第03篇_Gauss
第01章_Gauss概述
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/AboutopenGauss/%E5%85%B3%E4%BA%8EopenGauss.html
第一节 Gauss简介
1. openGauss和GaussDB
openGauss是华为基于PostgreSQL代码研发的分布式关系型数据库,采用木兰宽松许可证V2完全开源 ,而GaussDB在OpenGauss基础上添加了额外的专有功能和技术支持,包括更加强大的性能优化、更高的安全性和可靠性等,适用于要求更高的企业级应用场景。
第二节 安装部署
1. 安装须知
1) 运行环境
支持ARM服务器和基于x86_64的通用PC服务器。
支持openEuler 20.03LTS、麒麟V10、CentOS 7.6等操作系统。
2) 硬件要求
CPU:开发测试环境2~4核,功能调试最小1×8核2.0GHz,性能测试和商业部署时,建议1×16核2.0GHz。
内存:开发测试环境4~8GB,功能调试建议32GB以上,性能测试和商业部署时,单实例部署建议128GB以上,在复杂查询较多的场景应适当提高内存。
硬盘:建议系统盘配置为Raid1,数据盘配置为Raid5,同时设置Disk Cache Policy为Disabled。
3) 技术指标
单表最大32TB,最大行数为2的32次方,单行数据或单个字段最大1GB,数据库总容量受限于操作系统与硬件。
数据库名及其它对象名长度最长63个字符。
最大支持10000个连接。
最大支持256个分片。
2. 部署方案
支持集中式模式或分布式模式,支持单机部署、主备模式、同城双活、两地三中心(异地灾备)、资源池化架构等部署方案。
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DatabaseAdministrationGuide/openGauss常见主备部署方案简介.html
3. 安装步骤
1) 单机服务器安装
详细安装步骤可查阅官方文档,摘选单节点服务器安装重要步骤如下:
621-- 0. 修改操作系统配置(root用户)2-- https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/InstallationGuide/%E5%87%86%E5%A4%87%E8%BD%AF%E7%A1%AC%E4%BB%B6%E5%AE%89%E8%A3%85%E7%8E%AF%E5%A2%83.html3-- 关闭操作系统防火墙(目前仅支持在防火墙关闭的状态下进行安装)4systemctl disable firewalld.service5systemctl stop firewalld.service6vim /etc/selinux/config7SELINUX=disabled8reboot9systemctl status firewalld10-- 设置字符集参数11vim /etc/profile12export LANG=XXX13-- 设置时区和时间(先使用date命令确认时区是否已经一致)14cp /usr/share/zoneinfo/$地区/$时区 /etc/localtime15date -s "Sat Sep 27 16:00:07 CST 2020"16-- 关闭swap交换内存(可选)17-- 关闭RemoveIPC(待定)18-- 关闭HISTORY记录(待定)19
20-- 1. 下载安装包21https://opengauss.org/zh/download/22
23-- 2. 安装软件依赖(具体版本要求见官方文档)24libaio-devel、flex、bison、ncurses-devel、glibc-devel、patch、redhat-lsb-core、readline-devel等25
26-- 3. 创建用户组和用户27groupadd dbgroup28useradd -g dbgroup omm29passwd omm30
31-- 6. 解压安装包(以omm用户登录,/opt/software/openGauss为建议安装目录)32tar -jxf openGauss-x.x.x-操作系统-64bit.tar.bz2 -C /opt/software/openGauss33
34-- 7. 执行安装脚本(下面xxxx为初始化数据库密码)35cd /opt/software/openGauss/simpleInstall36sh install.sh -w xxxx 37
38-- 8. 检查是否安装完成39ps ux | grep gaussdb40gs_ctl query -D /opt/software/openGauss/data/single_node41
42-- ps命令输出参考:43omm 24209 11.9 1.0 1852000 355816 pts/0 Sl 01:54 0:33 /opt/software/openGauss/bin/gaussdb -D /opt/software/openGauss/single_node44omm 20377 0.0 0.0 119880 1216 pts/0 S+ 15:37 0:00 grep --color=auto gaussdb45
46-- gs_ctl命令输出参考:47gs_ctl query ,datadir is /opt/software/openGauss/data/single_node48HA state:49 local_role : Normal50 static_connections : 051 db_state : Normal52 detail_information : Normal53
54Senders info:55 No information56
57 Receiver info:58No information 59
60-- 9. 配置服务端远程连接61https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/GettingStarted/%E9%85%8D%E7%BD%AE%E6%9C%8D%E5%8A%A1%E7%AB%AF%E8%BF%9C%E7%A8%8B%E8%BF%9E%E6%8E%A5.html62
注:
数据库安装完成后,默认生成名称为
postgres的数据库。通过脚本安装方式,在单台物理机只允许部署一个数据库系统,如需在单台物理机部署多个(不推荐),则需要通过命令行安装。
商业部署环境可联系华为工程师安装!
2) 其它安装
RPM安装(openEuler 22.03 LTS):https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/InstallationGuide/RPM%E5%AE%89%E8%A3%85.html
3) 卸载
4. 数据库启停
211-- 启动/关闭数据库2gs_om -t start3gs_om -t stop4
5-- 查询openGauss状态6-- https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DatabaseOMGuide7-- /%E6%9F%A5%E7%9C%8B%E7%8A%B6%E6%80%81.html8gs_om -t status --detail 9[ Cluster State ] 10 11cluster_state : Normal 12redistributing : No 13current_az : AZ_ALL 14 15[ Datanode State ] 16node node_ip port instance state 17---------------------------------------------------------------------------------------------------------------- 181 pekpopgsci00235 10.244.62.204 5432 6001 /opt/gaussdb/cluster/data/dn1 P Primary Normal 192 pekpopgsci00238 10.244.61.81 5432 6002 /opt/gaussdb/cluster/data/dn1 S Standby Normal20
21
5. 例行维护
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DatabaseOMGuide/例行维护.html
251-- 查询数据库版本2SELECT version();3
4-- 查询数据库容量5SELECT pg_table_size('table_name');6SELECT pg_database_size('database_name');7
8-- 实例状态检查9gs_check -i CheckClusterState10gs_check -e inspect11
12-- 数据库性能检查13gs_checkperf -i pmk -U omm14Cluster statistics information:15 Host CPU busy time ratio : 1.43 %16 MPPDB CPU time % in busy time : 1.88 %17 Shared Buffer Hit ratio : 99.96 %18 In-memory sort ratio : 100.00 %19 Physical Reads : 420 Physical Writes : 2521 DB size : 70 MB22 Total Physical writes : 2523 Active SQL count : 224 Session count : 325
第三节 客户端
1. 命令行客户端-gsql
1) Linux用户连接
在数据库主节点机器上,可以直接使用Linux用户连接:
81-- Linux用户连接2-- 需以omm用户登录数据库主节点,其中postgres为连接的数据库,8000为数据库主节点的端口号3gsql -d postgres -p 80004
5-- 也可使用下面格式进行连接6gsql postgres://omm:Gauss_234@127.0.0.1:8000/postgres -r 7gsql -d "host=127.0.0.1 port=8000 dbname=postgres user=omm password=Gauss_234"8
注意:
管理员用户omm登录连接时,命令提示符显示
DBNAME=#,如果为普通用户则显示DBNAME=>。客户端连接数据库后,如果空闲时间超过session_timeout,则会自动断开连接,可设置session_timeout为0来关闭超时设置。
2) 数据库用户连接
在其它机器上,可通过数据库用户进行连接,首先需安装gsql工具:
151-- 1. 上传和解压gsql工具包2mkdir /opt/software/tools3cd /opt/software/tools4tar -zxvf openGauss-x.x.x-openEuler-64bit-Libpq.tar.gz5
6-- 2. 拷贝数据库主节点的bin目录7-- 其中/opt/huawei/install/app为clusterconfig.xml文件中配置的{gaussdbAppPath}路径,10.10.0.30为客户端主机ip8scp -r /opt/huawei/install/app/bin root@10.10.0.30:/opt/software9
10-- 3. 配置环境变量11vi ~/.bashrc12export PATH=/opt/software/bin:$PATH13export LD_LIBRARY_PATH=/opt/software/lib:$LD_LIBRARY_PATH14source ~/.bashrc15
安装好gsql工具后,远程连接命令如下:
41-- 远程连接数据库2-- 其中10.10.0.11为数据库主节点ip,jack为数据库用户名,Test@123为用户密码3gsql -d postgres -h 10.10.0.11 -U jack -p 8000 -W Test@1234
注意:
客户端机器与openGauss不在同一网段时,-h指定的IP地址应为Manager界面上所设的coo.cooListenIp2(应用访问IP)的取值。
禁止使用omm用户进行远程连接数据库。
3) 常用操作
221-- 查看已经存在的数据库2openGauss=# \l3
