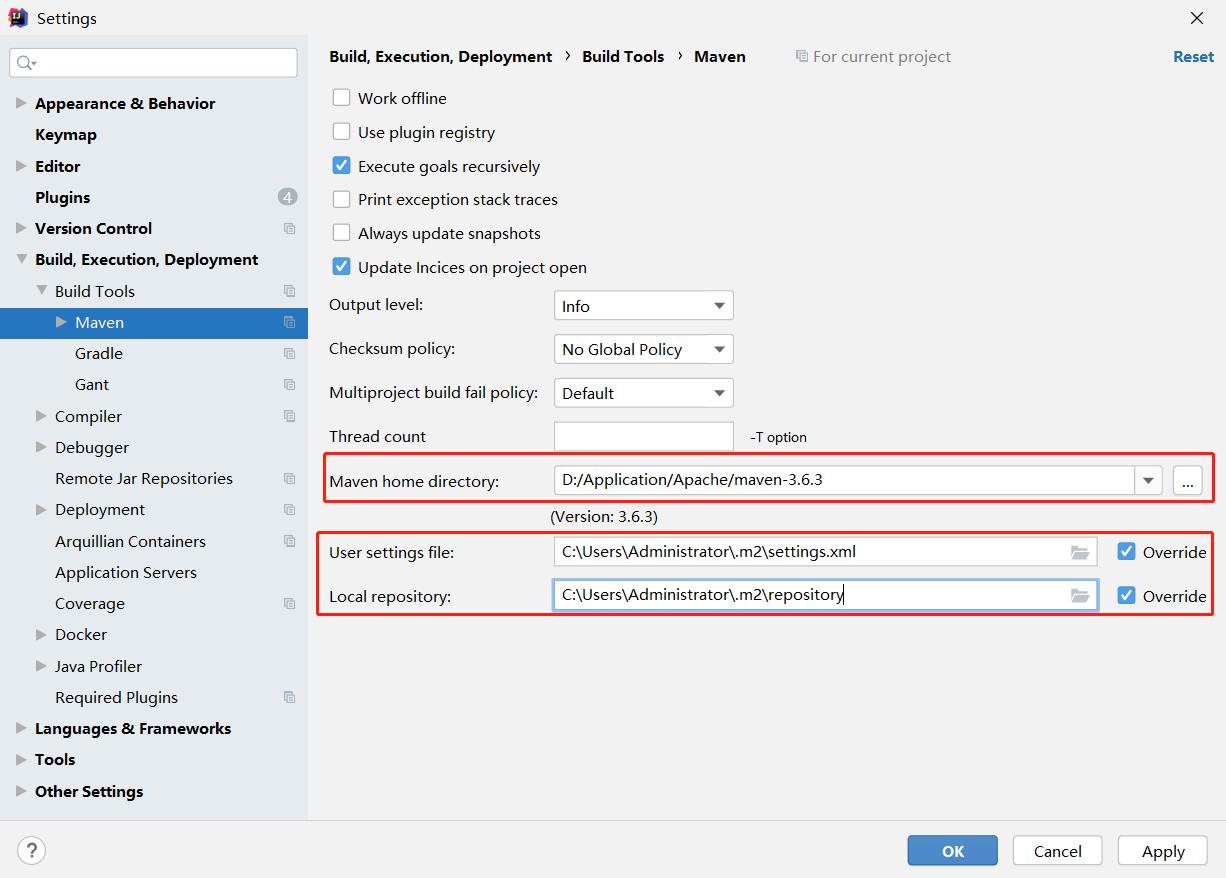
提示:
默认配置文件为${user.dir}/.m2/settings.xml,默认本地仓库位置在 ${user.dir}/.m2/repository 。
如果用户目录不存在默认配置,则会去查找安装目录。
2) 使用Maven Wrapper
Maven Wrapper 是一个用于管理和使用 Maven 的工具,它允许在没有预先安装 Maven 的情况下运行和构建 Maven 项目,并且可以确保构建过程使用正确的 Maven 版本,非常方便。
在项目中启用Maven Wrapper:
11mvn wrapper:wrapper使用Maven Wrapper打包:
11./mvnw clean & install
3. 创建Maven工程
1) Maven工程目录
Maven工程的推荐目录结构如下,可以手动创建,也可以使用IDEA创建:
61- src/main/java # 存放项目的.java 文件2- src/main/resources # 存放项目资源文件,如 spring, mybatis 配置文件3- src/test/java # # 存放所有单元测试.java 文件,如 JUnit 测试类4- src/test/resources # 测试资源文件5- target # 项目输出位置,编译后的 class 文件会输出到此目录6- pom.xml # maven 项目核心配置文件
2) 新建Maven工程
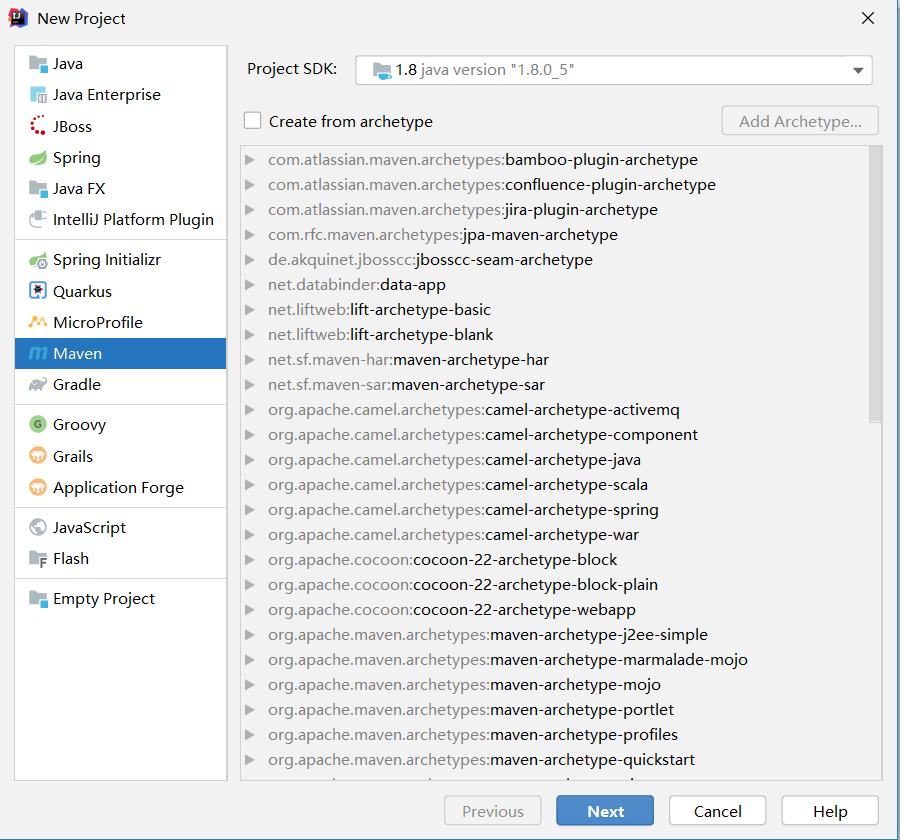
3) 修改工程配置
4) 完成Maven工程创建
4. Maven聚合工程(多模块开发)
聚合工程指一个工程允许创建多个子模块,多个子模块组成一个整体,可以统一进行项目的构建。
1) 父工程
父工程:不具备任何代码、仅有pom.xml的空项目,用来定义公共依赖、插件和配置;
父工程创建方式和普通工程类似,创建好后修改打包方式为 pom 即可,此外,一般还会删除 src 目录。
2) 子工程
子工程:编写具体代码的子项目,可以继承父工程的配置、依赖项,还可以独立拓展。
在 Project 菜单,右击父工程名称,即可选择创建子模块(New->Module...),子模块创建后会自动在父POM文件中进行关联。
5. Maven生命周期
Maven有三套生命周期,分别是清理生命周期、核心生命周期、报告生命周期,下面是各周期主要阶段的说明:
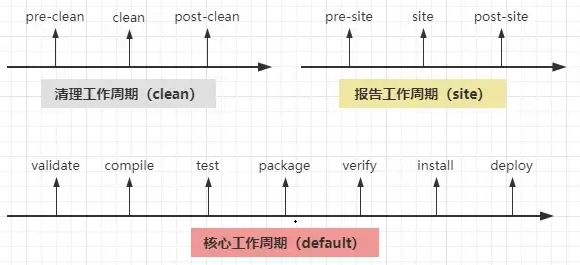
1) clean
mvn clean 是 maven 工程的清理命令,会删除编译生成的 target 目录。
maven-clean-plugin:2.5:clean:清理目录
2) compile
mvn compile命令将编译 src/main/java 下的.java文件,以及复制 src/main/resources 下的资源文件。
maven-resources-plugin:2.6:resources:复制资源文件
maven-compiler-plugin:3.1:compile:编译Java文件
输出到 {项目根目录}/target/classes目录:
3) test
mvn test命令会先执行 compile 命令,然后编译和执行 src/test/java 下的单元测试类。
maven-resources-plugin:2.6:resources:复制资源文件
maven-compiler-plugin:3.1:compile:编译Java文件
maven-resources-plugin:2.6:testResources:复制测试资源文件
maven-compiler-plugin:3.1:testCompile:编译测试Java文件
maven-surefire-plugin:2.12.4:test:执行单元测试
4) package
mvn package命令会先执行 test 命令,然后进行打包。
maven-jar-plugin:2.4:jar:打包
默认打包文件为 target/{项目名称}-1.0-SNAPSHOT.jar,是一种不包括依赖Jar包的“瘦包”。

瘦包解压后目录如下,和 classes 目录内容基本一致。
提示:
打包时可选择性的跳过测试:
mvn package -DskipTests:跳过测试代码执行(但依旧会编译测试代码)
mvn package -Dmaven.test.skip=true:跳过测试代码编译和执行
5) install
mvn install 是 maven 工程的安装命令,将 package 命令打好的包发布到本地仓库。
maven-install-plugin:2.4:install:安装到本地仓库
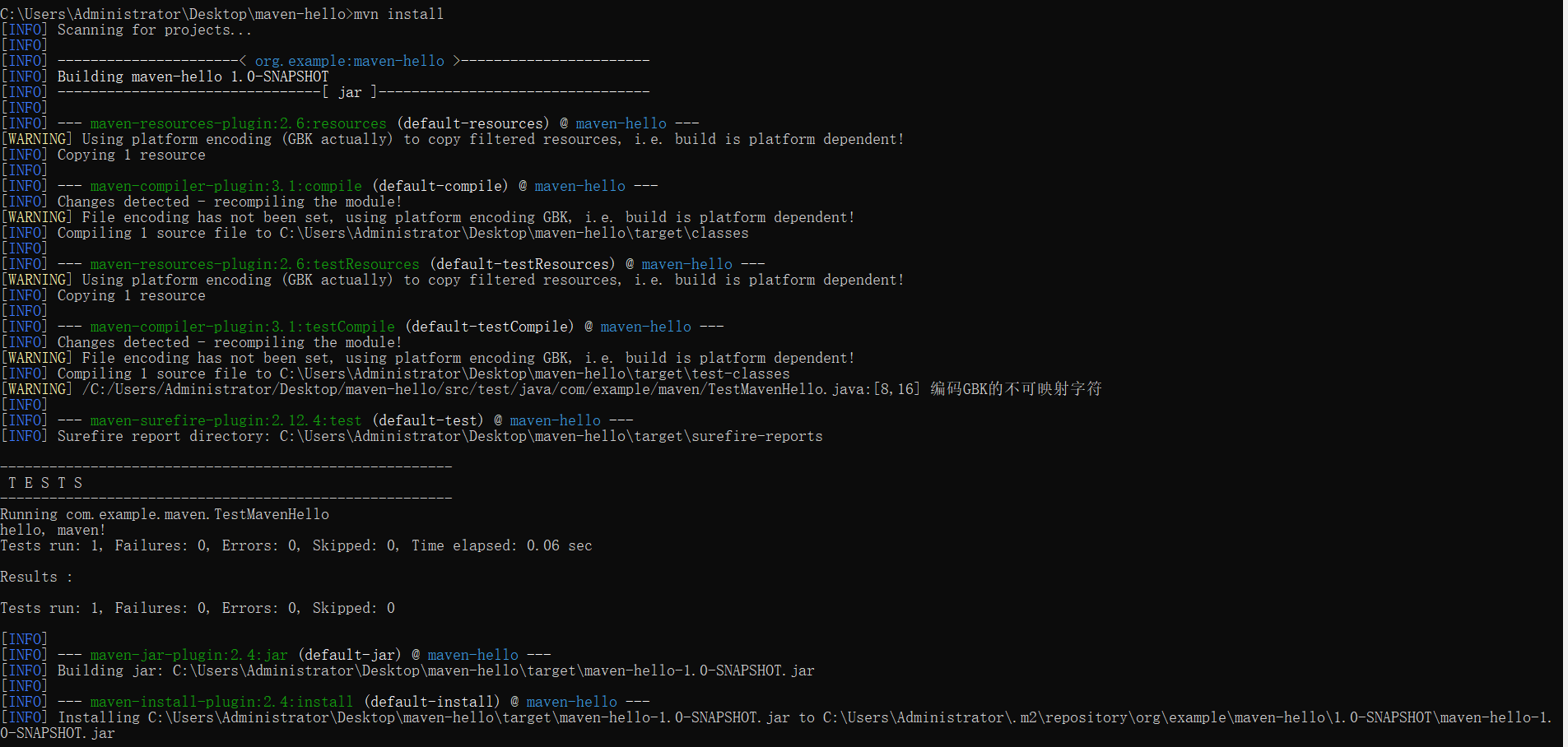

提示:
同一个生命周期中,执行后续命令时,将会先执行前置命令,如执行install前会先执行package。
多个命令可以一起执行,如
mvn clean install,将会先执行clean命令,再执行install命令。
6) deploy
mvn deploy命令用于在集成环境或者发布环境下执行,将最终版本的包拷贝到远程仓库,使得其他的开发者或者工程可以共享。
第二节 全局配置文件(setting.xml)
1. 顶层标签概览
721 2<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 5 https://maven.apache.org/xsd/settings-1.0.0.xsd"> 6 7 <!-- 本地仓库配置:默认~/.m2/repository --> 8 <localRepository>${user.home}/.m2/repository</localRepository> 9
10 <!-- 是否需要和用户交互,默认true,一般无需修改 --> 11 <interactiveMode>true</interactiveMode> 12
13 <!-- 是否通过pluginregistry.xml独立文件配置插件,默认false,一般直接配置到pom.xml --> 14 <usePluginRegistry>false</usePluginRegistry> 15
16 <!-- 是否离线模式,默认false,如果不想联网,可以开启 --> 17 <offline>false</offline> 18 19 <!-- 配置如果插件groupid未提供时自动搜索,一般很少配置 --> 20 <pluginGroups> 21 <pluginGroup>org.apache.maven.plugins</pluginGroup> 22 </pluginGroups> 23 24 <!-- 配置远程仓库服务器需要的认证信息,如用户名和密码 --> 25 <servers/> 26 27 <!-- 为仓库列表配置镜像列表 --> 28 <mirrors/> 29 30 <!-- 配置连接仓库的代理 --> 31 <proxies/> 32 33 <!-- 全局配置项目构建参数列表,一般通过它配置特定环境的定制化操作 --> 34 <profiles>35 <profile>36 <!-- profile的唯一标识 -->37 <id>test</id>38 39 <!-- 自动触发profile的条件逻辑 -->40 <activation />41 42 <!-- 扩展属性列表 -->43 <properties />44 <!-- 远程仓库列表 -->45 <repositories />46 <!-- 插件仓库列表 -->47 <pluginRepositories />48 49 </profile>50 </profiles> 51 52 <!-- 手工激活profile,通过配置id选项完成激活 --> 53 <activeProfiles> 54 <activeProfile>env-test</activeProfile> 55 </activeProfiles> 56 57 <!-- profile的扩展选项,指定某些条件下自动切换profile配置 --> 58 <activation/> 59 60 <!-- 公共属性配置 --> 61 <properties> 62 <spring.Version>5.2.8</spring.Version> 63 </properties> 64 65 <!-- 配置远程仓库列表,用于多仓库配置 --> 66 <repositories/> 67 68 <!--配置插件仓库列表--> 69 <pluginRepositories/> 70 71</settings>72
2. 仓库配置
