第04篇_Others
第01章_TDSQL快速入门
第一节 Tdsql(MySql版)简介
1. TDSQL(MySql版)简介
腾讯分布式数据库(Tencent Distributed SQL,TDSQL)是腾讯研发的一款兼容MySQL协议的国产分布式数据库,适用于超大并发、超高性能、超大容量的 OLTP 类场景,提供了弹性扩展、备份、恢复、监控等全套解决方案。
2. 组件架构
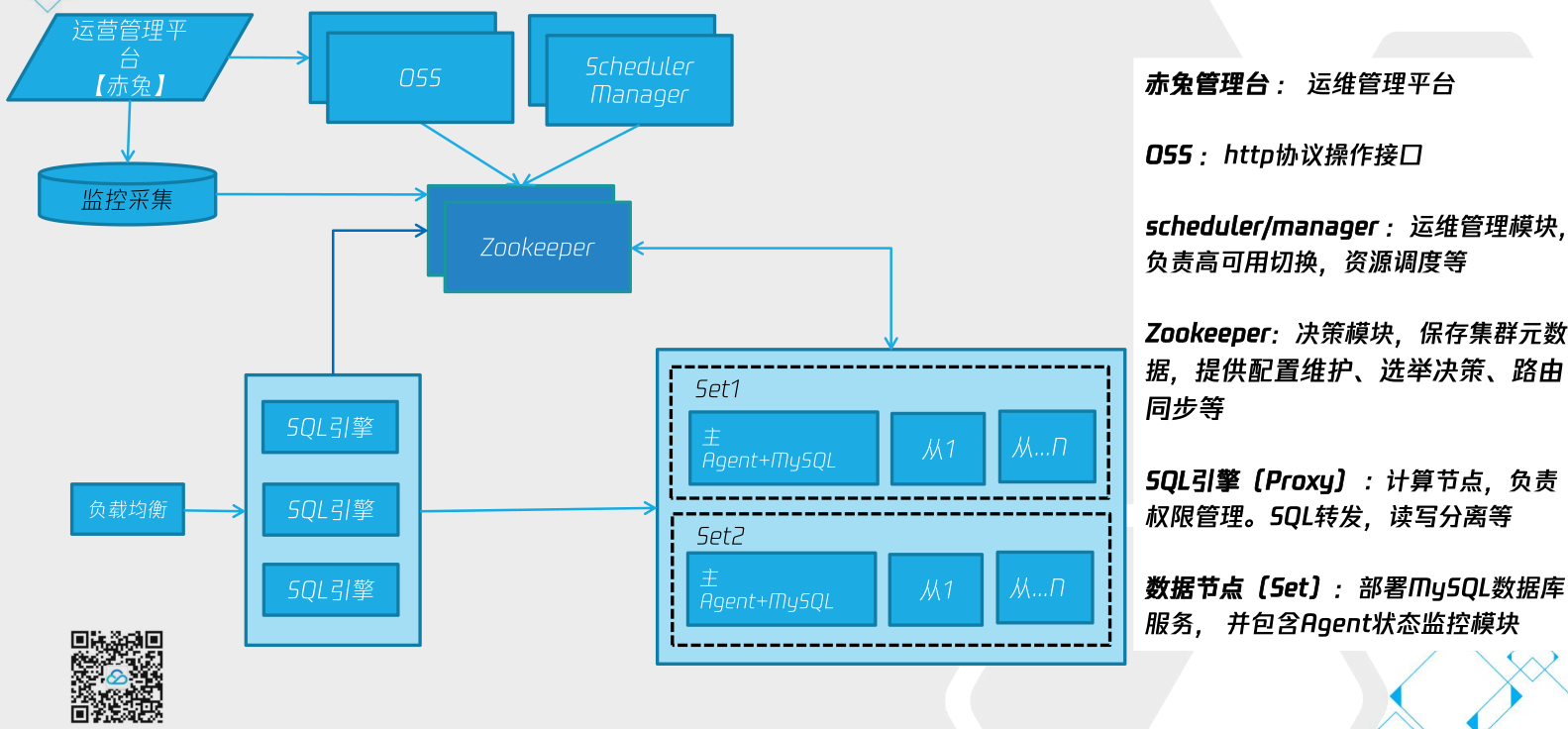
3. 表分类
建表有三种模式,分别是单表、广播表和分表:
1) 单表
单表的数据全部存放在第一个分片(set),常用于存储相对独立、访问量小的业务数据,不支持水平扩容。
x1create table CALL_LBM2(3 BIZ_NO bigint not null default 0,4 USER_CODE bigint not null,5 USER_NAME varchar(128) not null,6 CUACCT_CODE bigint not null,7 TRD_DATE int not null,8 LBM_ID varchar(32) not null,9 LBM_DESC varchar(512) not null,10 CALL_STATUS char(1) not null,11 OCCUR_TIME datetime not null,12 REMARK varchar(128) not null,13 TOPIC_TYPE char(1) not null,14 INT_ORGES varchar(10) not null,15 primary key (BIZ_NO)16);17
注意:
如果单表数据量/访问量过大,会导致第一个分片负载较高
和分表进行联表查询时,通常需要进行跨分片联表查询,执行效率较低
2) 广播表
广播表在每个分片都存储全量数据,使用分布式事务维护多个物理分片间的数据一致性,常用于存储需联合查询、变更量小的业务数据。
91create table PUBLISHER_CFG2(3 PUBLISHER VARCHAR(32) not null,4 TOPIC_GRP VARCHAR(64) not null,5 THREAD_NUM int not null,6 UPD_TIME datetime default CURRENT_TIMESTAMP not null,7 PRIMARY KEY (PUBLISHER, TOPIC_GRP)8) shardkey = noshardkey_allset;9