4-- 进入已存在数据库5openGauss=# \c db_tpcc6
7-- 首次登录建议修改密码8ALTER ROLE omm IDENTIFIED BY '$$$$$$$$' REPLACE 'XXXXXXXX';9
10-- 设置gsql变量11-v=var1=xxx12
13-- 使用gsql执行脚本14gsql -d postgres -p 21013 -f /home/user/sql.txt15gsql -h ${DB_IP} -p ${DB_PORT} -d${DB_NAME} -U${DB_USER} -W${DB_PASSWORD} -f "create_tables.sql" >/dev/null 2>./log/create_tables.log16
17-- 使用gsql执行SQL语句18gsql -d postgres -p 21013 -c="select * from xxx"19
20-- 退出21openGauss=# \q22
2. 图形界面客户端-TPDSS
OLTP Development Assistant(简称TPDSS)是OLTP数据库开发助手,帮助数据库开发人员便捷地构建应用程序,以图形化界面形式提供数据库关键特性,展示数据库的主要功能,简化数据库开发和应用构建任务。
3. 应用程序客户端
1) ODBC
详情见:
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/GettingStarted/ODBC.html
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DeveloperGuide/基于ODBC开发.html
提示:
openGauss也提供了专门的C应用程序接口libpq。
2) JDBC
JDBC驱动:可以在linux服务器端源代码目录下执行build.sh,获得驱动jar包postgresql.jar;也可从发布包中获取, 包名为
openGauss-xxxx-操作系统版本号-64bit-Jdbc.tar.gz,两种jar包功能一致,仅仅是为了解决和PostgreSQL之间的JDBC驱动包名冲突。上述两个openGauss JDBC驱动包,相比于PG原版驱动,主要做了以下特性的增强:
支持SHA256加密方式登录。
支持对接实现sf4j接口的第三方日志框架。
支持容灾切换。
JDBC配置:驱动名为
org.opengauss.Driver或org.postgresql.Driver,url前缀为jdbc:opengauss或jdbc:postgresql。可参考示例 不同场景下连接数据库参数配置 (osinfra.cn)和示例 Jdbc主备集群负载均衡 (osinfra.cn)
容灾场景:jdbc:postgresql://node1,node2,node3,node4,node5,node6/database?priorityServers=3
负载均衡场景:jdbc:postgresql://node1,node2,node3/database?loadBalanceHosts=true
日志诊断场景:jdbc:postgresql://node1/database?loggerLevel=trace&loggerFile=jdbc.log
预编译SQL:jdbc:postgresql://node1/database?prepareThreshold=5
优化客户端内存:jdbc:postgresql://node1/database?defaultRowFetchSize=50000
批量插入:jdbc:postgresql://node1/database?batchMode=true
连接参数:第三方工具通过JDBC连接openGauss时,JDBC向openGauss发起连接请求,会默认添加以下配置参数:
191// ConnectionFactoryImpl2params = {3{ "user", user },4{ "database", database },5{ "client_encoding", "UTF8" },6{ "DateStyle", "ISO" },7{ "extra_float_digits", "2" },8{ "TimeZone", createPostgresTimeZone() },9};1011// 其它可选的连接参数12// https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DeveloperGuide/%E8%BF%9E%E6%8E%A5%E6%95%B0%E6%8D%AE%E5%BA%93_JDBC.html13// https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DeveloperGuide/JDBC%E5%B8%B8%E7%94%A8%E5%8F%82%E6%95%B0%E5%8F%82%E8%80%83.html14loggerLevel:目前支持 OFF、INFO(默认)、DEBUG、TRACE 这4种级别。15loggerFile:Logger输出的文件名,默认为客户端运行程序目录。16fetchsize:执行查询后每次提取的数据行数,默认为0,表示一次性提取所有数据。17应用:设置为合适的值,可用于优化客户端内存占用,但是会增加网络交互开销。18注意:该功能依赖游标实现,由于游标在事务内有效,因此必须关闭autocommit才能使用。19
注意:
需在pg_hba.conf文件(安装目录datanode文件夹中)中添加客户端地址,如:
host all all 127.0.0.1/32 sha256。若使用数据库连接池,则必须在归还连接前重置GUC参数和删除临时表,否则可能会产生因为历史会话信息导致的对象冲突。
更多JDBC示例请参考:https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/GettingStarted/Java.html。
3) Psycopg
Psycopg是一种用于执行SQL语句的PythonAPI,可以为PostgreSQL、openGauss数据库提供统一访问接口,应用程序可基于它进行数据操作。Psycopg2对libpq进行封装,部分代码使用C语言实现,既高效又安全。
详细使用步骤请参考:https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/GettingStarted/Python.html。
第四节 体系结构
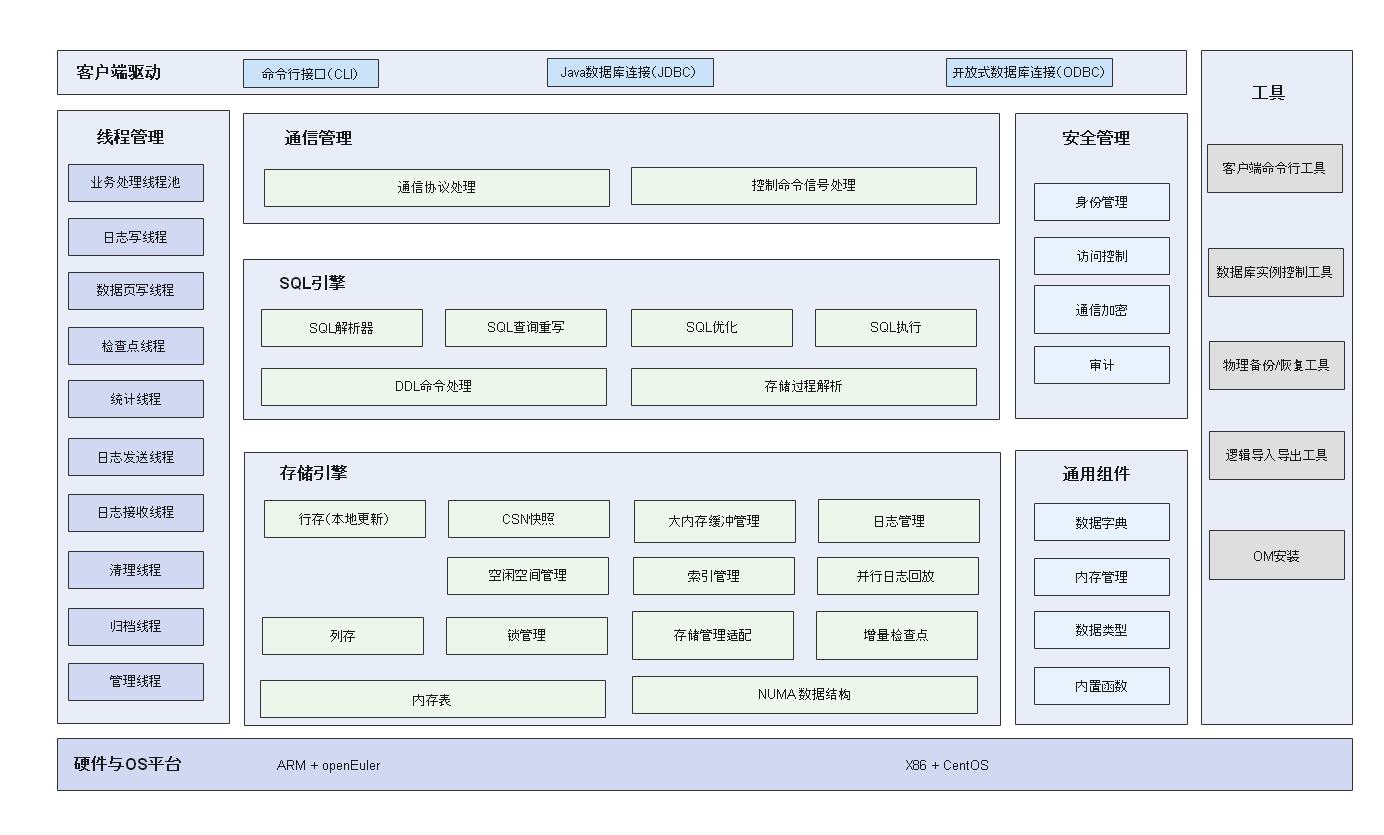
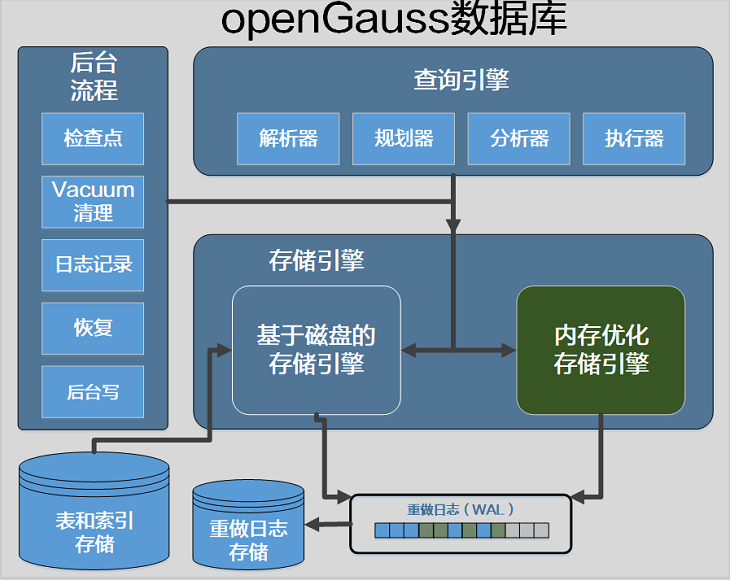
1. 软件架构
2. 分片架构
单体架构->RAC架构->Shared-Nothing架构对比如下:
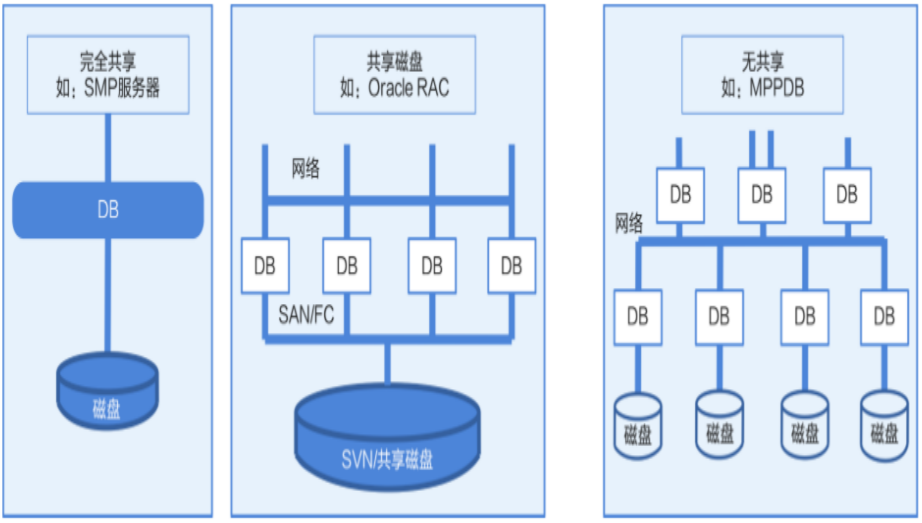
Shared-Nothing架构优点:
易于扩展:节点支持在线扩展,且无共享磁盘,性能接近线性上升。
并行处理:数据分布在多个节点,访问数据库时,每个节点对所属部分数据进行并行处理(CPU计算和IO处理都可并行)。
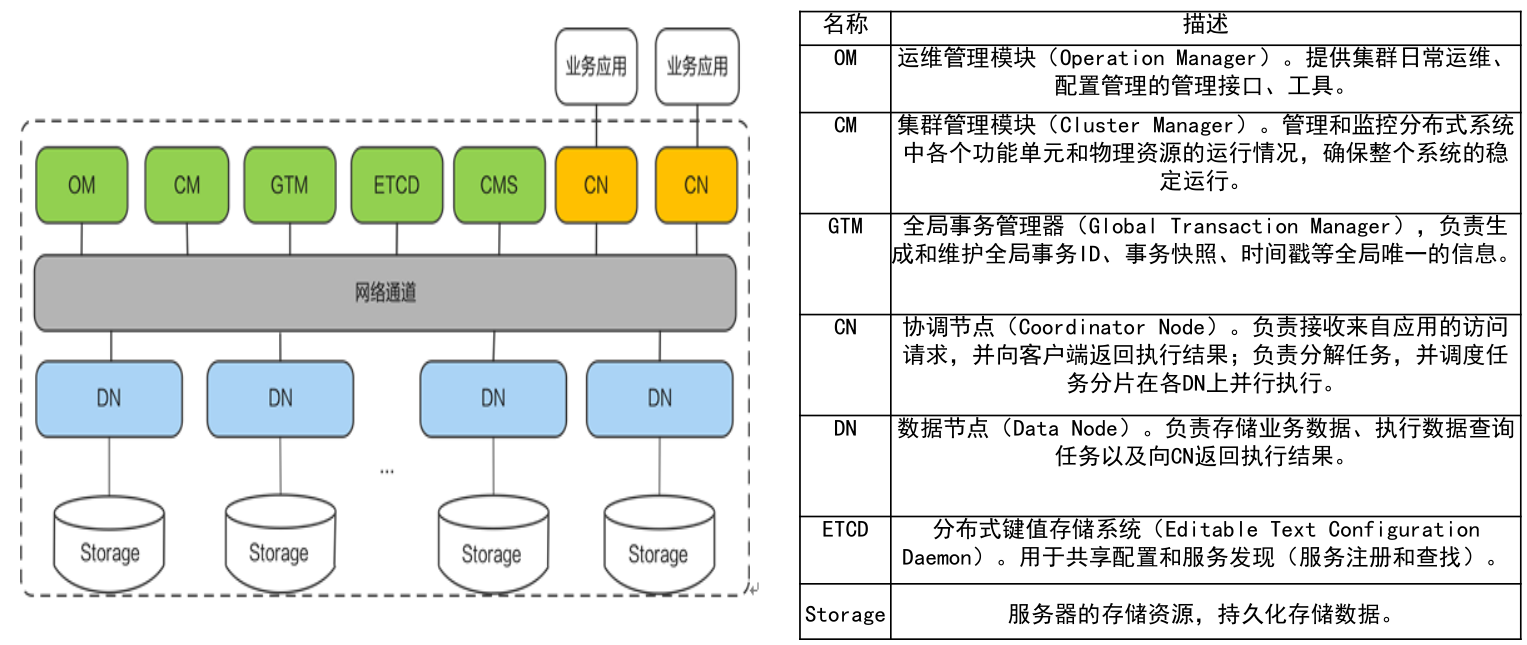
3. 核心组件
3. 逻辑架构
openGauss的数据节点负责存储数据,包含数据库、表空间、数据文件、表、数据块等。

数据库:用于管理各类数据对象,与其他数据库隔离。
表空间:在openGauss中,表空间是一个目录,其中是一些物理文件,其管理功能依赖文件系统。
模 式:数据库对象集,包括逻辑结构,例如表、视图、序、存储过程、同义名、索引及数据库链接等。
数据文件:通常每张表只对应一个数据文件。如果某张表的数据大于1GB,则会分为多个数据文件存储。
注意:
数据库和表空间是交叉的关系,一个数据库的对象可分布在多个表空间,一个表空间可存放多个数据库的对象。
数据库和模式是从属的关系,一个数据库可以创建多个模式,多个模式之间对象可以同名。
表空间是物理存储和逻辑存储之间的一层抽象,向下依赖物理文件,向上抽象为逻辑结构。
4. 内存结构
第02章_实例管理
第一节 数据库
1. 创建数据库
181-- 创建数据库2CREATE DATABASE database_name;3
4-- 指定兼容模式和字符集-集中式5-- 兼容Oracle模式字符集为UTF-8的数据库6create database test1_ora encoding='UTF8' dbcompatibility 'A';7-- 兼容PG模式字符集为GBK的数据库 8create database test4_pg encoding='GBK' dbcompatibility 'PG'; 9
10-- 指定兼容模式和字符集-分布式11-- 兼容Oracle模式字符集为utf8的数据库12create database oracle_1 with owner=sunjy01 tablespace=ds_ceshi ENCODING='utf-8' DBCOMPATIBILITY 'ora';13-- 兼容PG模式字符集为gbk的数据库14create database postgresql_2 with owner=sunjy01 tablespace=ds_ceshi ENCODING='gbk' DBCOMPATIBILITY 'PG'; 15
16-- 查询数据库及兼容模式17select datname,encoding,datcompatibility from pg_database where datname=('test1_ora','test2_pg');18
注意:
一个openGauss实例包括多个数据库,但任何与服务器连接的用户都只能访问连接请求里声明的那个数据库。
2. 查看和修改数据库
181-- 查看已经存在的数据库2openGauss=# \l3SELECT * FROM pg_database;4
5-- 查询当前数据库6SELECT CURRENT_CATALOG;7
8-- 进入已存在数据库9openGauss=# \c db_tpcc10Non-SSL connection (SSL connection is recommended when requiring high-security)11You are now connected to database "db_tpcc" as user "omm".12
13-- 数据库重命名14ALTER DATABASE database_name RENAME TO new_name;15
16-- 删除数据库17DROP DATABASE database_name ;18
3. 数据库参数配置
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DatabaseAdministrationGuide/设置参数.html
121-- 查看所有参数2SHOW ALL;3SELECT * FROM pg_settings;4
5-- 查看已配置的参数6SHOW server_version;7SELECT * FROM pg_settings WHERE NAME='server_version';8
9-- 设置参数10gs_guc reload -D /gaussdb/data/dbnode -c "failed_login_attempts=10"11gs_guc reload -N all -I all -c "password_lock_time=1"12
第二节 用户
1. 查询用户信息
121-- 查询用户列表2SELECT * FROM pg_user; 3
4-- 查询用户属性5SELECT * FROM pg_authid; 6
7-- 查询当前用户8SELECT USER;9SELECT CURRENT_USER; 10SELECT SESSION_USER;11SELECT CURRENT_ROLE;12
2. 创建或删除用户
一个openGauss实例包括多个用户和用户组,这些用户和用户组在实例范围内是共享的。创建用户的语句如下:
101-- 创建管理员用户2CREATE USER sysadmin WITH SYSADMIN password "xxxxxxxxx";3
4-- 创建普通用户,并授予postgresql_1库的所有权限5create user sunjy01 password 'sunjy_123';6GRANT ALL PRIVILEGES ON DATABASE postgresql_1 to sunjy01;7