301<repositories>2 <!--包含需要连接到远程仓库的信息 -->3 <repository>4 <!-- 远程仓库唯一标识 -->5 <id>codehausSnapshots</id>6 7 <!-- 远程仓库名称 -->8 <name>Codehaus Snapshots</name>9 10 <!-- 如何处理远程仓库里发布版本的下载 -->11 <releases>12 <!-- 是否下载发布版 -->13 <enabled>false</enabled>14 <!-- 更新频率。可选:always、daily(默认,每天更新)、interval:X(间隔X分钟)、never -->15 <updatePolicy>always</updatePolicy>16 <!-- 当Maven验证构件校验文件失败时该怎么做。可选:ignore、fail、warn -->17 <checksumPolicy>warn</checksumPolicy>18 </releases>19 20 <!--如何处理远程仓库里快照版本的下载 -->21 <snapshots/>22 23 <!-- 远程仓库URL -->24 <url>http://snapshots.maven.codehaus.org/maven2</url>25 26 <!-- 仓库布局类型。可选:default、legacy(遗留) -->27 <layout>default</layout>28 </repository>29</repositories>30
3. 服务器配置
211<servers>2 <server>3 <!-- 服务器的id,与repository元素的id相匹配 -->4 <id>server_001</id>5
6 <!-- 身份鉴权令牌 -->7 <username>my_login</username>8 <!-- 身份鉴权密码 -->9 <password>my_password</password>10 <!-- 鉴权/认证时使用的私钥文件位置 -->11 <privateKey>${usr.home}/.ssh/id_dsa</privateKey>12 <!-- 鉴权/认证时使用的私钥密码 -->13 <passphrase>some_passphrase</passphrase>14 15 <!--文件被创建时的权限 -->16 <filePermissions>664</filePermissions>17 <!--目录被创建时的权限。 -->18 <directoryPermissions>775</directoryPermissions>19 </server>20</servers>21
4. 镜像配置
191<mirrors>2 <mirror>3 <!-- 该镜像的唯一标识符。id用来区分不同的mirror元素。 -->4 <id>nexus aliyun</id>5 6 <!-- 镜像名称 -->7 <name>Nexus Aliyun</name>8 9 <!-- 该镜像的URL。构建系统会优先考虑使用该URL,而非使用默认的服务器URL。 -->10 <url>http://downloads.planetmirror.com/pub/maven2</url>11 12 <!-- 被镜像的服务器的id。13 如果我们要设置了一个Maven中央仓库(http://repo.maven.apache.org/maven2/)的镜像14 就需要将mirrorOf设置成central。15 保持和中央仓库的id central一致。 这样就能替代中央仓库的功能了 -->16 <mirrorOf>central</mirrorOf>17 </mirror>18</mirrors>19
5. 激活条件配置
371<activation>2 <!-- 默认是否激活 -->3 <activeByDefault>false</activeByDefault>4 5 <!-- 根据JDK版本匹配 -->6 <jdk>1.5</jdk>7 8 <!-- 根据系统属性匹配 -->9 <os>10 <!-- 操作系统的名字 -->11 <name>Windows XP</name>12 <!-- 操作系统所属家族 -->13 <family>Windows</family>14 <!-- 操作系统体系结构 -->15 <arch>x86</arch>16 <!-- 操作系统版本 -->17 <version>5.1.2600</version>18 </os>19 20 <!-- 根据属性名或属性值匹配 -->21 <property>22 <!-- 属性的名称 -->23 <name>mavenVersion</name>24 <!-- 属性的值(为空时则只需存在某个属性) -->25 <value>2.0.3</value>26 </property>27 28 <!-- 根据文件名匹配 -->29 <file>30 <!-- 如果指定的文件存在,则激活profile -->31 <exists>${basedir}/file2.properties</exists>32 33 <!-- 如果指定的文件不存在,则激活profile -->34 <missing>${basedir}/file1.properties</missing>35 </file>36</activation>37
6. 完整配置示例
871 2<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"4 xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">5 <pluginGroups>6 </pluginGroups>7
8 <proxies>9 </proxies>10
11 <!-- 仓库密钥配置 -->12 <servers>13 <server>14 <id>nexus-releases-kd</id>15 <username>huangyuanxin</username>16 <password>123456</password>17 </server> 18 <server>19 <id>nexus-snapshots-kd</id>20 <username>huangyuanxin</username>21 <password>123456</password>22 </server>23 <server>24 <id>nexus-kd</id>25 <username>huangyuanxin</username>26 <password>123456</password>27 </server>28 </servers>29
30 <!-- 镜像配置 -->31 <mirrors>32 <mirror>33 <id>nexus-kd</id>34 <mirrorOf>*</mirrorOf>35 <name>Nexus for Kingdom</name>36 <!-- 仓库地址,可为金证默认,也可为你的私服地址-->37 <url>http://10.200.0.5:8081/repository/public</url>38 </mirror>39 </mirrors>40
41 <!-- 策略配置 -->42 <profiles>43 44 <!-- 策略1:配置公司仓库-->45 <profile>46 <id>nexus-kd</id> 47 <repositories>48 <repository>49 <id>nexus-kd</id> 50 <url>http://10.200.0.5:8081/repository/public</url> 51 <releases>52 <enabled>true</enabled>53 </releases> 54 <snapshots>55 <enabled>true</enabled> 56 <updatePolicy>always</updatePolicy>57 </snapshots>58 </repository>59 </repositories>60 </profile>61
62 <!-- 策略2:配置阿里云仓库-->63 <profile>64 <id>aliyun</id> 65 <repositories>66 <repository>67 <id>aliyun</id> 68 <url>http://maven.aliyun.com/nexus/content/repositories/central/</url> 69 <releases>70 <enabled>true</enabled>71 </releases> 72 <snapshots>73 <enabled>true</enabled> 74 <updatePolicy>always</updatePolicy>75 </snapshots>76 </repository>77 </repositories>78 </profile> 79 </profiles>80
81 <!-- 策略激活配置 -->82 <activeProfiles>83 <activeProfile>nexus-kd</activeProfile>84 <activeProfile>aliyun</activeProfile>85 </activeProfiles>86</settings>87
第三节 项目配置文件(pom.xml)
1. 顶层元素概览