注意:
如果广播表数据量/变更量过大,所有物理分片负载较高。
方便和分表进行联表查询,与任意表做联表查询都无需跨物理分片联表查询。
3) 分片表
分片表根据shardkey将数据分布到不同的分片,支持Hash、Range、List三种分片算法,常用于存储数据量大、访问量大的业务数据。
211create table USERS2(3 USER_CODE bigint not null,4 USER_ROLES varchar(8) not null,5 USER_NAME varchar(32) not null,6 USER_TYPE char(1) not null,7 INT_ORG int not null default 0,8 ID_TYPE char(2) not null,9 ID_CODE varchar(48) not null,10 UPD_TIME datetime not null default '1900-01-01 01:01:01',11 USER_FNAME varchar(128) not null,12 ID_ISS_AGCY varchar(64) not null,13 ID_EXP_DATE int not null,14 CITIZENSHIP char(3) not null,15 NATIVE_PLACE varchar(32) not null,16 NATIONALITY varchar(32) not null,17 REMARK varchar(128) not null,18 ID_BEG_DATE int not null,19 primary key (USER_CODE)20) shardkey = USER_CODE;21
注意:
TDSQL支持LIST、RANGE、HASH三种类型的一级分片,同时支持支持RANGE、LIST两种格式的二级分区。
Shardkey字段的类型必须为 int/bigint/smallint/char/varchar 之一。
Shardkey字段的值不能为中文,因为Proxy不会转换字符集,所以不同字符集可能会路由到不同的分区。
创建主键和所有唯一索引必须包含shardkey,执行INSERT/REPLACE语句也必须包含shardkey。
不允许更新shardkey字段的值,只能删除后再重新插入。
SELECT 语句如果不带shardkey,需查询所有分片后聚合处理结果,影响执行效率