8-- 删除用户9DROP USER IF EXISTS sunjy01 CASCADE;10
3. 修改或锁定用户
131-- 修改用户名2ALTER USER user_name RENAME TO new_name;3
4-- 锁定/解锁用户5ALTER USER user_name ACCOUNT { LOCK | UNLOCK };6
7-- 修改用户有效期8ALTER USER joe WITH VALID BEGIN '2016-11-10 08:00:00' VALID UNTIL '2017-11-10 08:00:00';9
10-- 修改或重置与用户相关的会话参数值11ALTER USER user_name SET configuration_parameter { { TO | = } { value | DEFAULT } | FROM CURRENT };12ALTER USER user_name RESET { configuration_parameter | ALL };13
注意:
如果用户输入密码次数超过一定次数(failed_login_attempts,默认10次),系统将自动锁定该帐户,默认1天后解锁。
第三节 表空间
表空间一般用于隔离磁盘IO,openGauss自带了两个表空间:
pg_default:默认表空间(base目录),用来存储非共享系统表、用户表、用户表index、临时表、临时表index、内部临时表。
pg_global:共享表空间(global目录),用来存放共享系统表的表空间。
1. 创建表空间
121-- 创建表空间2-- 其中“tablespace/tablespace_1”是用户拥有读写权限的空目录3CREATE TABLESPACE fastspace RELATIVE LOCATION 'tablespace/tablespace_1';4-- 将“fastspace”表空间的访问权限赋予数据用户jack5GRANT CREATE ON TABLESPACE fastspace TO jack;6
7-- 重命名表空间8ALTER TABLESPACE fastspace RENAME TO fspace;9
10-- 删除表空间11DROP TABLESPACE fspace;12
2. 使用表空间
131-- 查询系统和用户的表空间2SELECT spcname FROM pg_tablespace;3openGauss=# \db4
5-- 查询表空间的当前使用情况(单位为字节)6SELECT PG_TABLESPACE_SIZE('example');7
8-- 在指定表空间中创建表9CREATE TABLE foo(i int) TABLESPACE fastspace;10
11-- 设置当前环境的默认表空间12SET default_tablespace = 'fastspace';13
第四节 模式
1. 模式简介
模式(schema)允许多个用户使用同一数据库而不相互干扰,可以将数据库对象组织成易于管理的逻辑组。
一个数据库中可以创建多个模式,多个模式中的对象可以重名,用户根据其对schema的权限进行访问。
不能创建以PG_为前缀的schema名,该类schema为数据库系统预留的。
在每次创建新用户时,系统会在当前登录的数据库中为新用户创建一个同名Schema(注:其它数据库并没有)。
数据库创建初始,默认具有一个名为public的Schema,且所有用户都拥有此Schema的usage权限(注:普通用户无CREATE权限)。
每个数据库都包含一个pg_catalog模式,它包含系统表和所有内置数据类型、函数、操作符。
121-- 查询所有模式2SELECT * FROM pg_namespace;3
4-- 查询当前模式5SELECT CURRENT_SCHEMA;6
7-- 查询模式所有者8SELECT s.nspname,u.usename AS nspowner FROM pg_namespace s, pg_user u WHERE nspname='schema_name' AND s.nspowner = u.usesysid;9
10-- 查询某个模式下的所有表11 SELECT distinct(tablename),schemaname from pg_tables where schemaname = 'pg_catalog';12
2. 创建或删除模式
201-- 创建模式并指定拥有者2CREATE SCHEMA myschema;3CREATE SCHEMA myschema AUTHORIZATION omm;4
5-- 将模式授权给用户/回收用户的模式权限6-- 默认情况下,所有角色都拥有在public模式上的USAGE权限,但是普通用户没有在public模式上的CREATE权限7GRANT USAGE ON schema myschema TO jack;8REVOKE USAGE ON schema myschema FROM jack;9
10-- 查询和设置模式搜索路径11-- 在不带模式访问对象时,就会用到模式搜索路径,该路径前2位固定为pg_temp和pg_catalog12SHOW SEARCH_PATH;13SET SEARCH_PATH TO myschema, public;14
15-- 删除模式并级联删除所有对象16DROP SCHEMA IF EXISTS myschema CASCADE;17 18-- 删除空模式19DROP SCHEMA IF EXISTS nullschema;20
3. 使用模式
91-- 查询当前模式2SELECT current_schema();3
4-- 在指定模式下创建表5CREATE TABLE myschema.mytable(id int, name varchar(20));6
7-- 查询指定模式下的表8SELECT * FROM myschema.mytable;9
4. 修改模式
91-- 重命名模式2ALTER SCHEMA ds RENAME TO ds_new;3
4-- 修改模式的所有者5ALTER SCHEMA ds_new OWNER TO jack;6
7-- 修改模式的默认字符集和字符序8ALTER SCHEMA ds_new CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;9
第五节 角色
1. 查询和使用角色
51-- 查询所有角色2SELECT * FROM PG_ROLES;3
4-- 将角色授给用户5GRANT lily to joe;注意:
默认情况下,所有创建的用户和角色默认拥有PUBLIC所拥有的权限。
openGauss提供了一组默认角色,以gs_role_开头命名,如gs_role_copy_files、gs_role_tablespace等。
2. 创建或删除角色
91-- 创建角色,名为manager,密码为xxxxxxxxx2CREATE ROLE manager IDENTIFIED BY 'xxxxxxxxx';3
4-- 创建角色,从2015年1月1日开始生效,到2026年1月1日失效。5CREATE ROLE miriam WITH LOGIN PASSWORD 'xxxxxxxxx' VALID BEGIN '2015-01-01' VALID UNTIL '2026-01-01';6
7-- 删除角色8DROP ROLE IF EXISTS role_name;9
注意:
角色是拥有数据库对象和权限的实体。在不同的环境中角色可以认为是一个用户,一个组或者兼顾两者。
3. 修改角色
121-- 修改角色名称2ALTER ROLE role_name RENAME TO new_name;3
4-- 锁定/解锁角色5ALTER ROLE role_name ACCOUNT { LOCK | UNLOCK };6
7-- 修改角色manager的密码为abcd@1238ALTER ROLE manager IDENTIFIED BY '$$$$$$$$' REPLACE 'xxxxxxxxx';9
10-- 修改角色manager为系统管理员11ALTER ROLE manager SYSADMIN;12
第六节 权限
1. 权限简介
数据对象创建后,创建用户即对象所有者,默认情况下(未开启三权分立),只有管理员和该用户才能访问该对象。
管理员包括初始用户(安装用户)、具有SYSADMIN/OPRADMIN等属性的帐户,设置用户为管理员的语句如下:
81-- 创建管理员用户2CREATE USER sysadmin WITH SYSADMIN password "xxxxxxxxx";3
4-- 将已有用户设置为管理员5ALTER USER joe SYSADMIN;6
7-- 查询所有权限8SELECT * FROM pg_authid;其它用户则可以按需授权,支持的授权类别有:SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、CREATE、CONNECT、EXECUTE、ALTER、DROP、COMMENT、INDEX、VACUUM和USAGE等。
注意:
为了限制SYSADMIN的权限,在openGauss中,可以禁止其CREATEROLE属性(创建角色和用户的权限)和AUDITADMIN属性(查看和维护数据库审计日志的权限),请参考三权分立 。
2. 系统权限
61-- 将系统权限(sysadmin)授权给用户或者角色2GRANT ALL PRIVILEGES TO joe;3
4-- 回收系统权限5REVOKE ALL PRIVILEGES FROM joe; 6
3. 对象权限
71-- 将表customer的所有权限授权给用户joe,并授予模式test的使用权限2GRANT ALL PRIVILEGES ON customer TO joe;3GRANT USAGE ON SCHEMA test TO joe; 4
5-- 将表customer中c_customer_sk、c_customer_id、c_first_name列的查询权限,c_last_name的更新权限授权给joe6GRANT select (c_customer_sk,c_customer_id,c_first_name),update (c_last_name) ON customer TO joe;7
注意:
在授予对象权限时,需一并授予该对象所属模式的USAGE权限,否则只能看到对象名称,而不能实际访问对象
4. 权限传递
41-- 默认情况下不允许权限传递,需添加如下选项2GRANT joe TO manager WITH ADMIN OPTION; 3GRANT create,connect on database postgres TO joe WITH GRANT OPTION;4
第七节 事务
1. 事务控制命令
141-- 设置事务隔离级别2{ SET [ LOCAL ] TRANSACTION|SET SESSION CHARACTERISTICS AS TRANSACTION }3 { ISOLATION LEVEL { READ COMMITTED | SERIALIZABLE | REPEATABLE READ }4 | { READ WRITE | READ ONLY } } [, ...];5
6-- 开启事务7START TRANSACTION(或BEGIN)8
9-- 提交事务10COMMIT;11
12-- 回滚事务13ROLLBACK; 14
注意:
GaussDB Kernel 采用了多版本并发控制(MVCC)结合两阶段锁的方式来管理事务, 其特点是事务之间不阻塞。
GaussDB Kernel 没有回滚段的概念,采用 VACUUM 线程定期清除历史版本数据。
第八节 锁
1. 查询锁
261-- 查询数据库中的锁信息2-- SELECT * FROM pg_locks;3select c.datname, b.relname, d.*, a.*, b.*, c.*4 from pg_locks a 5 left join pg_class b on a.relation = b.oid 6 left join pg_database c on a.database = c.oid7 left join pg_stat_activity d on a.pid = d.pid8 where c.datname = 'kbmsdb8'9 and b.relname = 'risk_log_cust_stk'10 order by c.datname, b.relname;11 12-- 查询等待锁的线程状态信息13SELECT * FROM pg_thread_wait_status WHERE wait_status = 'acquire lock';14