781 2<project xmlns="http://maven.apache.org/POM/4.0.0"3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">5 <!-- POM模型版本 -->6 <modelVersion>4.0.0</modelVersion>7 8 9 <!-- 1. 项目基础信息 -->10 <!-- 父工程的坐标 -->11 <parent>12 <groupId>org.springframework.boot</groupId>13 <artifactId>spring-boot-starter-parent</artifactId>14 <version>2.1.1.RELEASE</version>15 16 <!-- 父项目的pom.xml文件的相对路径,默认值是../pom.xml。 -->17 <!-- 寻找父项目的pom:构建当前项目的地方 > relativePath指定的位置 > 本地仓库 > 远程仓库 -->18 <relativePath>../pom.xml</relativePath>19 </parent>20 21 <!-- GAV坐标 -->22 <groupId>org.example</groupId>23 <artifactId>maven-hello</artifactId>24 <version>1.0-SNAPSHOT</version>25 26 <!-- 打包类型。可选:jar、war、ear、pom等 -->27 <packaging>jar</packaging> 28 29 <!-- 属性配置。通过 ${属性名} 可以引用属性 -->30 <properties>31 <spring.version>5.2.0.RELEASE</spring.version>32 </properties>33 34 <!-- 其它基础信息 -->35 <name>banseon-maven</name> <!-- 项目名称 -->36 <description>A maven project.</description> <!-- 项目描述 -->37 <inceptionYear/> <!-- 项目创建年份 -->38 <mailingLists/> <!-- 项目相关邮件列表 -->39 <developers/> <!-- 项目开发者列表 --> 40 <contributors/> <!-- 项目的其他贡献者列表 -->41 <licenses/> <!-- 项目的license -->42 <scm/> <!-- Source Control Management -->43 <organization> <!-- 项目所属组织 -->44 45
46 <!-- 2. 项目构建配置 -->47 <!-- 子模块列表 --> 48 <modules>49 <module>maven-test-01</module>50 <module>maven-test-02</module>51 </modules>52
53 <!-- 项目依赖管理 -->54 <dependencyManagement/> 55 56 <!-- 项目依赖 -->57 <dependencies/>58 59 <!-- 构建配置 --> 60 <build/> 61 62 <!-- 策略组 --> 63 <profiles/> 64 65 <!-- 其它构建配置 -->66 <prerequisites/> <!-- 构建前置条件,如Maven的最低版本 -->67 <repositories/> <!-- 远程仓库列表 -->68 <pluginRepositories/> <!-- 远程插件仓库列表 -->69 70 71 <!-- 3. 其它配置 -->72 <issueManagement/> <!-- 项目的问题管理系统,如Bugzilla, Jira, Scarab -->73 <ciManagement/> <!-- 项目的持续集成系统 --> 74 <reporting> <!-- 报表配置 -->75 <distributionManagement> <!-- 发布配置 -->76
77</project>78
2. 构建配置
1) build顶层元素概览
361<build>2 <!-- 构建目录 -->3 <finalName>${artifactId}-${version}<finalName/> <!-- 输出目标名 --> 4 <directory>target/</directory> <!-- 输出目录 -->5 <sourceDirectory>src/main/java</sourceDirectory> <!-- 业务代码目录 -->6 <scriptSourceDirectory>src/main/scripts</scriptSourceDirectory> <!-- 业务脚本目录 -->7 <outputDirectory>target/classes</outputDirectory> <!-- 业务代码编译输出目录 -->8 <testSourceDirectory>src/test/java</testSourceDirectory> <!-- 测试代码目录 -->9 <testOutputDirectory>target/test-classes</testOutputDirectory> <!-- 测试代码编译输出目录 -->10 11 <!-- 资源列表 --> 12 <resources>...<resources/> 13 14 <!-- 测试资源列表(配置方式同上) -->15 <testResources>...<testResources/> 16
17 <!-- 插件管理 --> 18 <pluginManagement>...</pluginManagement> 19 20 <!-- 插件列表(配置方式同上) --> 21 <plugins>...<plugins/> 22 23 <!-- 扩展列表 -->24 <extensions>...</extensions> 25 26 <!-- 默认目标(没有指定目标时使用) --> 27 <defaultGoal>install</defaultGoal>28 29 <!-- 过滤器属性文件列表(对src/main/resources下所有文件生效) --> 30 <!-- 注:需要在resources/resource/filtering打开开关 --> 31 <filters>32 <filter>src/main/filters/filter-${env}.properties</filter>33 </filters>34 35</build> 36
2) 资源配置
221<!-- 资源列表 --> 2<resources> 3 <resource> 4 <!-- 资源输出目录(相对于target/classes) --> 5 <targetPath>com/huangyuanxin/notes</targetPath>6 <!-- 是否需要替换配置文件中的 ${xx.xxxx} 等样式的占位符 --> 7 <filtering>true</filtering> 8 <!-- 业务资源目录-->9 <directory>src/main/resource</directory>10 <!-- 包含的模式列表 --> 11 <includes>12 <include>**/*.xml</include>13 <include>**/*.tld</include>14 <include>**/*.txt</include>15 </includes> 16 <!-- 排除的模式列表 --> 17 <excludes> 18 <exclude>**/*.properties</exclude>19 </excludes> 20 </resource> 21</resources> 22
3) 插件配置
401<!-- 插件管理 -->2<pluginManagement> 3 <plugins> 4 <plugin>5 <!-- 插件GAV坐标 -->6 <groupId>org.apache.maven.plugins</groupId>7 <artifactId>maven-source-plugin</artifactId>8 <version>2.2.1</version>9 10 <!-- 插件属性 -->11 <configuration>12 <skipSource>true</skipSource>13 </configuration>14 15 <!-- 执行配置 -->16 <executions>17 <execution>18 <id>attach-sources</id> <!-- 执行目标的标识符 -->19 <phase /> <!-- 绑定了目标的构建生命周期阶段 -->20 <goals> <!-- 配置的执行目标 -->21 <goal>jar</goal>22 </goals>23 <configuration /> <!-- 目标属性 --> 24 <inherited /> <!-- 配置是否被传播到子POM --> 25 </execution>26 </executions>27 28 <!-- 其它配置 -->29 <extensions /> <!-- 是否从该插件下载Maven扩展 -->30 <dependencies/> <!-- 插件额外依赖 --> 31 <inherited /> <!-- 配置是否被传播到子项目 --> 32 </plugin>33 </plugins> 34</pluginManagement> 35
36<!-- 插件列表(配置方式同上) --> 37<plugins> 38 <plugin>...<plugin/>39<plugins/> 40
3. 依赖配置
1) 依赖管理
421<!-- 依赖管理(依赖声明:子项目可以通过GroupId和ArtifactId来复用声明的依赖信息) -->2<dependencyManagement> 3 <dependencies> 4 <!--参见dependencies/dependency元素 --> 5 <dependency>......</dependency> 6 </dependencies> 7</dependencyManagement>8