多个分表联合查询,根据shardkey进行等值关联时,无需跨物理分片联表查询,执行效率较高;无法根据shardkey进行等值关联时,需要进行跨物理分片联表查询,执行效率较低;
4. 应用开发简介
1) 连接
81-- 客户端连接2-- 提示:添加 -c 参数可以使用注释透传功能3mysql -h10.20.80.57 -P3306 -utest -ptest123 -c4
5-- JDBC连接6driverClassName: com.mysql.cj.jdbc.Driver7url: jdbc:mysql://10.203.60.11:15002/shard_kfms?userunicode=true&serverTimezone=Asia/Shanghai&characterEncoding=utf8&connectTimeout=30000&socketTimeout=600000&rewriteBatchedStatements=true&autoReconnect=true8
2) 开发示例
3) 透传SQL
151-- 查询分片名称和数量2/*proxy*/show status3
4-- 透传到指定分片5/*sets:set_1,set_2*/ SELECT * FROM USERS;6
7-- 透传到ShardKey=10对应的分片8/*shardkey:10*/ SELECT * FROM USERS;9
10-- 透传到所有分片11/*sets:allsets*/ SELECT * FROM USERS;12
13-- 计算ShardKey14select murmurHashCodeAndMod('V',partition_num)15
注意:
使用透传进行增删改时,不会使用分布式事务控制,可能导致各分片间数据不一致。
5. 不支持的特性
1) 不支持的大特性
自定义函数,事件,表空间
存储过程、触发器,游标
外键、自建分区、临时表
复合语句,如BEGIN END,LOOP,UNION语句等
暂不支持主备同步相关的SQL语言
2) 不支持的DDL
CREATE TABLE ... SELECT
CREATE TEMPORARY TABLE
ALTER对分表键(shardkey)进行改名,但可以修改类型
2) 不支持的DML
非SELECT的子查询
不带列名的INSERT/REPLACE
不带WHERE条件的UPDATE/DELETE