15-- 查询被锁阻塞的会话16SELECT w.query AS waiting_query, w.pid AS w_pid, w.usename AS w_user, l.query AS locking_query, l.pid AS l_pid, l.usename AS l_user, t.schemaname||'.'||t.relname AS tablename17 FROM pg_stat_activity w18 JOIN pg_locks l1 ON w.pid = l1.pid AND NOT l1.granted19 JOIN pg_locks l2 ON l1.relation = l2.relation AND l2.granted20 JOIN pg_stat_activity l ON l2.pid = l.pid21 JOIN pg_stat_user_tables t ON l1.relation = t.relid22 WHERE w.waiting = true;23
24-- 终止会话进程25SELECT pg_terminate_backend(139834762094352);26
注意:
可以通过
ps ux查找正在运行的系统进程,然后使用kill -9 pid命令结束此进程。
2. 表级锁
1) 自动加锁
| 申请该锁的语句 | |
|---|---|
| ACCESS SHARE | SELECT |
| ROW SHARE | SELECT FOR SHARE、SELECT FOR UPDATE |
| ROW EXCLUSIVE | UPDATE、INSERT、DELETE |
| SHARE UPDATE EXCLUSIVE | VACUUM、ANALYZE、CREATE INDEX CONCURRENTLY |
| SHARE | CREATE INDEX |
| SHARE ROW EXCLUSIVE | 任何SQL语句都不会自动请求这个锁模式(注意:该锁是独占锁,一个会话中只能获取一次)。 |
| EXCLUSIVE | 任何SQL语句都不会在用户表上自动请求这个锁模式,但可能在某些操作的时候,在系统表上请求 |
| ACCESS EXCLUSIVE | ALTER TABLE,DROP TABLE,TRUNCATE,REINDEX。保证其加锁事务是可以访问该表的唯一事务 |
当表级锁相互兼容时,才可以加锁成功:
| AS | RS | RX | SUE | S | SRX | X | AX | |
|---|---|---|---|---|---|---|---|---|
| AS | - | - | - | - | - | - | - | X |
| RS | - | - | - | - | - | - | X | X |
| RX | - | - | - | - | X | X | X | X |
| SUE | - | - | - | X | X | X | X | X |
| S | - | - | X | X | - | X | X | X |
| SRX | - | - | X | X | X | X | X | X |
| X | - | X | X | X | X | X | X | X |
| AX | X | X | X | X | X | X | X | X |
2) 手动加锁
91-- 语法格式2-- NOWAIT:不去等待任何冲突的锁释放,如果无法立即获取该锁,该命令退出并且发出一个错误信息3LOCK [ TABLE ] name IN lock_mode MODE [NOWAIT]4
5-- 示例6START TRANSACTION;7LOCK TABLE reason_t1 IN SHARE ROW EXCLUSIVE MODE;8LOCK TABLE graderecord IN ACCESS EXCLUSIVE MODE;9COMMIT;注意:
LOCK语句必须在事务中执行,否则会报错。没有UNLOCK TABLE命令,锁总是在事务结束时释放。
以ACCESS SHARE模式加锁需要表的SELECT权限,其他形式的LOCK需要UPDATE和/或DELETE权限。
第九节 备份恢复
1. 逻辑备份与恢复
基于备份时刻进行数据转储,其对于故障点和备份点之间的数据无能为力。
全库恢复时,通常需要重建数据库,导入备份数据来完成,恢复时间较长。
适用于数据量小或变化很少的数据,以及进行异构数据库之间的数据迁移。
381-- ------------------- 方式一(gs_dump) ------------------- --2-- 灵活导出数据对象,可选择纯文本格式或者归档格式3-- 纯文本格式只能使用gsql恢复,恢复时间较长,归档格式只能使用gs_restore恢复,恢复时间中等4-- 需由操作系统用户omm执行,在进行数据导出时,其他用户可以访问openGauss数据库(读或写)5-- gs_dump在启动时,全局加共享锁(–lock-wait-timeout),生成全局一致性快照,导出此时刻数据6
7-- 以纯文本格式/tar归档格式/目录归档格式/自定义归档格式导出某个库8gs_dump -h 127.0.0.1 -U kbms -W SZking@996 -f ./kbmsdb8.sql -p 30100 kbmsdb8 -F p9gs_dump -h 127.0.0.1 -U omm -W Bigdata@123 -f backup/MPPDB_backup.tar -p 37300 postgres -F t10gs_dump -h 127.0.0.1 -U omm -W Bigdata@123 -f backup/MPPDB_backup -p 37300 postgres -F d11gs_dump -h 127.0.0.1 -U omm -W Bigdata@123 -f backup/MPPDB_backup.dmp -p 37300 postgres -F c12
13-- 指定用户导出数据库14gs_dump dbname -h host_name -p port -f out.sql -U user_name -W password15
16-- 导出schema17gs_dump dbname -h host_name -p port -n schema_name -f out.sql18
19-- 导出table20gs_dump dbname -h host_name -p port -t table_name -f out.sql21
22-- 导出指定库和模式的表结构23gs_dump -h 10.201.69.92 -U kbms -W SZking@996 -p 30100 kbmsdb1 -n kbms -s -F p -f dump_file.sql24
25-- ------------------- 方式二(gs_dumpall) ------------------- --26-- 导出所有数据库相关信息,包括默认数据库postgres的数据、自定义数据库的数据、以及所有数据库公共的全局对象等27-- 只能导出为纯文本格式,只能使用gsql恢复28gs_dumpall -f backup/bkp2.sql -p 3730029
30-- ------------------- 逻辑恢复(gsql/gs_restore) ------------------- --31-- 恢复gs_dump和gs_dumpall导出的纯文本格式数据32gsql -h 127.0.0.1 -U kbms -d kbmsdb8 -p 30100 -W Bigdata@123 -f ./kbmsdb8.sql33
34-- 恢复gs_dump导出的归档格式数据35gs_restore -W Bigdata@123 backup/MPPDB_backup.dmp -p 15400 -d postgres36gs_restore backup/MPPDB_backup.tar -p 15400 -d postgres 37gs_restore backup/MPPDB_backup -p 15400 -d postgres38
参考:
2. 物理备份与恢复
通过物理文件拷贝的方式对数据文件及归档日志等文件进行备份,数据库可以进行完全恢复。
物理备份速度快,适用于数据量大的场景,主要用于全量数据备份恢复
321-- ------------------- 方式一(gs_backup) ------------------- --2-- 导出数据库参数文件和二进制文件3
4-- 备份数据库主机5gs_backup -t backup --backup-dir=/opt/software/gaussdb/backup_dir -h plat1 --parameter6
7-- 恢复数据库主机8gs_backup -t restore --backup-dir=/opt/software/gaussdb/backup_dir -h plat1 --parameter9
10
11-- ------------------- 方式二(gs_basebackup) ------------------- --12-- 对服务器数据库文件的二进制进行全量拷贝,只能对数据库某一个时间点的时间作备份13-- 结合PITR恢复,可恢复全量备份时间点后的某一时间点。14-- 恢复时可以直接拷贝替换原有的文件, 或者直接在备份的库上启动数据库,恢复时间快15
16-- 备份17gs_basebackup -D /home/test/trunk/install/data/backup -h 127.0.0.1 -p 2123318
19-- ------------------- 方式三(gs_probackup) ------------------- --20-- 对openGauss 实例进行定期物理备份,支持增量备份、定期备份和远程备份21-- 恢复时可以直接恢复到某个备份点,在备份的库上启动数据库,恢复时间快22
23-- 初始化备份目录24gs_probackup init -B backup_dir25-- 添加一个新的备份实例26gs_probackup add-instance -B backup_dir -D data_dir --instance instance_name27-- 创建指定实例的备份28gs_probackup backup -B backup_dir --instance instance_name -b backup_mode29
30-- 从指定实例的备份中恢复数据31gs_probackup restore -B backup_dir --instance instance_name -D pgdata-path -i backup_id32
3. 闪回恢复
基于MVCC和回收站机制,闪回恢复历史数据或删除的表。
适用于误删除表的场景或需要将表中的数据恢复到指定时间点或者CSN。
恢复时间非常快(只需要秒级),而且恢复时间和数据库大小无关。
221-- https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DatabaseOMGuide/%E9%97%AA%E5%9B%9E%E6%81%A2%E5%A4%8D.html2
3-- 闪回查询4SELECT * FROM t1 TIMECAPSULE TIMESTAMP to_timestamp ('2020-02-11 10:13:22.724718', 'YYYY-MM-DD HH24:MI:SS.FF');5SELECT * FROM t1 TIMECAPSULE CSN 9617;6
7-- 闪回表8-- 需开启enable_recyclebin参数,启用回收站9-- recyclebin_retention_time参数用于设置回收站对象保留时间,超过该时间的回收站对象将被自动清理10TIMECAPSULE TABLE t1 TO BEFORE DROP;11TIMECAPSULE TABLE t1 TO BEFORE DROP RENAME TO new_t1;12TIMECAPSULE TABLE "BIN$04LhcpndanfgMAAAAAANPw==$0" TO BEFORE DROP;13TIMECAPSULE TABLE "BIN$04LhcpndanfgMAAAAAANPw==$0" TO BEFORE DROP RENAME TO new_t1;14