9 10<!-- 依赖列表 --> 11<dependencies> 12 <dependency> 13 <!-- GAV坐标 -->14 <groupId>org.apache.maven</groupId> 15 <artifactId>maven-artifact</artifactId> 16 <version>3.8.1</version> 17
18 <!-- 依赖范围 -->19 <scope>test</scope> 20 <!-- 使用system范围时必须指定的系统路径 -->21 <systemPath></systemPath>22 23 <!-- 可选依赖(用于阻断依赖的传递) --> 24 <optional>true</optional> 25 26 <!-- 依赖类型(可选jar、war等) -->27 <type>jar</type>28
29 <!-- 依赖分类器(用于区分属于同一个POM,但不同构建方式的构件) -->30 <classifier></classifier>31 32 <!-- 排除依赖项(用于解决依赖冲突) --> 33 <exclusions> 34 <exclusion> 35 <artifactId>spring-core</artifactId> 36 <groupId>org.springframework</groupId> 37 </exclusion> 38 </exclusions> 39 40 </dependency> 41</dependencies> 42
2) 依赖范围
为了防止依赖冲突,以及减少不必要的打包,Maven支持设置依赖的生效范围:
compile:默认范围,在编译、测试、运行时都会生效。
provided:表示该依赖在其运行环境中已经提供,如tomcat容器提供了servlet api,则项目运行时无需重复提供该依赖。
system:与 provided 类似,但必须提供一个本地系统jar包路径,不推荐使用。
runtime:在编译时不需要,但在测试和运行时需要,如JDBC编译时只需要接口,但在测试和运行时需要 驱动Jar包。
test:仅在测试阶段需要,一般为测试相关Jar包,如Junit。
| 依赖范围 | 编译环境 | 测试环境 | 运行环境 | 示例 |
|---|---|---|---|---|
| compile | 生效 | 生效 | 生效 | 默认 |
| provided | 生效 | 生效 | 不生效 | servlet api |
| system | 生效 | 生效 | 不生效 | 不推荐使用 |
| runtime | 不生效 | 生效 | 生效 | MySql驱动包 |
| test | 不生效 | 生效 | 不生效 | Junit |
81<dependency>2 <groupId>org.springframework.boot</groupId>3 <artifactId>spring-boot-starter-test</artifactId>4 <version>2.1.8.RELEASE</version>5 6 <!-- 测试相关Jar包设置为测试范围 -->7 <scope>test</scope>8</dependency>扩展:
plugin:主要用于插件的依赖管理,确保插件的依赖只在插件的生命周期中被加载。
import:用于导入dependencyManagement配置。81<!-- 在当前工程导入spring-cloud-alibaba-dependencies中的dependencyManagement配置 -->2<dependency>3<groupId>com.alibaba.cloud</groupId>4<artifactId>spring-cloud-alibaba-dependencies</artifactId>5<version>${spring-cloud-alibaba.version}</version>6<type>pom</type>7<scope>import</scope>8</dependency>
3) 依赖传递
依赖传递指引入一个Jar包时,如果该Jar包依赖于其他Jar包(类库),则当前工程也会将它们全都引入,最终会形成一个树形依赖。

提示:
一级依赖也称为直接依赖,二级及以后的依赖被称为间接依赖。
在聚合工程中,父工程也会向子工程传递依赖。
4) 依赖冲突
依赖冲突指多个依赖包引入了同一份类库的不同版本时,可能会导致编译错误或运行时异常。但大都情况下,Maven会按照如下原则来自动解决依赖冲突:
层级优先原则:依赖层级越低,则优先级越高,如下图 spring-web/spring-core 的优先级大于 spring-web/spring-beans/spring-core 。
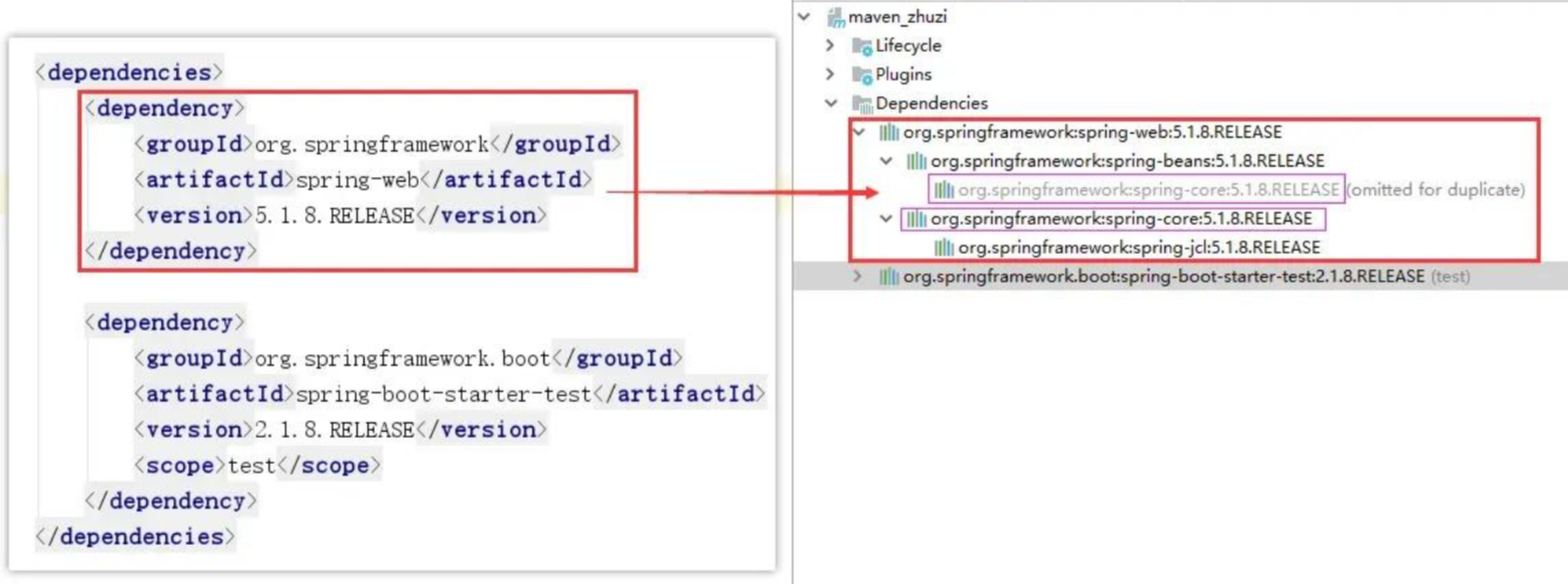
声明优先原则:在相同层级出现同版本的类库时,则先声明的优先级高。如下在 spring-web 中先声明的 spring-core 生效。
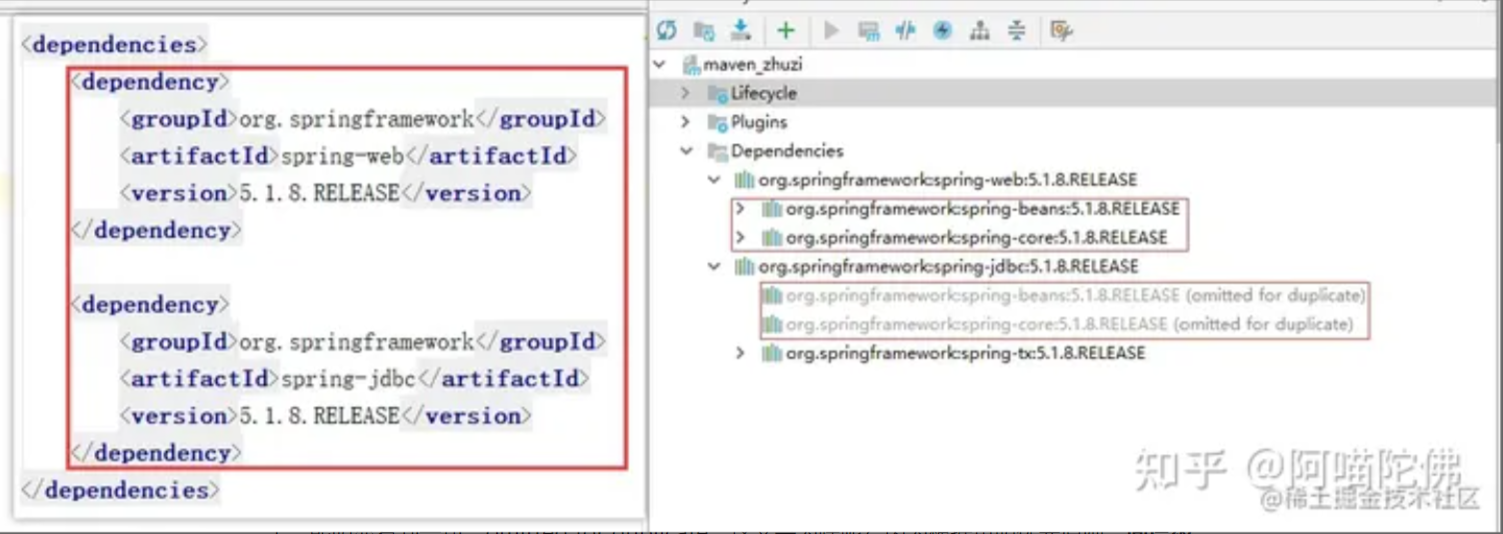
配置优先原则:在相同层级出现不同版本的类库时,则后配置的优先级高。如下后配置的 5.1.2 版本生效。
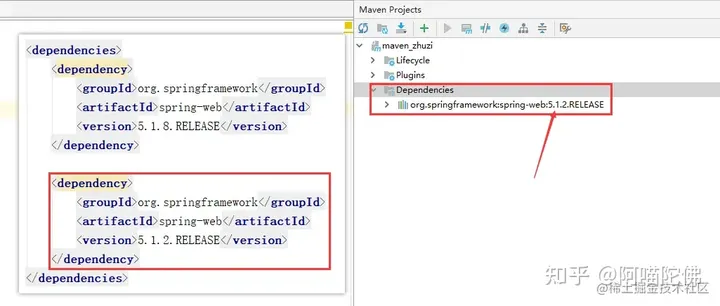
5) 解决依赖冲突
当Maven无法为我们自动解决依赖冲突时,它会提供错误信息,这时需要我们手动解决依赖冲突:
修改版本号一致:升级/降级某些依赖项的版本,从而让不同依赖引入的同一类库,保持一致的版本号。
排除特定依赖:排除特定的间接依赖项来防止依赖重复引入。
121<dependency>2<groupId>org.springframework</groupId>3<artifactId>spring-web</artifactId>4<version>5.1.8.RELEASE</version>5<exclusions>6<!-- 排除web包依赖的beans包 -->7<exclusion>8<groupId>org.springframework</groupId>9<artifactId>spring-beans</artifactId>10</exclusion>11</exclusions>12</dependency>隐藏依赖(多工程聚合项目):引入一个依赖时,不引入它的间接依赖。
81<dependency>2<groupId>org.springframework</groupId>3<artifactId>spring-aop</artifactId>4<version>5.1.8.RELEASE</version>56<!-- true:开启依赖隐藏,不会引入该依赖的间接依赖 -->7<optional>true</optional>8</dependency>
4. 发布配置
481<!--项目分发信息,在执行mvn deploy后表示要发布的位置。有了这些信息就可以把网站部署到远程服务器或者把构件部署到远程仓库。 --> 2<distributionManagement> 3 <!--部署项目产生的构件到远程仓库需要的信息 --> 4 <repository> 5 <!--是分配给快照一个唯一的版本号(由时间戳和构建流水号)?还是每次都使用相同的版本号?参见repositories/repository元素 --> 6 <uniqueVersion /> 7 <id>xxx-maven2</id> 8 <name>xxx maven2</name> 9 <url>file://${basedir}/target/deploy</url> 10 <layout /> 11 </repository> 12 <!--构件的快照部署到哪里?如果没有配置该元素,默认部署到repository元素配置的仓库,参见distributionManagement/repository元素 --> 13 <snapshotRepository> 14 <uniqueVersion /> 15 <id>xxx-maven2</id> 16 <name>xxx-maven2 Snapshot Repository</name> 17 <url>scp://svn.xxxx.com/xxx:/usr/local/maven-snapshot</url> 18 <layout /> 19 </snapshotRepository> 20 <!--部署项目的网站需要的信息 --> 21 <site> 22 <!--部署位置的唯一标识符,用来匹配站点和settings.xml文件里的配置 --> 23 <id>banseon-site</id> 24 <!--部署位置的名称 --> 25 <name>business api website</name> 26 <!--部署位置的URL,按protocol://hostname/path形式 --> 27 <url> 28 scp://svn.baidu.com/xxx:/var/www/localhost/web 29 </url> 30 </site> 31 <!--项目下载页面的URL。如果没有该元素,用户应该参考主页。使用该元素的原因是:帮助定位那些不在仓库里的构件(由于license限制)。 --> 32 <downloadUrl /> 33 <!--如果构件有了新的group ID和artifact ID(构件移到了新的位置),这里列出构件的重定位信息。 --> 34 <relocation> 35 <!--构件新的group ID --> 36 <groupId /> 37 <!--构件新的artifact ID --> 38 <artifactId /> 39 <!--构件新的版本号 --> 40 <version /> 41 <!--显示给用户的,关于移动的额外信息,例如原因。 --> 42 <message /> 43 </relocation> 44 <!--给出该构件在远程仓库的状态。不得在本地项目中设置该元素,因为这是工具自动更新的。有效的值有:none(默认),converted(仓库管理员从Maven 45 1 POM转换过来),partner(直接从伙伴Maven 2仓库同步过来),deployed(从Maven 2实例部署),verified(被核实时正确的和最终的)。 --> 46 <status /> 47</distributionManagement> 48