SELECT INTO OUTFILE/INTO DUMPFILE/INTO var_name
LOAD DATA/XML
SQL中对于变量的引用和操作,比如 SET @c=1, @d=@c+1; SELECT @c, @d
3) 不支持的DCL
ANALYZE/CHECK/CHECKSUM/OPTIMIZE/REPAIR TABLE,需要用透传语法
6. 数据备份与恢复简介
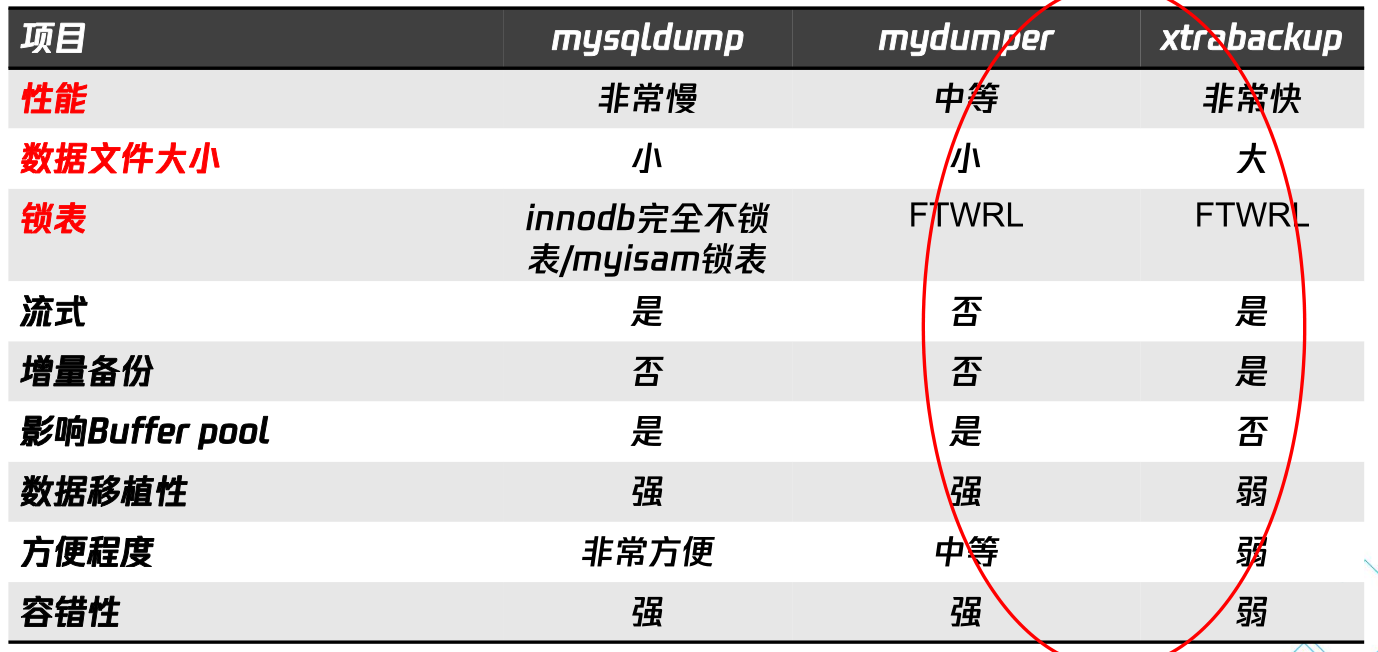
注:
各工具使用方法请参考《MySql学习笔记.md》
7. 查询计划简介
1) 生成执行计划
31-- 仅生成执行计划,不执行2-- 注:在分布式场景下的网关执行计划,会多一列Info,Info列记录了实际发往的set名称和sql信息3explain + sql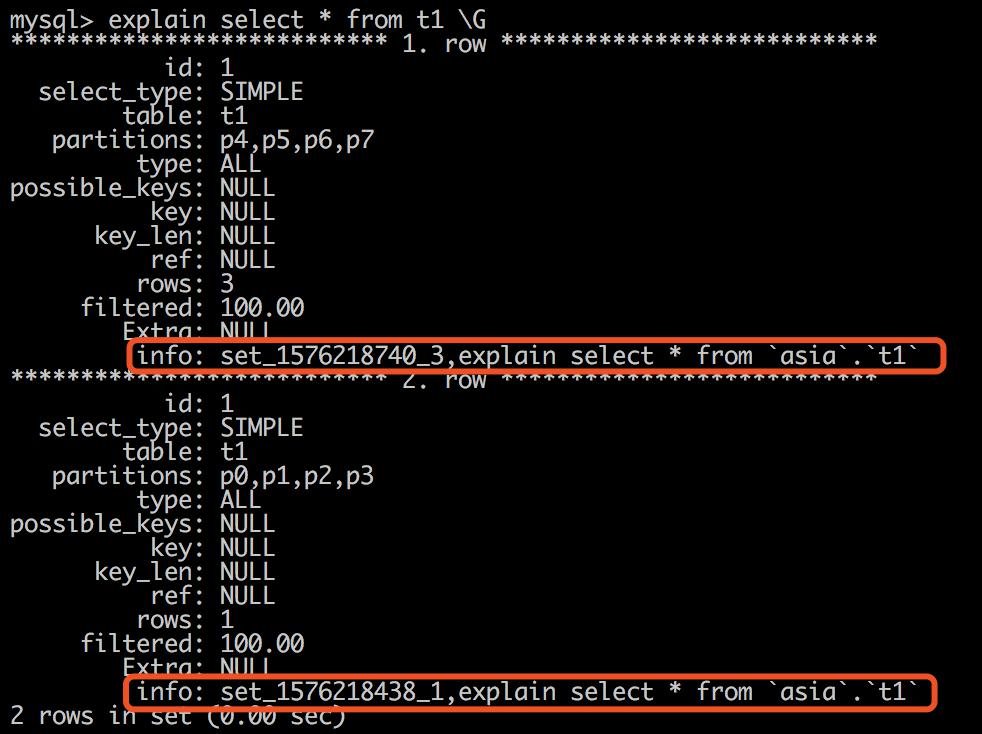
2) 分布式下推
TDSQL(MySql版)仅支持几种特殊场景(如ShardKey等值连接)进行下推,大都场景需根据业务判断是否可以使用透传语法强制下推。
使用强制下推需要满足如下一些条件:
某分片计算时无需依赖其它分片数据。
部分SQL下推后,需在业务层自己做汇总,如:
未分组的COUNT语句也会返回多个结果,需在业务层累加
分页查询前N条,需各分片都查询N条,然后在业务层对查询结果排序,再取前N条。
对于某些极端场景,不能直接下推的,可以采用二阶段执行的方法:
先在各分片计算不需要依赖其它分片的部分,存储结果到临时表。
再次执行SQL,将临时表数据进行二次计算。
第二节 TDSQL(Postgresql版)简介
第02章_OceanBase快速入门
第一节 OceanBase简介
1. OceanBase简介
OceanBase 数据库是由蚂蚁集团和阿里巴巴完全自主研发的金融级分布式关系数据库。
31-- 查看数据库版本2SELECT version(); -- MySql租户3SELECT * FROM v$version; -- Oracle租户
2. 整体架构
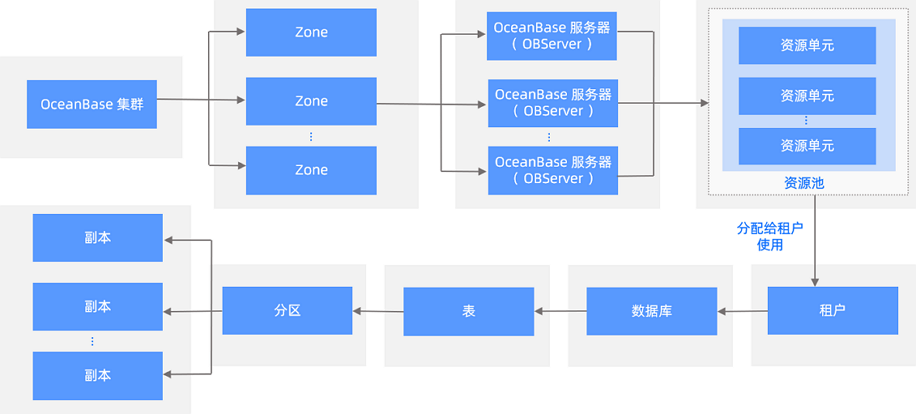
1) 集群
OceanBase 数据库通过 OceanBase 集群来进行管理。
2) 区(Zone)与节点(OBServer)
一个 OceanBase 集群可能存在多个区(Zone),每个区又可能包含多个节点(OBServer),节点的概念类似于TDSQL中的分片,每个分片存储分片表中的某部分数据,所有分片组成全量数据?