15-- 清理回收站16DROP TABLE t1 PURGE;17PURGE TABLE t1;18PURGE TABLE "BIN$04LhcpndanfgMAAAAAANPw==$0";19PURGE INDEX i1;20PURGE INDEX "BIN$04LhcpndanfgMAAAAAANPw==$0";21PURGE RECYCLEBIN;22
4. 数据导入导出
导出数据可使用
gs_dump或gs_dumpall来进行,支持按实例、数据库、模式、表等粒度进行导出。可参考:导出数据导入数据可使用
gsql、gs_restore、\copy元命令、COPY FROM STDIN、CopyManager(Java)等方式。可参考:导入数据示例:
51# 服务端导出2COPY evt_creditdebts TO '/home/lptest/hyx/evt_creditdebts.csv' WITH (FORMAT 'csv', DELIMITER ',');3
4# 客户端导出5\COPY evt_creditdebts TO '/home/lptest/hyx/evt_creditdebts.csv' WITH (FORMAT 'csv', DELIMITER ',');
第十节 数据字典
1. 查询对象信息
351-- 查询对象信息2-- 存储数据库对象信息及其之间的关系, 记录几乎 所有的数据库对象 信息3SELECT * FROM pg_class;4
5-- 查询所有表及描述6select a.relname as name, b.description as value7 from pg_class a8 left join (select * from pg_description where objsubid = 0 ) b on a.oid = b.objoid9 where a.relname in(select tablename from pg_tables where schemaname = 'kfms')10 order by a.relname asc11
12-- 查询数据库信息13SELECT * FROM pg_database;14
15-- 查询表空间信息16SELECT * FROM pg_tablespace;17
18-- 查询模式信息19SELECT * FROM pg_namespace;20
21-- 查询类型信息22SELECT * FROM pg_type;23
24-- 查询表字段信息25SELECT * FROM pg_attribute;26
27-- 查询视图信息28SELECT * FROM pg_views;29
30-- 查询索引信息31SELECT * FROM pg_index;32
33-- 查询角色信息34SELECT * FROM pg_roles;35
2. 查询分布式对象信息
151-- 查看分区表2SELECT * FROM pgxc_class;3
4-- 查询集群节点信息5SELECT * FROM pgxc_node;6
7-- 查询节点组信息8SELECT * FROM pgxc_group;9
10-- 表复制或分布信息11SELECT * FROM pgxc_class;12
13-- 查询LIST和RANGE分布的具体分布信息14SELECT * FROM pgxc_slice;15
3. 查询统计信息
251-- 查询统计信息2SELECT * FROM pg_stats;3
4-- 查询当前活动5-- 状态:active(正在执行SQL)、idle(等待命令)、idle in transaction(等待命令且处于事务中)、6-- idle in transaction (aborted)(事务中的SQL报错)、fastpath function call(正在执行fast-call函数)7-- disabled(track_activities被禁用)8SELECT * FROM pg_stat_activity;9
10-- 当前连接用户和机器11SELECT datname,usename,client_addr,client_port FROM pg_stat_activity; 12-- 当前活跃连接数13SELECT count(*) FROM pg_stat_activity E WHERE state <> 'idle'; -- SHOW max_connections; -- 最大连接数14-- 当前正在执行的SQL15SELECT datname,usename,query M FROM pg_stat_activity; 16-- 查询最耗时的SQL17SELECT current_timestamp - query_start as runtime, datname, usename, sessionid, query18 FROM pg_stat_activity E19 WHERE state != 'idle'20 ORDER BY 1 DESC;21 22 -- 查询当前阻塞23 -- wait_status:none(无等待)、wait io(等待IO完成)、wait cmd(等待读取网络通信包)、acquire lock(等待加锁)、acquire lwlock(等待获取轻量级锁)24 SELECT * FROM pg_thread_wait_status;25
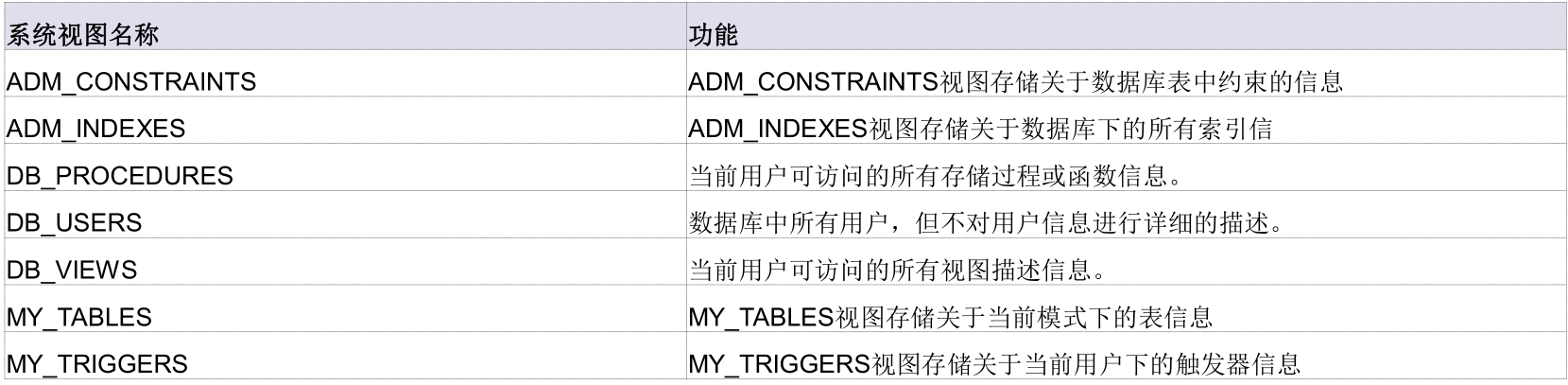
4. 系统视图
MY_:包含当前数据库用户所拥有的所有的模式对象的信息。
DB_:包含当前数据库用户可以访问的所有的模式对象的信息。
ADM_:包含所有数据库对象信息,只有具有 DBA 角色/系统管理员权限的用户才能够访问这些视图。
第03章_数据对象
第一节 数据类型
1. 字符型
| 数据类型 | 说明 |
|---|---|
| CHAR(size) | 定长字符串,不足补空格,最大为10MB |
| VARCHAR(size)/VARCHAR2(size) | 变长字符串,可存储10MB字节或字符 |
注意:
PG兼容性下,CHAR和VARCHAR以字符为计数单位,其它兼容性以字节为计数单位,即CHAR(3)只能存放一个UTF-8编码字符。
ORA兼容性下,数据库将空字符串作为NULL处理。
2. 数值型
| 数据类型 | 说明 |
|---|---|
| NUMBER(p,s)/DECIMAL(p,s)/NUMERIC(p,s) | 精确数值类型。p为总位数,s为小数位数。 |
| TINYINT/SMALLINT/INTEGER/BIGINT | 分别占1/2/4/8个字节,取值范围随之增加。 |
| FLOAT/Double | 浮点数,不精确小数,不推荐使用 |
注意:
将字符串转换成整数类型时,如果输入不合法,MYSQL兼容性会将输入转换为0,而其它兼容性则会报错。
3. 日期/时间
| 数据类型 | 说明 |
|---|---|
| Date | 日期时间类型 |
| TIMESTAMP[(p)] | 日期和时间。p表示小数点后的精度,取值范围为0~6。 |
注意:
ORA兼容性下,数据类型DATE会被替换为TIMESTAMP(0) WITHOUT TIME ZONE。
4. 其它数据类型
| 数据类型 | 说明 |
|---|---|
| SMALLSERIAL/SERIAL/BIGSERIAL | 序列整型,分别占用2/4/8字节,会在后台自动创建一个对应的Sequence,用来实现自增。 |
| BOOLEAN | 布尔类型,取值有 true-真 false-假 null-未知 三种 |
注意:
高斯开发规范中不建议使用序列整型。
第二节 数据表
1. 查询表信息
121-- 查询所有表2SELECT * FROM pg_tables;3
4-- 查询表字段5SELECT * FROM pg_attribute; 6
7-- 查询表的结构信息8openGauss=# \d+ table_name 9
10-- 查询表的统计信息11SELECT * FROM pg_statistic;12
2. 创建表
301
2-- 创建普通表,并指定表空间3CREATE TABLE IF NOT EXISTS customer_t14(5 c_customer_sk integer,6 c_customer_id char(5) PRIMARY KEY,7 c_first_name char(6),8 c_last_name char(8),9 Amount integer10) TABLESPACE DS_TABLESPACE1;11
12-- 创建临时表0113-- 临时表不能指定schema14CREATE TEMPORARY TABLE warehouse_t315(16 W_WAREHOUSE_SK INTEGER NOT NULL,17 W_WAREHOUSE_ID CHAR(16) NOT NULL,18 CONSTRAINT PK_01 PRIMARY KEY(W_WAREHOUSE_SK)19) ON COMMIT DELETE ROWS; -- 提交事务时删除该临时表数据20
21-- 创建临时表0222CREATE TEMP TABLE customer_temp AS SELECT * FROM customer;23
24-- 表/字段注释25COMMENT ON TABLE AUTH_INFO IS '用户密码信息表';26COMMENT ON COLUMN AUTH_INFO.USER_CODE IS '用户代码';27
28-- 删除表29DROP TABLE IF EXISTS tpcds.web_returns_p2 CASCADE;30
注意:
目前仅支持对数据库定义字符集,不支持对表、字段等其他对象定义字符集。
3. 修改表
261-- 重命名表2ALTER TABLE table_name RENAME TO new_table_name;3
4-- 重命名列5ALTER TABLE table_name RENAME column_name TO new_column_name;6
7-- 添加列/修改列/删除列8ALTER TABLE table_name ADD column_name data_type;9ALTER TABLE table_name MODIFY column_name data_type;10ALTER TABLE table_name DROP COLUMN column_name;11
12-- 可重复添加列13create or replace procedure proc_add_column(tableName varchar(128), columnName varchar(128), columnInfo varchar(128)) 14as 15 v_sql varchar(2048);16begin 17 if not exists (select 1 from information_schema.columns a where table_schema='kbms' and table_name = tableName and column_name= columnName) then18 v_sql := 'alter table ' || tableName || ' add column ' || columnName || ' ' || columnInfo || ';';19 execute immediate v_sql;20 end if;21end;22call proc_add_column('closeresult', 'upd_time', 'varchar(96) default to_char(now(), ''YYYY-MM-DD HH24:MI:SS.FF3'')');23
24-- 增加/删除非空约束25ALTER TABLE table_name ALTER column_name { SET | DROP } NOT NULL;26
第三节 约束
1. 添加约束
151-- 非空约束2ID INT NOT NULL3
4-- 唯一约束5AGE INT NOT NULL UNIQUE6
7-- 主键约束8 ID INT PRIMARY KEY9
10-- 外键约束11EMP_ID INT references staff3(ID)12
13-- 检查约束14SALARY INT CHECK(SALARY > 0)15
2. 修改约束