5. 策略配置(多环境配置示例)
首先,在父POM中添加依赖和插件,来支持yml配置读取pom配置文件中的参数:
181<!-- 开启 yml 文件的 ${} 取值支持 -->2<dependency>3 <groupId>org.springframework.boot</groupId>4 <artifactId>spring-boot-configuration-processor</artifactId>5 <version>2.1.5.RELEASE</version>6 <optional>true</optional>7</dependency>8
9<!-- 添加插件,将项目的资源文件复制到输出目录中 -->10<plugin>11 <groupId>org.apache.maven.plugins</groupId>12 <artifactId>maven-resources-plugin</artifactId>13 <version>3.2.0</version>14 <configuration>15 <encoding>UTF-8</encoding>16 <useDefaultDelimiters>true</useDefaultDelimiters>17 </configuration>18</plugin>接下来,在pom.xml中配置开发、测试、生产三套配置策略:
301<profiles>2 <!-- 开发环境 -->3 <profile>4 <id>dev</id>5 <properties>6 <profile.active>dev</profile.active>7 </properties>8 </profile>9 10 <!-- 测试环境 -->11 <profile>12 <id>test</id>13 <properties>14 <profile.active>test</profile.active>15 </properties>16 </profile>17 18 <!-- 生产环境 -->19 <profile>20 <id>prod</id>21 <properties>22 <profile.active>prod</profile.active>23 </properties>24 <activation>25 <!-- 默认激活 -->26 <activeByDefault>true</activeByDefault>27 </activation>28 </profile>29 30</profiles>通过IDEA的Maven窗口,可以看到如下选项(命令行方式:mvn clean install -P prod):
然后,就可以在SpringBoot的属性配置文件(如application.yml)中,可以读取当前启用的环境,并使用不同的配置了:
241
2# 读取当前启用的环境3spring4 profiles5 active$profile.active6
7# 根据不同环境使用不同端口8---9spring10 profilesdev11server12 port8013---14spring15 profilesprod16server17 port8118---19spring20 profilestest21server22 port8223---24
执行流程步骤如下:
启动时,pom.xml根据勾选的Profiles,使用相应的环境配置(如dev);
yml中${profile.active}会读到dev,使用dev配置组;
yml中的dev配置组,server.port=80,所以最终通过80端口启动。
第四节 常用Maven插件
1. Maven插件简介
Maven 本质上是一个插件执行框架,所有的执行过程,都是由一个一个插件独立完成的。像咱们日常使用到的 install、clean、deploy 等命令,其实底层都是一个一个的 Maven 插件。
注意:
关于 Maven 的核心插件可以参考官方的这篇文档:https://maven.apache.org/plugins/index.html 。
本地默认插件路径:
${user.home}/.m2/repository/org/apache/maven/plugins
2. maven-compiler-plugin
111<plugin>2 <groupId>org.apache.maven.plugins</groupId>3 <artifactId>maven-compiler-plugin</artifactId>4 <configuration>5 <!--设置编译级别-->6 <source>1.8</source>7 <target>1.8</target>8 <encoding>UTF-8</encoding>9 </configuration>10</plugin>11
3. maven-surefire-plugin
151<plugin>2 <artifactId>maven-surefire-plugin</artifactId>3 <version>2.22.1</version>4 <configuration>5 <skipTests>true</skipTests>6 <includes>7 <!-- 指定要执行的测试用例 -->8 <include>**/XXX*Test.java</include>9 </includes>10 <excludes>11 <!-- 执行要跳过的测试用例 -->12 <exclude>**/XXX*Test.java</exclude>13 </excludes>14 </configuration>15</plugin>
4. maven-jar-plugin
161<plugin>2 <groupId>org.apache.maven.plugins</groupId>3 <artifactId>maven-jar-plugin</artifactId>4 <version>3.2.0</version>5 <configuration>6 <archive>7 <manifest>8 <mainClass>${mainClass}</mainClass>9 <addDefaultImplementationEntries>true</addDefaultImplementationEntries>10 </manifest>11 </archive>12 <includes>13 <include>com/**/*</include>14 </includes>15 </configuration>16</plugin>
5.maven-source-plugin
161<plugin>2 <groupId>org.apache.maven.plugins</groupId>3 <artifactId>maven-source-plugin</artifactId>4 <version>2.2.1</version>5 <configuration>6 <skipSource>true</skipSource>7 </configuration>8 <executions>9 <execution>10 <id>attach-sources</id>11 <goals>12 <goal>jar</goal>13 </goals>14 </execution>15 </executions>16</plugin>
6. maven-dependency-plugin
171<plugin>2 <artifactId>maven-dependency-plugin</artifactId>3 <executions>4 <execution>5 <id>copy-dependencies</id>6 <phase>generate-resources</phase>7 <goals>8 <goal>copy-dependencies</goal>9 </goals>10 <configuration>11 <includeScope>runtime</includeScope>12 <outputDirectory>${project.build.directory}/dependence</outputDirectory>13 <overWriteIfNewer>true</overWriteIfNewer>14 </configuration>15 </execution>16 </executions>17</plugin>