区是一个逻辑概念,表示集群内具有相似硬件可用性的一组节点,它在不同的部署模式下代表不同的含义。例如,当整个集群部署在同一个数据中心(IDC)内的时候,一个区的节点可以属于同一个机架,同一个交换机等。当集群分布在多个数据中心的时候,每个区可以对应于一个数据中心。每个区具有 IDC 和地域(Region)两个属性,描述该区所在的 IDC 及 IDC 所属的地域。一般地,地域指 IDC 所在的城市。区的 IDC 和 Region 属性需要反映部署时候的实际情况,以便集群内的自动容灾处理和优化策略能更好地工作。
3) 资源池
一般情况下,各个 Zone 内的机器配置与数量保持一致,多台 OBServer 作为资源组成各个业务所需的资源池,资源池包括指定规格的 CPU、内存、存储等。管理员可以根据业务情况,将资源再划分成不同大小的资源池分配给租户使用。
4) 租户
租户是一个逻辑概念,在 OceanBase 数据库中,租户是资源分配的单位,是数据库对象管理和资源管理的基础。
租户在一定程度上相当于传统数据库的"实例",租户之间是完全隔离的(内存是物理隔离、CPU 是逻辑隔离)。
在数据安全方面,OceanBase 数据库不允许跨租户的数据访问,以避免用户的数据资产被其他租户窃取。
在资源使用方面,OceanBase 数据库表现为租户"独占"其资源配额。
总体上来说,租户(tenant)既是各类数据库对象的容器,又是资源(CPU、Memory、IO 等)的容器。
5) 数据库
租户拥有资源池后,可以创建数据库、表、分区等。
6) 副本
OceanBase 数据库参考传统数据库分区表的概念,把一张表格的数据划分成不同的分区(Partition)。在分布式环境下,为保证数据读写服务的高可用,OceanBase 数据库会把同一个分区的数据拷贝到多个机器。
不同机器同一个分区的数据拷贝称为副本(Replica)。同一分区的多个副本使用 Paxos 一致性协议保证副本的强一致,每个分区和它的副本构成一个独立的 Paxos 组,其中一个分区为主副本(Leader),其它分区为从副本(Follower)。
主副本具备强一致性读和写能力,从副本具备弱一致性读能力。
3. 兼容性
与Oracle的兼容性:https://www.oceanbase.com/docs/enterprise-oceanbase-database-cn-10000000000355001
与MySql的兼容性:https://www.oceanbase.com/docs/enterprise-oceanbase-database-cn-10000000000354623
4. 管理工具
| 工具 | 工具介绍 |
|---|---|
| OBClient | 连接数据库的客户端工具。 可同时兼容访问 OceanBase 数据库的 MySQL 以及 Oracle 租户。 |
| MySQL 客户端 | 连接数据库的客户端工具。 仅支持访问 OceanBase 数据库的 MySQL 租户。 |
| OceanBase 云平台 | 数据库的管理平台。 可同时兼容访问 OceanBase 数据库的 MySQL 以及 Oracle 租户。 不仅提供对 OceanBase 集群和租户等组件的全生命周期管理服务,同时也对 OceanBase 数据库相关的资源(主机、网络和软件包等)提供管理服务,让您能够更加高效地管理 OceanBase 集群,降低企业的 IT 运维成本。 |
| OceanBase 开发者中心 | 企业级数据库开发平台。 支持连接 OceanBase 数据库的 MySQL 租户和 Oracle 租户,同时为数据库开发者提供了数据库日常开发操作、WebSQL、SQL 诊断、会话管理和数据导入导出等功能。 |
1) ObClient
161-- 通过 OBProxy 连接的方式2obclient -h10.10.10.1 -uusername@obtenant#obdemo -P2883 -ppassword -c -A oceanbase -- 用户名@租户名#集群名3obclient -h10.10.10.1 -uobdemo:obtenant:username -P2883 -ppassword -c -A oceanbase -- 集群名:租户名:用户名4
5-- 通过直连数据库方式6obclient -h10.10.10.1 -uusername@obtenant -P2881 -ppassword -c -A oceanbase -- 用户名@租户名7
8-- 退出9exit -- CTRL+D10
11-- 注意事项121. 如果连接语句中不带 -c 项,则连接至租户后 Hint 无法生效。132. 如果连接语句中不带 -D[数据库名] 项,则默认数据库名与用户名一致。143. 普通租户通过直连方式连接时,需要确保该租户的资源分布在该 OBServer上,15 如果该租户的资源未分布在该 OBServer 上,则无法通过直连该 OBServer 连接到该租户16