61alter table emp1 add primary key (empno); -- 添加主键约束2alter table emp1 add constraint chk_dept check (deptno is not null); -- 添加check约束3alter table emp1 add constraint fk_dept foreign key (deptno) references dept(deptno); -- 添加外键约束4alter table emp1 modify sal constraint chk_sal not null; -- 修改列约束条件5alter table emp1 rename constraint chk_dept to chk_deptno; -- 重命名约束6ALTER TABLE table_name ALTER column_name { SET | DROP } NOT NULL; -- 增加删除非空约束
第四节 索引
1. 创建索引
221-- 创建普通索引2CREATE INDEX more_column_index ON tpcds.customer_address_bak(ca_address_sk ,ca_street_number );3
4-- 创建条件索引5CREATE INDEX part_index ON tpcds.customer_address_bak(ca_address_sk) WHERE ca_address_sk = 5050;6
7-- 创建函数索引8CREATE INDEX para_index ON tpcds.customer_address_bak (trunc(ca_street_number));9
10-- 创建分区表本地索引11CREATE INDEX tpcds_web_returns_p2_index1 ON tpcds.web_returns_p2 (ca_address_id) LOCAL;12
13-- 创建分区表全局索引14CREATE INDEX tpcds_web_returns_p2_global_index ON tpcds.web_returns_p2 (ca_street_number) GLOBAL;15
16-- 删除索引17DROP INDEX tpcds.tpcds_web_returns_p2_index1;18
19-- 重建索引20REINDEX TABLE areaS;21REINDEX INTERNAL TABLE areaS;22
2. 查询和使用索引
71-- 查询系统和用户定义的所有索引2SELECT * FROM pg_index;3SELECT RELNAME FROM PG_CLASS WHERE RELKIND='i' or RELKIND='I';4
5-- 查询索引的详细信息6openGauss=# \d+ index_name7
第五节 视图
1. 创建视图
101-- 创建视图2CREATE OR REPLACE VIEW MyView AS SELECT * FROM tpcds.web_returns WHERE trunc(wr_refunded_cash) > 10000;3
4-- 查询视图的详细信息5openGauss=# \d+ dba_users6select pg_get_viewdef('v1'); -- 查询视图定义7
8-- 删除视图9 DROP VIEW MyView;10 注意:
OR REPLACE不能改变原有视图的列名、列类型或列顺序等,只可在列表末尾添加其他的列。
2. 物化视图
物化视图是相对普通视图而言的,普通视图是虚拟表,而物化视图实际上就是存储SQL执行语句的结果,可以直接使用数据而不用重复执行查询语句,从而提升性能。按照刷新方式物化视图分为两种:
全量物化视图:仅支持对已创建的物化视图进行全量更新,而不支持进行增量更新。
增量物化视图:可以对物化视图增量刷新,需要用户手动执行语句完成对物化视图在一段时间内的增量数据刷新。
181-- 创建全量物化视图2CREATE MATERIALIZED VIEW view_name AS query; 3
4-- 创建增量物化视图5CREATE INCREMENTAL MATERIALIZED VIEW view_name AS query ; 6
7-- 全量刷新物化视图8REFRESH MATERIALIZED VIEW [ view_name ];9
10-- 增量刷新物化视图11REFRESH INCREMENTAL MATERIALIZED VIEW [ view_name ];12
13-- 删除物化视图14DROP MATERIALIZED VIEW [ view_name ];15
16-- 查询物化视图17SELECT * FROM [ view_name ];18
注意:
目前物化视图创建语句仅支持基表扫描语句或者UNION ALL语句。
第六节 序列
1. 创建序列
201-- 方式一:使用序列整型2CREATE TABLE T13(4 id serial,5 name text6);7
8-- 方式二:直接创建序列,并指定为某字段的默认值9CREATE SEQUENCE seq1 cache 100;10CREATE TABLE T2 11( 12 id int not null default nextval('seq1'),13 name text14);15-- 也可以在创建表后再指定16alter table t2 alter tag set default nextval('seq01');17
18-- 指定序列和字段的关联关系19ALTER SEQUENCE seq1 OWNED BY T2.id;20
2. 查看和使用序列
261-- 查看序列2\d t2_id_seq3select * from seq01;4
5-- 递增序列并返回新值6select nextval('seq01'); 7select seq01.nextval;8
9-- 返回当前会话里最近一次nextval返回的指定的sequence的数值10-- 如果当前会话还没有调用过指定的sequence的nextval,那么调用currval将会报错。11select currval('seq01'); -- 最近一次nextval返回的值12select seq01.currval;13
14-- 返回当前会话里最近一次nextval返回的数值。15-- 这个函数等效于currval,只是它不用序列名为参数,它抓取当前会话里面最近一次nextval使用的序列。16-- 如果当前会话还没有调用过nextval,那么调用lastval将会报错17select lastval();18
19-- 获取最近一次为自动增长列成功插入的第一个自动生成的值20last_insert_id()21
22-- 设置序列的当前数值23-- Setval后当前会话会立刻生效,但如果其他会话有缓存的序列值,只能等到缓存值用尽才能感知Setval的作用24-- 所以为了避免序列值冲突,setval要谨慎使用。 因为序列是非事务的,setval造成的改变不会由于事务的回滚而撤销25select setval('seq01',1); 26
3. 修改序列
31-- 修改序列属性2alter sequence seq01 maxvalue 99999;3alter sequence seq01 owner to jack;
第七节 MOT(内存表)
1. MOT简介
MOT(Memory-Optimized Table)是一种将数据和索引存储在内存中,将事务日志持久化的内存表,可以同时做到高性能和ACID。
2. MOT的基本使用
221-- MOT授权2-- MOT通过外部数据封装器(Foreign Data Wrapper,FDW)机制与openGauss数据库集成,所以需要授权用户权限3GRANT USAGE ON FOREIGN SERVER mot_server TO <user>;4
5-- 创建MOT表6-- 注:如果postgresql.conf中开启了增量检查点,则无法创建MOT。因此请在创建MOT前将enable_incremental_checkpoint设置为off。7create FOREIGN table test(x int) ;8
9-- 创建索引10create index text_index1 on test(x) ;11
12-- 查询表或索引大小13select pg_relation_size('customer');14
15-- 查询占用内存大小16select * from mot_global_memory_detail();17select * from mot_local_memory_detail();18select * from mot_session_memory_detail();19
20-- 删除MOT表21drop FOREIGN table test;22
第八节 本地分区表
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/SQLReference/分区表.html
1. 范围分区
指定一个或多个列划分为多个范围,每个范围创建一个分区,用来存储相应的数据。
271-- 采用日期划分范围,将销售数据按照月份进行分区2CREATE TABLE sales_table3(4 order_no INTEGER NOT NULL,5 goods_name CHAR(20) NOT NULL,6 sales_date DATE NOT NULL,7 sales_volume INTEGER,8 sales_store CHAR(20)9)10PARTITION BY RANGE(sales_date)11(12 PARTITION season1 VALUES LESS THAN('2021-04-01 00:00:00'),13 PARTITION season2 VALUES LESS THAN('2021-07-01 00:00:00'),14 PARTITION season3 VALUES LESS THAN('2021-10-01 00:00:00'),15 PARTITION season4 VALUES LESS THAN(MAXVALUE)16);17
18-- 修改分区表行迁移属性19ALTER TABLE tpcds.web_returns_p2 DISABLE ROW MOVEMENT;20
21-- 增加分区22ALTER TABLE tpcds.web_returns_p2 ADD PARTITION P8 VALUES LESS THAN (MAXVALUE);23
24-- 重命名分区25ALTER TABLE tpcds.web_returns_p2 RENAME PARTITION P8 TO P_9;26ALTER TABLE tpcds.web_returns_p2 RENAME PARTITION FOR (40000) TO P8;27
2. 列表分区
直接按照一个列或者多个列上的值来划分出分区。
161-- 列表分区2CREATE TABLE graderecord 3( 4 number INTEGER, 5 name CHAR(20), 6 class CHAR(20), 7 grade INTEGER8) 9PARTITION BY LIST(class) 10( 11 PARTITION class_01 VALUES ('21.01'), 12 PARTITION class_02 VALUES ('21.02'),13 PARTITION class_03 VALUES ('21.03'),14 PARTITION class_04 VALUES ('21.04')15);16
3. 间隔分区
是一种特殊的范围分区,新增了间隔值定义。当插入记录找不到匹配的分区时可以根据间隔值自动创建分区。
161-- 间隔1个月2CREATE TABLE sales_table3(4 order_no INTEGER NOT NULL,5 goods_name CHAR(20) NOT NULL,6 sales_date DATE NOT NULL,7 sales_volume INTEGER,8 sales_store CHAR(20)9)10PARTITION BY RANGE(sales_date)11INTERVAL ('1 month') 12(13 PARTITION start VALUES LESS THAN('2021-01-01 00:00:00'),14 PARTITION later VALUES LESS THAN('2021-01-10 00:00:00')15);16
4. 哈希分区
根据表的一列,为每个分区指定模数和余数,将要插入表的记录划分到对应的分区中。
121-- 哈希分区2create table hash_partition_table 3(4 col1 int, 5 col2 int6)7partition by hash(col1)8(9 partition p1,10 partition p211);12