7. maven-assembly-plugin
201<plugin>2 <groupId>org.apache.maven.plugins</groupId>3 <artifactId>maven-assembly-plugin</artifactId>4 <configuration>5 <finalName>risk-${project.version}</finalName>6 <appendAssemblyId>false</appendAssemblyId>7 <descriptors>8 <descriptor>src/assembly/assembly.xml</descriptor>9 </descriptors>10 </configuration>11 <executions>12 <execution>13 <id>make-assembly</id>14 <phase>package</phase>15 <goals>16 <goal>single</goal>17 </goals>18 </execution>19 </executions>20</plugin>
第五节 Maven打包部署
1. SpringBoot项目-可执行Jar包
参考SpringBoot学习笔记的[SpringBoot-Repackage]项目。
2. SpringBoot项目-分层打包
参考SpringBoot学习笔记的[risk-registry-eureka-server-bootapp]项目。
第六节 私服搭建
1. 私服简介和搭建
参考:https://blog.csdn.net/m0_75260099/article/details/147542756
第06章_Git&Svn
第一节 Git
第二节 SVN
参考“文档资料”相关文档。
第07章_Arthas
第一节 Arthas简介
1. 什么是Arthas?
Arthas 是阿里巴巴开源的 Java 诊断工具,用于实时监控和诊断 Java 应用问题,支持查看线程、类加载、方法调用等信息,无需重启应用即可排查问题,适用于线上环境。
2. 安装Arthas
1) 在线安装
91# 下载2curl -O https://arthas.aliyun.com/arthas-boot.jar3
4# 启动5java -jar arthas-boot.jar6
7# 启动(阿里云镜像加速)8java -jar arthas-boot.jar --repo-mirror aliyun --use-http9
2) 离线安装
91# 上传全量包2arthas-packaging-4.0.5-bin.zip3
4# 解压5unzip arthas-packaging-4.0.5-bin.zip6
7# 启动 8java -jar arthas-boot.jar9
第二节 常用命令
1. 命令列表
1) JVM 相关
dashboard - 当前系统的实时数据面板
getstatic - 查看类的静态属性
heapdump - dump java heap, 类似 jmap 命令的 heap dump 功能
jvm - 查看当前 JVM 的信息
logger - 查看和修改 logger
mbean - 查看 Mbean 的信息
memory - 查看 JVM 的内存信息
ognl - 执行 ognl 表达式
perfcounter - 查看当前 JVM 的 Perf Counter 信息
sysenv - 查看 JVM 的环境变量
sysprop - 查看和修改 JVM 的系统属性
thread - 查看当前 JVM 的线程堆栈信息
vmoption - 查看和修改 JVM 里诊断相关的 option
vmtool - 从 jvm 里查询对象,执行 forceGc
2) class/classloader 相关
classloader - 查看 classloader 的继承树,urls,类加载信息,使用 classloader 去 getResource
dump - dump 已加载类的 byte code 到特定目录
jad - 反编译指定已加载类的源码
mc - 内存编译器,内存编译
.java文件为.class文件redefine - 加载外部的
.class文件,redefine 到 JVM 里retransform - 加载外部的
.class文件,retransform 到 JVM 里sc - 查看 JVM 已加载的类信息
sm - 查看已加载类的方法信息
3) monitor/watch/trace 相关
monitor - 方法执行监控
stack - 输出当前方法被调用的调用路径
trace - 方法内部调用路径,并输出方法路径上的每个节点上耗时
tt - 方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
watch - 方法执行数据观测
注意:
这些命令,都通过字节码增强技术来实现的,会在指定类的方法中插入一些切面来实现数据统计和观测,因此在线上、预发使用时,请尽量明确需要观测的类、方法以及条件,诊断结束要执行
stop或将增强过的类执行reset命令。
4) profiler/火焰图
profiler - 使用async-profiler在新窗口打开对应用采样,生成火焰图
jfr - 动态开启关闭 JFR 记录
5) 基础命令
base64 - base64 编码转换,和 linux 里的 base64 命令类似
cat - 打印文件内容,和 linux 里的 cat 命令类似
cls - 清空当前屏幕区域
echo - 打印参数,和 linux 里的 echo 命令类似
grep - 匹配查找,和 linux 里的 grep 命令类似
help - 查看命令帮助信息
history - 打印命令历史
keymap - Arthas 快捷键列表及自定义快捷键
pwd - 返回当前的工作目录,和 linux 命令类似
quit - 退出当前 Arthas 客户端,其他 Arthas 客户端不受影响
reset - 重置增强类,将被 Arthas 增强过的类全部还原,Arthas 服务端关闭时会重置所有增强过的类
session - 查看当前会话的信息
stop - 关闭 Arthas 服务端,所有 Arthas 客户端全部退出
tee - 复制标准输入到标准输出和指定的文件,和 linux 里的 tee 命令类似
version - 输出当前目标 Java 进程所加载的 Arthas 版本号
6) 其它命令
2. 常用命令示例
481# 打开监控2dashboard3
4# 生成堆dump文件5heapdump6
7# 查看线程信息8thread # 查询线程信息9thread -b # 查看持锁进程10
11# 查看虚拟机信息12jvm13
14# 反编译类15jad com.szkingdom.kfms.KfmsBootApplication 16
17# 重新加载类18redefine /root/Xxxx.class19
20# 打印参数返回值异常21watch com.szkingdom.kfms.base.utils.DateUtils isValidDate '{params,returnObj,throwExp}' -n 5 -x 3 22
23# 打印方法调用栈24stack com.szkingdom.kfms.base.utils.DateUtils getNextDate -n 5 25
26# 统计方法耗时27[arthas@209808]$ monitor com.szkingdom.kfms.base.utils.DateUtils getNextDate -n 10 --cycle 1028Press Q or Ctrl+C to abort.29Affect(class count: 1 , method count: 1) cost in 209 ms, listenerId: 630 timestamp class method total succes fail avg-rt( fail-ra31 s ms) te32-------------------------------------------------------------------------------------------------------------------33 2022-11-17 00:40 com.szkingdom.kfms.base. getNextDate 5 5 0 0.24 0.00%34 :07 utils.DateUtils35
36# 打印方法耗时37trace 全类名 方法名38trace com.szkingdom.kfms.custfundsett.endofday.QueryNextTrdDay queryNextTrdDate39trace com.szkingdom.kfms.base.utils.DateUtils getNextDate40trace com.szkingdom.kfms.base.utils.DateUtils getNextDate -n 5 --skipJDKMethod false 41
42# 时空隧道(方法回放)43tt44
45# 热力图46profiler start47profiler stop48
第08章 Jenkins
第一节 Jenkins简介
1. 什么是Jenkins?