2) MySQL 客户端
131-- 通过 OBProxy 连接的方式2$mysql -h10.10.10.1 -uusername@obmysql#obdemo -P2883 -ppassword -c -A oceanbase3$mysql -h10.10.10.1 -uobdemo:obmysql:username -P2883 -ppassword -c -A oceanbase4
5-- 通过直连数据库方式6$mysql -h10.10.10.1 -uusername@obmysql -P2881 -ppassword -c -A oceanbase7
8-- 退出9exit -- CTRL+D10
11-- 注意事项121. 支持 MySQL 客户端 V5.5、V5.6 和 V5.7 版本。132. 如果连接语句中不带 -c 项,则连接至 MySQL 租户后 HINT 无法生效。
5. 使用限制
标识符长度:租户名至少支持63字节,用户名、表名、索引名、视图名、分区名至少支持64字节,列名等支持更大的长度。
最大连接数限制:单个ODP(OceanBase Database Proxy)的连接数最大8192,由 client_max_connections 参数控制。
分区副本数限制:每个 OBServer 节点的分区副本数最大500000 个。
单个表的限制:最大支持4096 列以及128 个索引,主键长度最大16K。CHAR最大256/2000字节,VARCHAR最大262144/32767字节。
6. 高可用方案简介
1) 同城两机房"主-备"部署
每个机房都部署一个 OceanBase 集群,一个为主集群一个为备集群;每个集群有自己单独的 Paxos group,多副本一致性。
"集群间"通过 Redo-log 做数据同步,形式上类似传统数据库"主从复制"模式;有"异步同步"和"强同步"两种数据同步模式,类似 Oracle Data Guard 中的"最大性能"和"最大保护"两种模式。
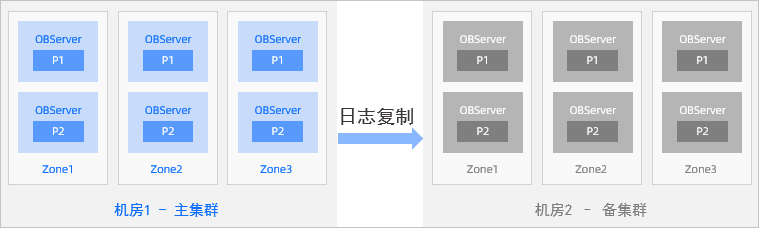
2) 两地三中心"主-备"部署
主城市与备城市组成一个 5 副本的集群。任何 IDC 的故障,最多损失 2 份副本,剩余的3份副本依然满足多数派。
备用城市建设一个独立的 3 副本集群,做为一个备集群,从主集群"异步同步"或者"强同步"到备集群。
一旦主城市遭遇灾难,备城市可以接管业务。

7. JDBC连接
1) JDBC驱动
在 MySQL 模式下,用户可以使用 OceanBase 自研的数据库驱动,或者直接使用 MySQL 官方提供的 Connector 。
在 Oracle 模式下,需要使用 OceanBase 自研的数据库驱动 oceanbase-client 来使用 OceanBase 数据库。
2) oceanbase-client
221String url = "jdbc:oceanbase://xxx.xxx.xxx.xxx:2883/SYS?useUnicode=true&characterEncoding=utf-8"; //IP地址:OBProxy端口号/数据库名2 String username = "SYS@test1#obtest"; //用户名@租户名#集群名称3 String password = "****"; //密码4 Connection conn = null; 5 try { 6 Class.forName("com.oceanbase.jdbc.Driver"); //驱动类名7 conn = DriverManager.getConnection(url, username, password);8 PreparedStatement ps = conn.prepareStatement("select to_char(sysdate,'yyyy-MM-dd HH24:mi:ss') from dual;");9 ResultSet rs = ps.executeQuery();10 rs.next();11 System.out.println("sysdate is:" + rs.getString(1));12 rs.close();13 ps.close();14 } catch (Exception e) {15 e.printStackTrace();16 } finally {17 if (null != conn) {18 conn.close();19 }20 }21
22
3) mysql-connector-Java