5. 查询和修改分区
121-- 查询所有分区表2SELECT * FROM pg_partition;3
4-- 指定分区查询5SELECT * FROM graderecord PARTITION (class_01);6
7-- 删除分区表8DROP TABLE employees_table;9
10-- 删除分区11ALTER TABLE web_returns_p2 DROP PARTITION P8;12
第九节 分片表(数据分布)
1. 哈希分片
对指定的列进行Hash,通过映射,把数据分布到指定DN。
101CREATE TABLE CUSTOMER_SHARD2(3 CUST_CODE bigint,4 CUST_NAME varchar(64),5 INT_ORG int,6 CUST_ATTR char(1),7 UPD_TIME TIMESTAMP,8 primary KEY(CUST_CODE)9) distribute by hash (CUST_CODE);10
2. 列表分片
对指定列按照具体值进行映射,把数据分布到对应 DN。
221CREATE TABLE warehouse_t23 ( 2 W_WAREHOUSE_SK INTEGER NOT NULL, 3 W_WAREHOUSE_ID CHAR ( 16 ) NOT NULL, 4 W_WAREHOUSE_NAME VARCHAR ( 20 ), 5 W_WAREHOUSE_SQ_FT INTEGER, 6 W_STREET_NUMBER CHAR ( 10 ), 7 W_STREET_NAME VARCHAR ( 60 ), 8 W_STREET_TYPE CHAR ( 15 ), 9 W_SUITE_NUMBER CHAR ( 10 ), 10 W_CITY VARCHAR ( 60 ), 11 W_COUNTY VARCHAR ( 30 ), 12 W_STATE CHAR ( 2 ), 13 W_ZIP CHAR ( 10 ), 14 W_COUNTRY VARCHAR ( 20 ), 15 W_GMT_OFFSET DECIMAL ( 5,2 ) 16 ) 17 WITH (orientation=row, compression=no) 18 DISTRIBUTE BY LIST(W_WAREHOUSE_SK) 19 ( 20 SLICE W_WAREHOUSE_SK VALUES ('10') 21 ) 22
3. 范围分片
对指定列按照范围进行映射,把数据分布到对应 DN。
211CREATE TABLE warehouse_t24 ( 2 W_WAREHOUSE_SK INTEGER NOT NULL, 3 W_WAREHOUSE_ID CHAR ( 16 ) NOT NULL, 4 W_WAREHOUSE_NAME VARCHAR ( 20 ), 5 W_WAREHOUSE_SQ_FT INTEGER, 6 W_STREET_NUMBER CHAR ( 10 ), 7 W_STREET_NAME VARCHAR ( 60 ), 8 W_STREET_TYPE CHAR ( 15 ), 9 W_SUITE_NUMBER CHAR ( 10 ), 10 W_CITY VARCHAR ( 60 ), 11 W_COUNTY VARCHAR ( 30 ), 12 W_STATE CHAR ( 2 ), 13 W_ZIP CHAR ( 10 ), 14 W_COUNTRY VARCHAR ( 20 ), 15 W_GMT_OFFSET DECIMAL ( 5,2 ) 16 ) 17 WITH (orientation=row, compression=no) 18 DISTRIBUTE BY RANGE(W_WAREHOUSE_ID) 19 ( 20 SLICE W_WAREHOUSE_SK VALUES LESS THAN ('10') DATANODE dn_6004_6005_6006 21 )
4. 复制表/广播表
表的每一行存在所有数据节点(DN)中,即每个数据节点都有完整的表数据,主要适用于记录集较小的表。
在join操作中可以避免数据重分布操作,从而减小网络开销,同时减少了plan segment(每个plan segment都会起对应的线程)。
缺点是每个DN都保留了表的完整数据,造成数据的冗余。
101CREATE TABLE CUSTOMER_REPLICATION2(3 CUST_CODE bigint,4 CUST_NAME varchar(64),5 INT_ORG int,6 CUST_ATTR char(1),7 UPD_TIME TIMESTAMP,8 primary KEY(CUST_CODE)9) distribute by replication;10
第04章_数据操作
第一节 数据修改
1. 数据插入
91-- 批量插入2openGauss=# INSERT INTO customer_t1 (c_customer_sk, c_customer_id, c_first_name,Amount) VALUES 3 (6885, 'maps', 'Joes',2200),4 (4321, 'tpcds', 'Lily',3000),5 (9527, 'world', 'James',5000);6
7-- 插入重复行8INSERT INTO t3 (col3_a,col3_b) VALUES (1,3) ON DUPLICATE KEY update NOTHING;9
2. 数据合并
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DatabaseOMGuide/使用合并方式更新和插入数据.html
81MERGE INTO newproducts np 2USING products p 3ON (np.product_id = p.product_id ) 4WHEN MATCHED THEN 5 UPDATE SET np.product_name = p.product_name, np.category = p.category 6WHEN NOT MATCHED THEN 7 INSERT VALUES (p.product_id, p.product_name, p.category) ; 8
3. 表复制
131-- 方式一2INSERT INTO customer_t_copy (SELECT * FROM customer_t);3
4-- 方式二5CREATE TABLE customer_t_copy (LIKE customer_t);6INSERT INTO customer_t_copy (SELECT * FROM customer_t);7
8-- 方式三9CREATE TEMP TABLE customer_t_temp AS SELECT * FROM customer_t;10TRUNCATE customer_t;11INSERT INTO customer_t (SELECT * FROM customer_t_temp);12DROP TABLE customer_t_temp;13
第二节 数据查询
21-- Json查询2 SELECT json_extract_path_text(json(c_json), 'f4','f6') from test;
第三节 内置函数
1. 数值函数
2. 字符串函数
121
2-- 2. 字符串连接3select concat('aaaa', concat('bbbb', 'cccc')) 字符串连接 from dual;4select concat('aaaa', 'bbbb', 'cccc') 字符串连接 from dual;5select 'aaaa' || 'bbbb' || 'cccc' 字符串连接 from dual; -- 也可以用连接符||来实现6
7-- 6. 字符长度(汉字占一个字符)8select length('中国abc') 字符数 from dual; -- Oracle/Gauss集中式-PG兼容返回5,Mysql返回79
10-- 7. 字节长度(汉字占两个字节)11select lengthb('中国abc') 字节数 from dual; -- Oracle(GBK)返回7,Mysql不支持,Gauss集中式-PG兼容(UTF8)返回912
3. 日期时间函数
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/BriefTutorial/时间-日期函数和操作符.html
301-- 1. 当前日期时间2SELECT CURRENT_DATE 当前日期01, -- 2023-12-19 3 SYSDATE 当前日期02, -- 2023-12-19 19:50:334 CURRENT_TIMESTAMP 当前日期时间01, -- 2023-12-19 19:50:335 -- 不支持SYSTIMESTAMP6 LOCALTIMESTAMP 本地化日期时间 FROM DUAL; -- 2023-12-19 19:50:337
8-- 2. 日期时间差9-- 实际测试发现并不支持?10SELECT TIMESTAMPDIFF(YEAR, '2018-01-01', '2020-01-01') 相差年, TIMESTAMPDIFF(QUARTER, '2018-01-01', '2020-01-01') 相差季度, 11 TIMESTAMPDIFF(MONTH, '2018-01-01', '2020-01-01') 相差月份, TIMESTAMPDIFF(WEEK, '2018-01-01', '2020-01-01') 相差星期, 12 TIMESTAMPDIFF(DAY, '2018-01-01', '2020-01-01') 相差天, TIMESTAMPDIFF(HOUR, '2020-01-01 10:10:10', '2020-01-01 11:11:11') 相差时,13 TIMESTAMPDIFF(MINUTE, '2020-01-01 10:10:10', '2020-01-01 11:11:11') 相差分, TIMESTAMPDIFF(SECOND, '2020-01-01 10:10:10', '2020-01-01 11:11:11') 相差秒,14 TIMESTAMPDIFF(MICROSECOND, '2020-01-01 10:10:10.000000', '2020-01-01 10:10:10.111111') 相差毫秒 FROM DUAL;15
16-- 3. 提取年月日时分秒17SELECT EXTRACT(YEAR FROM LOCALTIMESTAMP) 年, EXTRACT(MONTH FROM LOCALTIMESTAMP) 月, EXTRACT(DAY FROM LOCALTIMESTAMP) 日, EXTRACT(HOUR FROM LOCALTIMESTAMP) 时, EXTRACT(MINUTE FROM LOCALTIMESTAMP) 分, EXTRACT(SECOND FROM LOCALTIMESTAMP) 秒 FROM DUAL;18
19
20-- 相差天数21select to_char(to_date(20240701, 'YYYYMMDD') - to_date(20230701, 'YYYYMMDD'));22
23-- 相差秒数24select to_number(to_char(now() - to_timestamp(orderdate || substring(opertime, 1,6), 'YYYYMMDDHH24MISS')))*86400 -- 推荐25select extract('epoch' from now()) - extract('epoch' from timestamp with time zone '2024-06-27 14:17:00'); -- 参数2为本地时区26select extract('epoch' from now()) - extract('epoch' from timestamp '2024-06-27 13:56:58'); -- 参数2为UTC时区27
28-- 间隔秒数29select extract('epoch' from interval '0 years 0 mons 5 days 0 hours 0 mins 0.00 secs');30
4. 类型转换函数