Jenkins是一个基于Java开发的持续集成工具,通过众多插件来完成一系列复杂的功能。
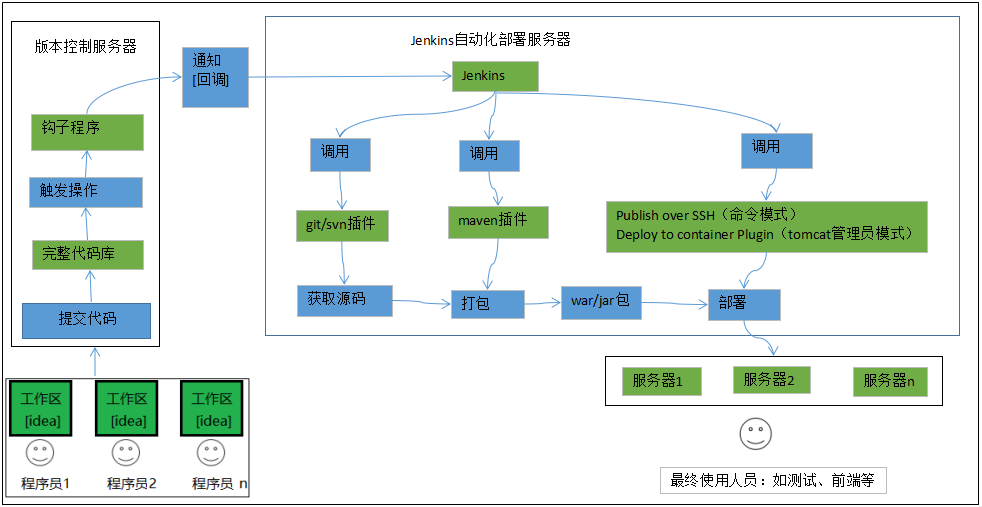
提示:
Jenkins中文网:https://www.jenkins.io/zh/。
2. 安装部署
311) 下载:https://www.jenkins.io/download/ # 或 http://mirrors.jenkins.io/war-stable/latest/jenkins.war22) 运行:java -jar jenkins.war --httpPort=8080 # 初次运行时需输入初始密码、安装插件、设置管理员账户33) 访问:http://localhost:8080
第二节 Pipeline简介
1. 创建一个Pipeline
点击“新建Item”
输入任务名称,选择“Pipeline”,点击“确定”
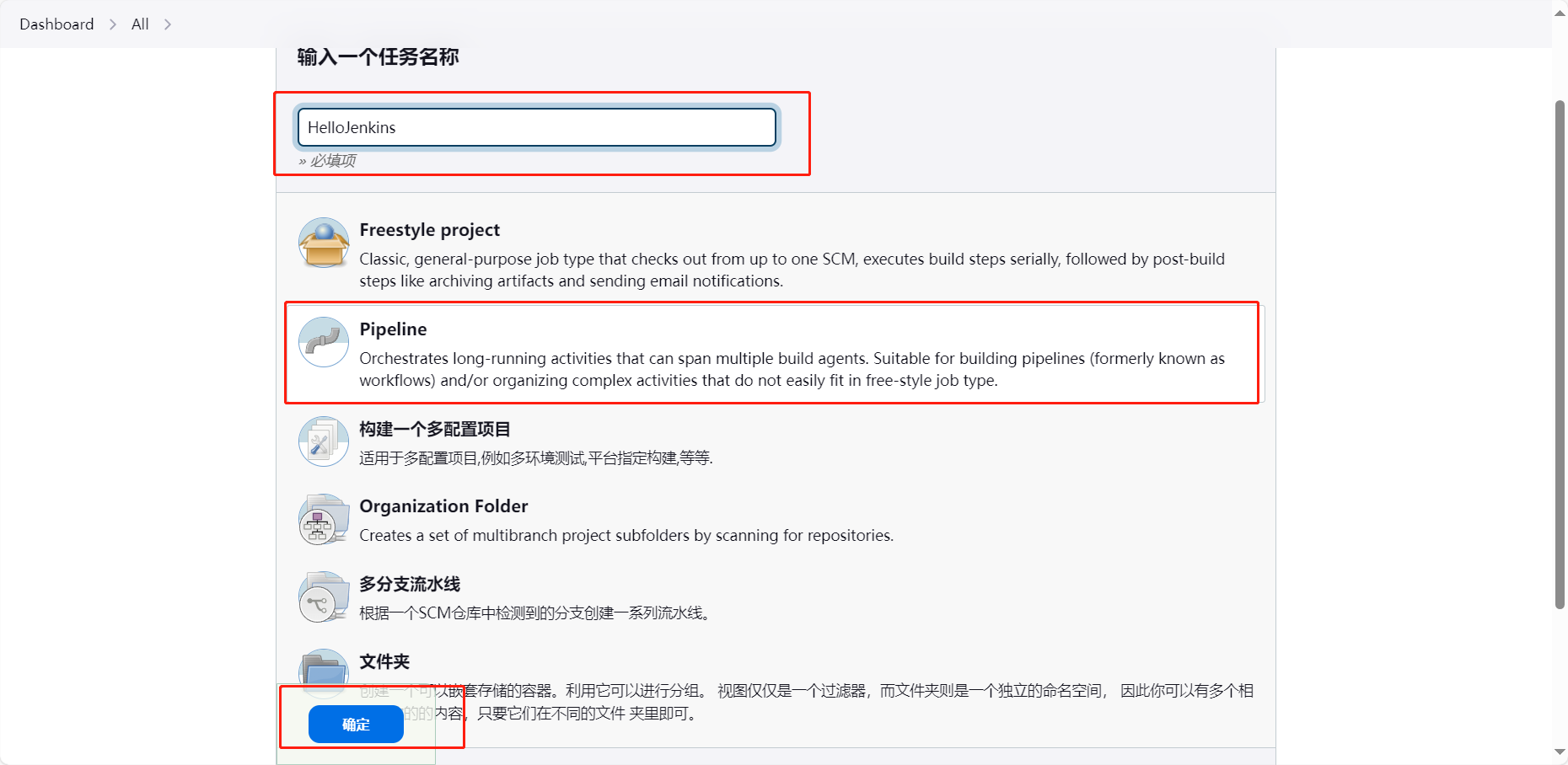
往下拉,选择“Hello World”示例
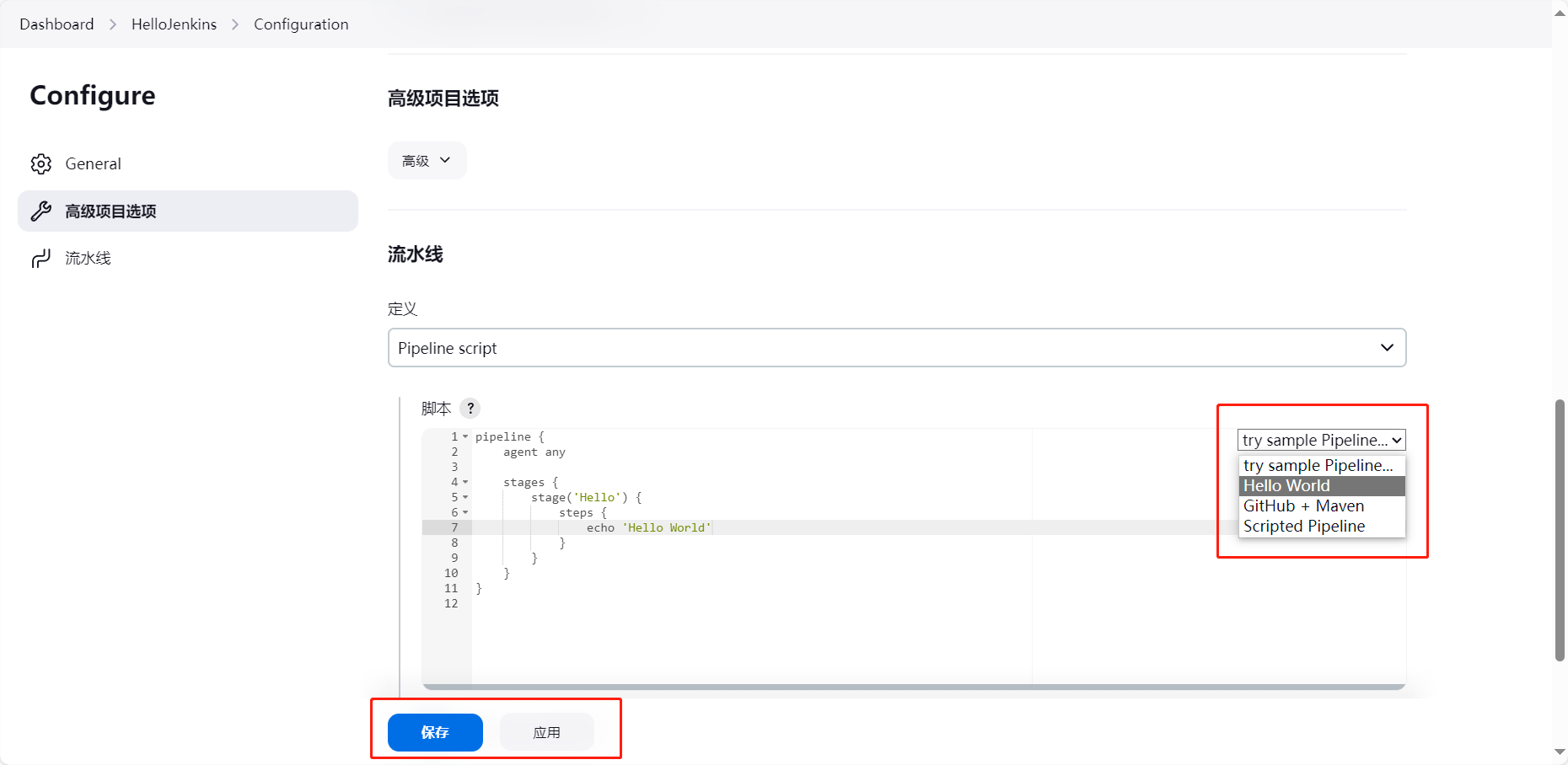
回到“Dashboard”页面,点击图标构建流水线
在“构建历史”处,可以看到构建信息
点击图标,可以查看构建日志等
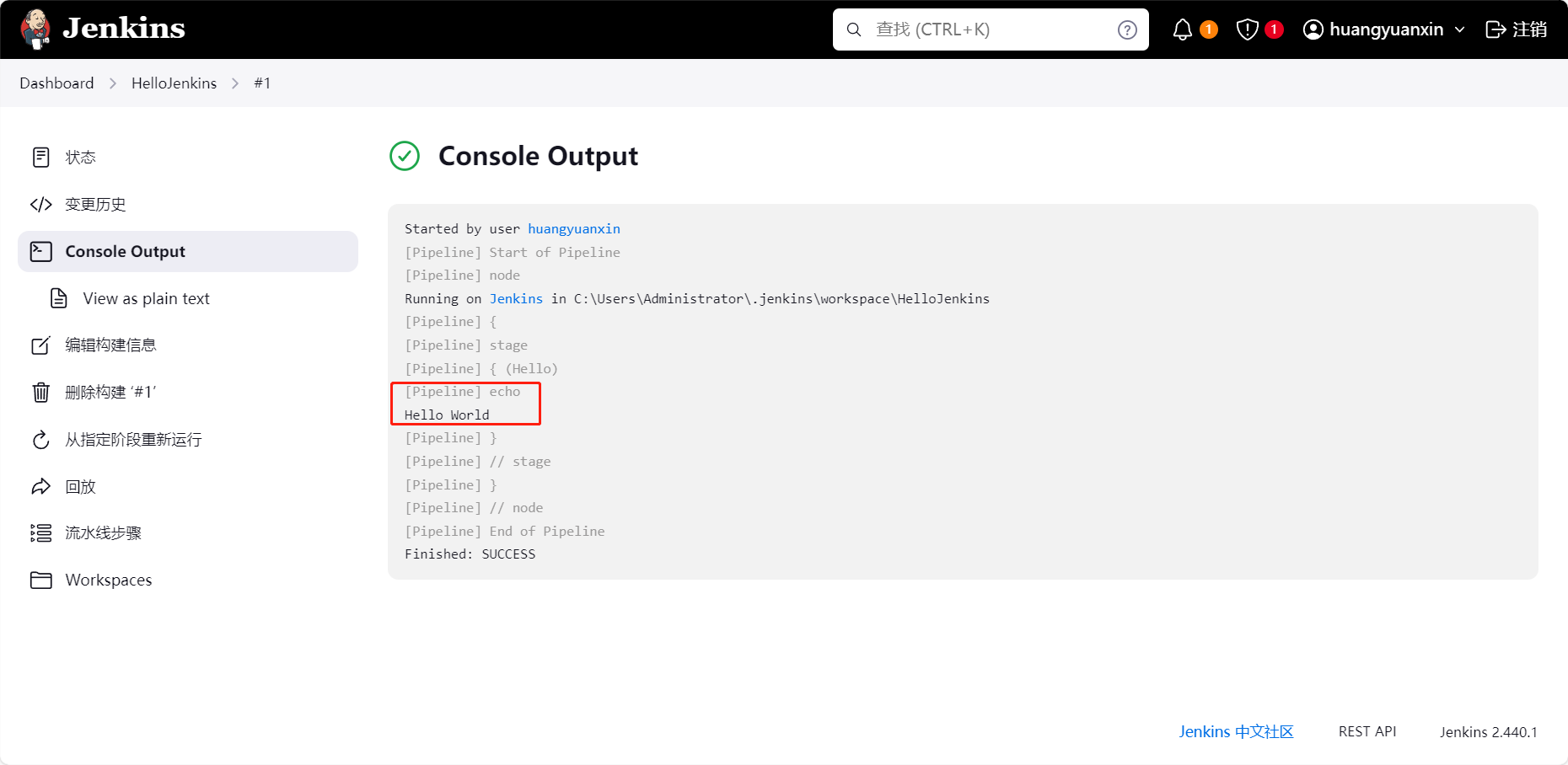
2. 构建步骤
1) Linux命令
141pipeline {2 agent any3 stages {4 stage('Build') {5 steps {6 sh 'echo "Hello World"'7 sh '''8 echo "Multiline shell steps works too"9 ls -lah10 '''11 }12 }13 }14}
2) Bat命令
101pipeline {2 agent any3 stages {4 stage('Build') {5 steps {6 bat 'set'7 }8 }9 }10}
3) 超时与重试
201pipeline {2 agent any3 stages {4 stage('Deploy') {5 steps {6 // 重复执行 flakey-deploy.sh 脚本3次7 retry(3) {8 sh './flakey-deploy.sh'9 }10
11 // 等待 health-check.sh 脚本最长执行3分钟12 // 如果 health-check.sh 脚本在 3 分钟内没有完成,Pipeline 将会标记在“Deploy”阶段失败13 timeout(time: 3, unit: 'MINUTES') {14 sh './health-check.sh'15 }16 }17 }18 }19}20
151pipeline {2 agent any3 stages {4 stage('Deploy') {5 steps {6 // 重试部署任务 5 次,但是总共花费的时间不能超过 3 分钟7 timeout(time: 3, unit: 'MINUTES') {8 retry(5) {9 sh './flakey-deploy.sh'10 }11 }12 }13 }14 }15}
4) 完成时动作
当 Pipeline 运行完成时,你可能需要做一些清理工作或者基于 Pipeline 的运行结果执行不同的操作, 这些操作可以放在 post 部分。
281pipeline {2 agent any3 stages {4 stage('Test') {5 steps {6 sh 'echo "Fail!"; exit 1'7 }8 }9 }10 post {11 always {12 echo 'This will always run'13 }14 success {15 echo 'This will run only if successful'16 }17 failure {18 echo 'This will run only if failed'19 }20 unstable {21 echo 'This will run only if the run was marked as unstable'22 }23 changed {24 echo 'This will run only if the state of the Pipeline has changed'25 echo 'For example, if the Pipeline was previously failing but is now successful'26 }27 }28}
3. 执行环境