211String url = "jdbc:mysql://xxx.xxx.xxx.xxx:2883/hr?useUnicode=true&characterEncoding=utf-8"; //IP地址:OBProxy端口号/数据库名2String username = "root@test2#obtest"; //用户名@租户名#集群名称3String password = "****"; //密码4Connection conn = null;5try {6 Class.forName("com.mysql.jdbc.Driver"); //驱动类名7 conn = DriverManager.getConnection(url, username, password);8 PreparedStatement ps = conn.prepareStatement("select date_format(now(),'%Y-%m-%d %H:%i:%s');");9 ResultSet rs = ps.executeQuery();10 rs.next();11 System.out.println("sysdate is:" + rs.getString(1));12 rs.close();13 ps.close();14} catch (Exception e) {15 e.printStackTrace();16} finally {17 if (null != conn) {18 conn.close();19 }20}21
4) 连接参数
| 参数 | 说明 | 推荐值 |
|---|---|---|
| socketTimeout | 网络套接字操作的超时时间,单位为毫秒。默认值为 0,表示禁用超时。 | 需要根据业务实际情况设置。 |
| connectTimeout | 链接建立超时时间,如果不设置默认是 0,使用 OS 默认超时时间。 | 500 ms |
5) Druid 连接池配置
261<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">2 <property name="driverClassName" value="com.mysql.jdbc.Driver" />3 <!-- 基本属性 URL、user、password -->4 <property name="url" value="jdbc:mysql://ip:port/db?socketTimeout=30000&connectTimeout=3000" />5 <property name="username" value="{user}" />6 <property name="password" value="{****}" />7 <!-- 配置初始化大小、最小、最大 -->8 <property name="maxActive" value="4" /> //initialSize/minIdle/maxActive视业务规模设置9 <property name="initialSize" value="2" />10 <property name="minIdle" value="2" />11 <!-- 获取连接等待超时的时间,单位是毫秒 -->12 <property name="maxWait" value="1000" />13 <!-- 间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->14 <property name="timeBetweenEvictionRunsMillis" value="60000" />15 <!-- 一个连接在池中最小空闲的时间,单位是毫秒-->16 <property name="minEvictableIdleTimeMillis" value="300000" />17 <!-- 检测连接是否可用的 SQL -->18 <property name="validationQuery" value="SELECT foo FROM bar" /> //找真实的、记录少的业务表用作查询探测语句19 <!-- 是否开启空闲连接检查 -->20 <property name="testWhileIdle" value="true" />21 <!-- 是否在获取连接前检查连接状态 -->22 <property name="testOnBorrow" value="false" />23 <!-- 是否在归还连接时检查连接状态 -->24 <property name="testOnReturn" value="false" />25</bean>26
8. 关于OB数据库的分布式
1) 分区表