agent 指令告诉Jenkins在哪里以及如何执行Pipeline或者Pipeline子集
1) docker方式
121pipeline {2 agent {3 docker { image 'node:7-alpine' }4 }5 stages {6 stage('Test') {7 steps {8 sh 'node --version'9 }10 }11 }12}
4. 环境变量
1) 全局环境变量
2) 阶段环境变量
161pipeline {2 agent any3
4 environment {5 DISABLE_AUTH = 'true'6 DB_ENGINE = 'sqlite'7 }8
9 stages {10 stage('Build') {11 steps {12 sh 'printenv'13 }14 }15 }16}
5. 记录结果
1) 测试结果(junit)
151pipeline {2 agent any3 stages {4 stage('Test') {5 steps {6 sh './gradlew check'7 }8 }9 }10 post {11 always {12 junit 'build/reports/**/*.xml'13 }14 }15}如果存在失败的测试用例,Pipeline 会被标记为 “UNSTABLE”,在网页上用黄色表示, 这不同于使用红色表示的 “FAILED” 失败状态。
2) 构建结果
241pipeline {2 agent any3 stages {4 stage('Build') {5 steps {6 sh './gradlew build'7 }8 }9 stage('Test') {10 steps {11 sh './gradlew check'12 }13 }14 }15
16 post {17 always {18 // 构建结果记录和存储19 // 参数:文件的路径、文件名和 fingerprint20 archiveArtifacts artifacts: 'build/libs/**/*.jar', fingerprint: true21 junit 'build/reports/**/*.xml'22 }23 }24}
6. 发送通知
1) email
71post {2 failure {3 mail to: 'team@example.com',4 subject: "Failed Pipeline: ${currentBuild.fullDisplayName}",5 body: "Something is wrong with ${env.BUILD_URL}"6 }7}
7. 部署
1) 阶段即为部署环境
一个常见的模式是扩展阶段的数量以获取额外的部署环境信息, 如 “staging” 或者 “production”,如下例所示。
111stage('Deploy - Staging') {2 steps {3 sh './deploy staging'4 sh './run-smoke-tests'5 }6}7stage('Deploy - Production') {8 steps {9 sh './deploy production'10 }11}
2) 人工确认
261pipeline {2 agent any3 stages {4 /* "Build" and "Test" stages omitted */5
6 stage('Deploy - Staging') {7 steps {8 sh './deploy staging'9 sh './run-smoke-tests'10 }11 }12
13 // 人工确认14 stage('Sanity check') {15 steps {16 input "Does the staging environment look ok?"17 }18 }19
20 stage('Deploy - Production') {21 steps {22 sh './deploy production'23 }24 }25 }26}
第三节 从SVN检出并使用Maven构建
1. 创建一个Pipeline
2. 配置SVN地址
3. 编写Jenkinsfile并上传
191pipeline {2 agent any3
4 stages {5 stage('Hello') {6 steps {7 echo 'Hello World'8 }9 }10 11 stage('Build') {12 steps {13 bat 'mvn package'14 }15 }16 17 }18}19
4. 执行构建