当一个表很大的时候,可以水平拆分为若干个分区(Partition),每个分区包含表的若干行记录,这种表叫做分区表。根据行数据到分区的映射关系不同,分为 hash 分区、range 分区(按范围)、key 分区等,这与传统数据库的概念基本类似。
不同的是,如果有多个ObServer,则会将这些分区在ObServer之间均匀分布,并计算负载进行调整。
每个表都可能有自己所属的表格组(TableGroup),TableGroup 是一个逻辑概念,它和物理数据文件没有关联关系,Table Group 只影响表分区的调度方法。对于包含分区表的 TableGroup,它由若干个 Partition Group 组成,每个分区表中下标相同的一组分区为 Partition Group。属于同一个 Partition Group 的所有 Partition,系统会通过自动调度使它们位于同一台 OBServer 服务器上,且这些分区副本的 leader 也位于一台 OBServer 上。
注意1:同一个表格组的所有表必须拥有相同的 Locality(副本类型、个数及位置),相同的 Primary Zone(leader 位置及其优先级),以及相同的分区方式。
注意2:Partition Group 是负载均衡和leader切换等操作的最小执行单元。
此外,系统在调度时,会把同一个TableGroup 的不同 Partition Group 尽量在多个可用的机器间分散来开,以支持水平自动扩展。用户无法控制一个分区表的多个分区间是否聚集在一起。相反,RS 会让他们尽可能分散开。
总结:要想实现分布式快速关联查询,则必须属于同一Partition Group,要属于同一分区组,则必须属于同一TableGroup,要属于同一表组,则必须满足上述表组三要素相同。
2) 创建分区表
121CREATE TABLE ware(2w_id int3, w_ytd number(12,2)4, w_tax number(4,4)5, w_name varchar(10)6, w_street_1 varchar(20)7, w_street_2 varchar(20)8, w_city varchar(20)9, w_state char(2)10, w_zip char(9)11, primary key(w_id)12) PARTITION by hash(w_id) partitions 60;第03章_GlodenDB快速入门
第一节 GlodenDB简介
1. GlodenDB简介
GoldenDB 是中兴通讯的关系型分布式数据库产品,满足 OLTP 类应用,同时兼顾 OLAP 数据处理要求。
2. 整体架构
GoldenDB整体架构如下图所示包括:
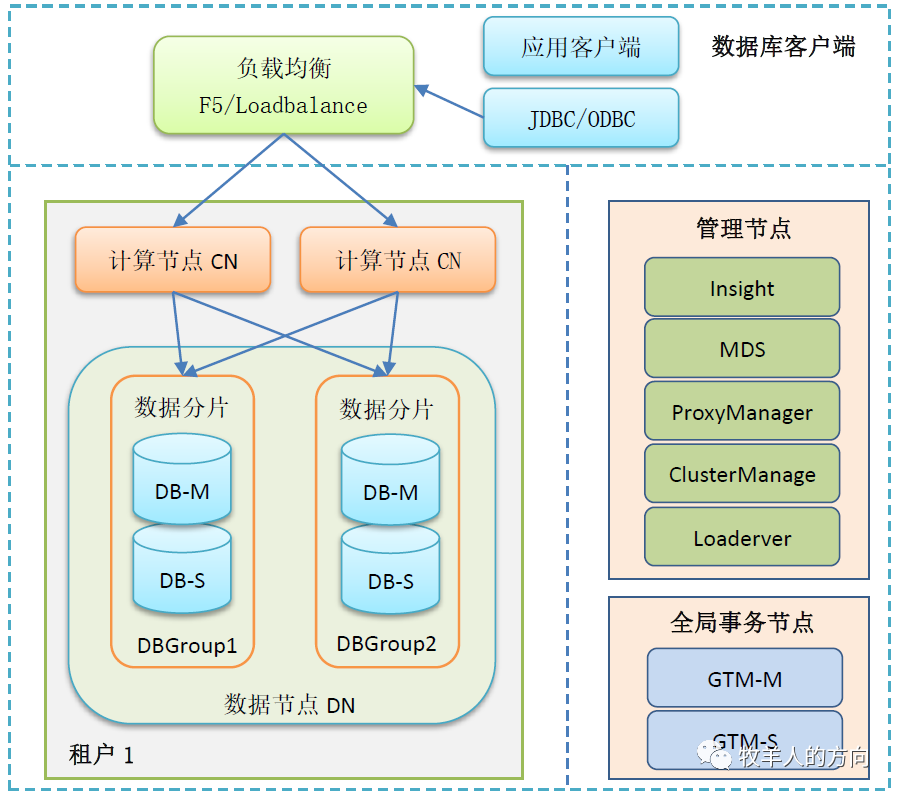
计算节点(CN)
计算节点主要负责分布式优化、执行具体的分布式计划、分布式事务控制、存储节点负载均衡、用户认证与鉴权等任务。
数据节点(DN)
数据节点用于实际存储数据、执行原子Sql操作和本地事务控制。
每个数据节点对应一个MySQL节点,多个数据节点组成一个安全组(Group)。在安全组中,数据节点按照一主多备进行快同步数据复制。
多个Group组成一个数据库集群,数据在Group之间按照用户设计的策略进行水平分布。
全局事务节点(GTM)
全局事务协调中心,用于协助计算节点进行分布式事务管理,主要包括生成、释放全局事务ID(GTID)、维护活跃事务以及当前活跃GTIDs的快照。在GoldenDB中,只有跨分片的写操作才会申请GTID,其它读查询操作和单分片的写操作都不会申请GTID。
管理节点
管理节点包含四个主要的功能模块:
41- MetaDataServer:主要功能是管理分布式数据库的元数据信息,对外提供操作接口;持久化数据以及进行相应的任务管理工作。2- ProxyManager(PM):主要功能包括管理计算节点,管理连接实例,收集计算节点状态、统计告警信息和对计算节点的异常进行处理。3- ClusterManager(CM): 在分布式数据库系统中主要用于存储节点安全组的管理,协同计算节点控制对数据库的访问。4- LoadServer:主要功能是在存储节点间批量导入导出数据。
OMM(Operations, Maintenance & Monitoring Manager)
OMM是整个分布式数据库系统中用于进行维护工作的管理平台,负责所有组件的管理,主要功能包括用户和权限管理、统计监控、元数据管理、DBProxy管理、Cluster管理、操作日志查询、资源管理、FAQ管理、OMM系统配置、数据库备份管理、数据重分布等功能。
3. 连接方式
应用客户端可以通过JDBC或者ODBC直接连接到计算节点,也可以经过负载均衡F5或loadbalance或LVS的方式连接到计算节点,达到流量均衡的目的。