281-- 1. 数值转字符串2-- 注:NTOM后无¥标识3SELECT TO_CHAR(123456.789) NTOC, TO_CHAR(123456.789,'L999,999.000') NTOM FROM DUAL; -- 123456.789 123,456.7894
5-- 2. 字符串转数值6SELECT TO_NUMBER('123456.789') CTON, TO_NUMBER('¥123,456.789','L999,999.000') MTON FROM DUAL; -- 123456.789 7
8-- 3. 日期转字符串9SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD') FROM DUAL; -- 2023-09-2210
11-- 4. 字符串转日期12SELECT TO_DATE('2023-09-22', 'YYYY-MM-DD') FROM DUAL;13
14-- 5. 时间戳转字符串15SELECT TO_CHAR(CURRENT_TIMESTAMP, 'YYYY-MM-DD HH24:MI:SS.FF6') FROM DUAL; -- 2023-09-22 16:30:08.16300016
17-- 6. 字符串转时间戳18-- 字符串形式的时间不支持毫秒数19SELECT TO_TIMESTAMP('2023-12-19 19:43:18', 'YYYY-MM-DD HH24:MI:SS.FF6') FROM DUAL; -- OK20SELECT TO_TIMESTAMP('2023-09-22 16:30:08.163000', 'YYYY-MM-DD HH24:MI:SS.FF6') FROM DUAL; -- ERROR21
22-- 7. ASCII码和CHAR转换23SELECT ASCII('a'),CHR(97) FROM DUAL;24
25-- 扩展:把Unix纪元转换为时间戳26SELECT to_timestamp(1284352323); -- 2010-09-13 12:32:03+0827
28
5. 滤空函数
111-- 1. NULL值转换函数2-- NVL:若expr1为空值,则转换为expr2(支持日期、数字、字符串)3-- 不支持NVL2:若expr1为空值,转换为expr3,否则转换为expr24SELECT NVL(NULL,'Default') 空值 FROM DUAL; -- Default 5
6-- 2. 滤空函数7SELECT COALESCE(NULL,NULL,1,2) 滤空 FROM DUAL; -- 返回参数列表中第一个不为空的expr8
9-- 3. 等值判断函数10SELECT NULLIF('A','A') 相等返回NULL, NULLIF('A','B') 不相等返回A FROM DUAL; -- 若expr1与expr2相等,则返回NULL,不等返回expr1(注意:expr1不能为NULL)11
第05章_性能优化
第一节 优化思路概述
1. 影响性能因素
一般影响数据库性能的因素有以下几类:
硬件:服务器、存储、网络
系统规模:并发、数据量
数据库内部因素:索引、数据类型、统计信息等
软件环境:操作系统及参数配置
2. 性能瓶颈分类
性能问题通常是由某种特定资源的过度使用导致的,而这种过度使用的资源就是这个系统的瓶颈。数据库服务器常见的性能瓶颈问题主要是由CPU、内存、I/O和网络资源使用情况造成的。
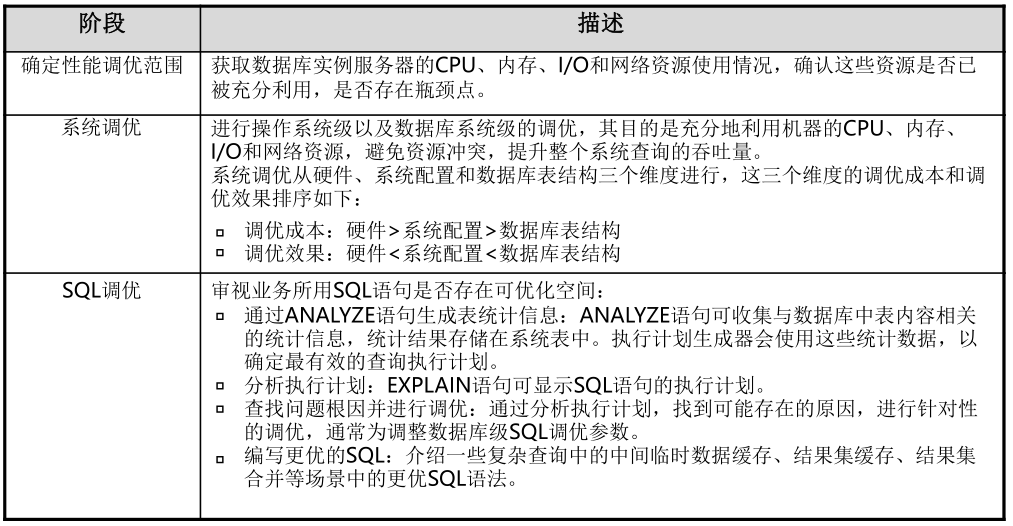
3. 性能调优流程
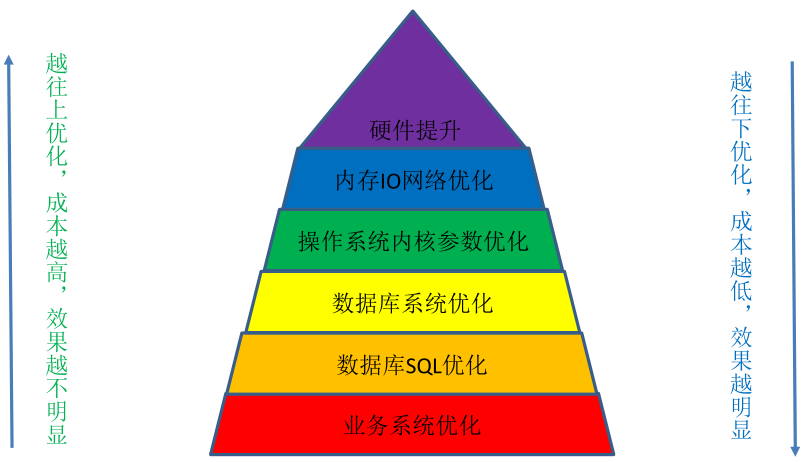
4. 性能优化方法论
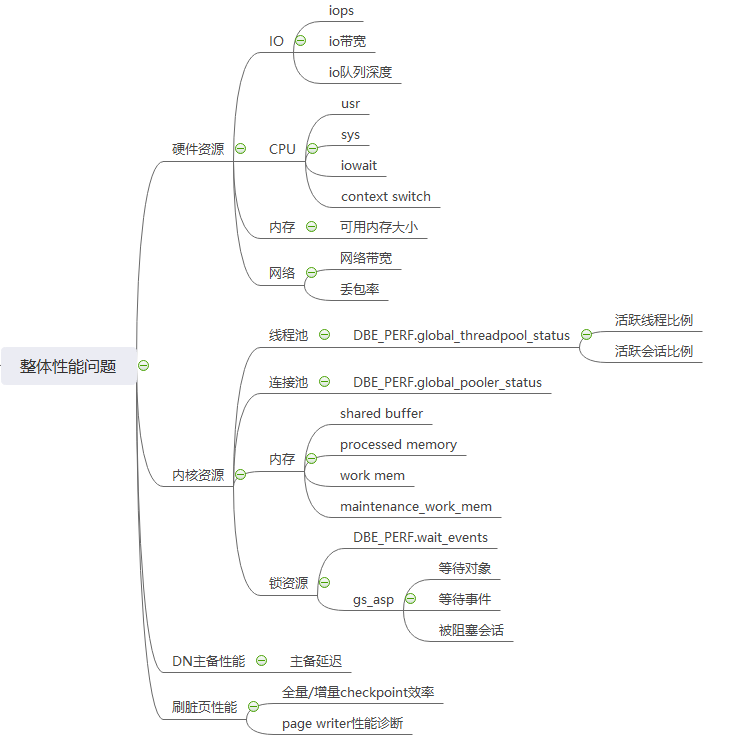
5. 整体信息问题分析概览
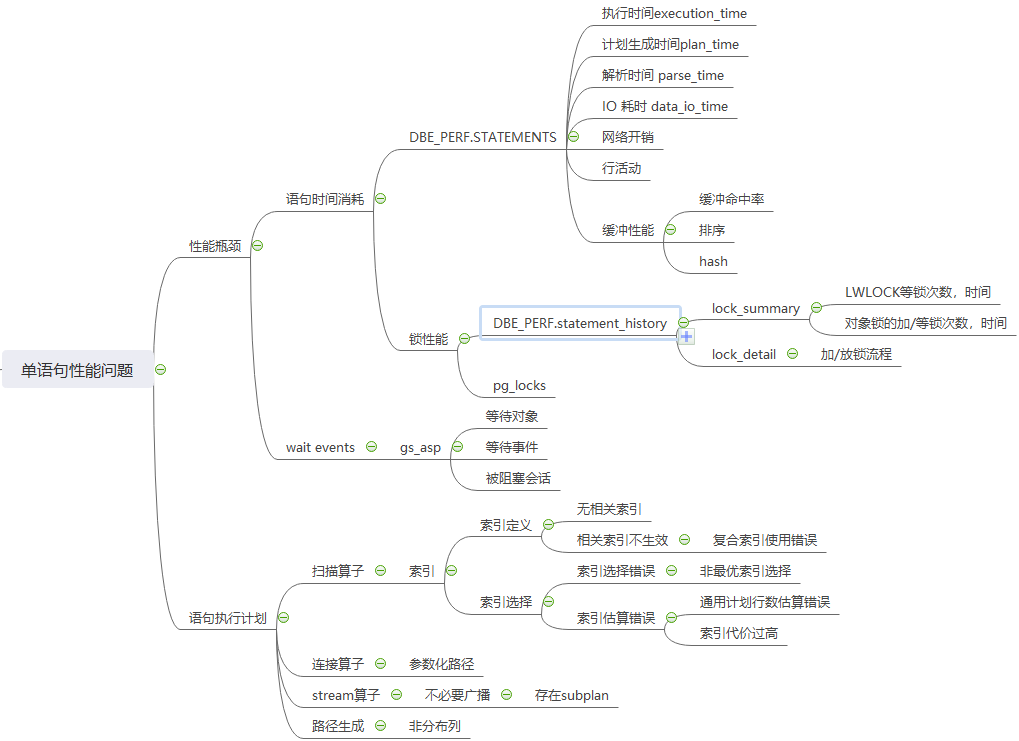
6. 单语句性能问题概览
第二节 统计信息
1. 会话信息
121-- 查询会话信息2SELECT * FROM pg_stat_activity;3-- 查询会话信息中的线程启动时间、事务启动时间、SQL启动时间以及状态变更时间4SELECT backend_start,xact_start,query_start,state_change FROM pg_stat_activity;5
6-- 查询当内存占用最多的会话信息7SELECT * FROM pv_session_memory_detail() ORDER BY usedsize desc limit 10;8
9-- 从当前活动会话视图查找问题会话的线程ID,并结束线程10SELECT datid, pid, state, query FROM pg_stat_activity; 11SELECT pg_terminate_backend(139834762094352);12
2. 连接信息
121-- 查看连接数2-- 最大允许连接数可通过 SHOW max_connections 查看3-- 增加连接数:gs_guc set -D /gaussdb/data/dbnode -c "max_connections= 800"4-- 重启后生效:gs_om -t stop && gs_om -t start5SELECT count(*) FROM (SELECT pg_stat_get_backend_idset() AS backendid) AS s;6
7-- 查询空闲连接8SELECT * FROM pg_stat_activity where state='idle' order by state_change;9
10-- 是否空闲连接(参数为上一步查询的pid字段)11SELECT pg_terminate_backend(140390132872976);12
3. 表统计信息
91-- 查询表的统计信息2SELECT * FROM pg_statistic;3
4-- 收集数据库相关的统计信息5ANALYZE USERS;6
7-- 回收空间并更新统计信息8VACUUM USERS;9
4. 慢SQL信息
221-- 慢SQL:注意SQL日志级别track_stmt_stat_level和慢SQL判断时间log_min_duration_statement2-- 仅有管理员可执行3-- 查看数据库实例中SQL语句执行信息4select * from DBE_PERF.get_global_full_sql_by_timestamp('2020-12-01 09:25:22', '2020-12-31 23:54:41');5-- 查看数据库实例中慢SQL语句执行信息6select * from DBE_PERF.get_global_slow_sql_by_timestamp('2020-12-01 09:25:22', '2020-12-31 23:54:41');7-- 查看当前主节点SQL语句执行信息8select * from statement_history;9-- 查看当前备节点SQL语句执行信息10select * from dbe_perf.standby_statement_history(true, '2022-08-01 09:25:22', '2022-08-31 23:54:41');11
12-- 查询数据库中长时间运行的SQL语句13-- 注:timestampdiff函数仅在openGauss兼容MY类型时(即dbcompatibility = 'B')有效14SELECT timestampdiff(minutes, query_start, current_timestamp) AS runtime, datname, usename, query 15 FROM pg_stat_activity WHERE state != 'idle' ORDER BY 1 desc;16
17-- 查询SQL语句状态18SELECT datname, usename, state, query FROM pg_stat_activity; 19
20-- 查询阻塞状态下的语句21SELECT datname, usename, state, query FROM pg_stat_activity WHERE waiting = true;22
5. 分片倾斜信息
21SELECT nodenameAS node_name, pg_xlog_location_diff(sender_flush_location, receiver_replay_location)2 FROM global_wal_sender_status;
第三节 执行计划
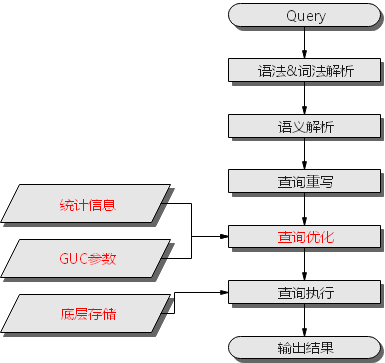
1. SQL执行流程
| 步骤 | 说明 |
|---|---|
| 语法&词法解析 | 按照约定的SQL语句规则,把输入的SQL语句从字符串转化为格式化结构(Stmt)。 |
| 语义解析 | 将“语法&词法解析”输出的格式化结构转化为数据库可以识别的对象。 |
| 查询重写 | 根据规则把“语义解析”的输出等价转化为执行上更为优化的结构。 |
| 查询优化 | 根据“查询重写”的输出和数据库内部的统计信息规划SQL语句具体的执行方式,也就是执行计划。 |
| 查询执行 | 根据“查询优化”规划的执行路径执行SQL查询语句。底层存储方式的选择合理性,将影响查询执行效率。 |
2. 获取执行计划
151-- 生成执行计划2EXPLAIN 3SELECT A.CUST_CODE, B.USER_NAME FROM CUSTOMER A, USERS B WHERE A.CUST_CODE = B.USER_CODE;4Nested Loop (cost=0.00..9.59 rows=4 width=24)5 -> Index Scan using users_pkey on users b (cost=0.00..3.35 rows=4 width=24)6 -> Index Only Scan using customer_pkey on customer a (cost=0.00..1.55 rows=1 width=8)7 Index Cond: (cust_code = b.user_code)8 9-- 生成执行计划并执行SQL10-- 显示中加入了实际的运行时间统计,包括在每个规划节点内部花掉的总时间(以毫秒计)和它实际返回的行数11EXPLAIN ANALYZE statement12
13-- 生成执行计划并执行SQL,显示执行期间的全部信息14EXPLAIN PERFORMANCE statement;15
3. 执行计划详解
1) 简单示例
以如下SQL语句为例:
11SELECT * FROM t1, t2 WHERE t1.c1 = t2.c2;执行EXPLAIN的输出为:

第一层:Seq Scan on t2
表扫描算子,用Seq Scan的方式扫描表t2。这一层的作用是把表t2的数据从buffer或者磁盘上读上来输送给上层节点参与计算。
第二层:Hash
Hash算子,作用是把下层计算输送上来的算子计算hash值,为后续hash join操作做数据准备。
第三层:Seq Scan on t1
表扫描算子,用Seq Scan的方式扫描表t1。这一层的作用是把表t1的数据从buffer或者磁盘上读上来输送给上层节点参与hash join计算。
第四层:Hash Join
join算子,主要作用是将t1表和t2表的数据通过hash join的方式连接,并输出结果数据。
2) 表访问方式
Seq Scan:全表顺序扫描。
Index Scan:索引扫描。
Bitmap Index Scan:使用位图索引抓取数据页。
Index Scan using index_name:简单索引扫描。
3) 表连接方式
Nested Loop:嵌套循环连接,适用于被连接的数据子集较小的查询。尽量把返回子集较小的表作为外表,而且在内表的连接字段上建议要有索引。
(Sonic) Hash Join:哈希连接,适用于数据量大的表的连接方式。优化器使用两个表中较小的表,利用连接键在内存中建立hash表,然后扫描较大的表并探测散列,找到与散列匹配的行。
Merge Join:归并连接,通常情况下执行性能差于哈希连接。如果源数据已经被排序过,在执行融合连接时,并不需要再排序,此时融合连接的性能优于哈希连接。
4) 运算符
sort:对结果集进行排序。
filter:WHERE子句当作一个“filter”条件附属于顺序扫描计划节点。这会为它扫描的每一行检查该条件,并且只输出符合条件的行。
LIMIT:限定了执行结果的输出记录数。如果增加了LIMIT,那么不是所有的行都会被检索到。
4. 执行信息简介
以如下SQL语句为例:
11select sum(t2.c1) from t1,t2 where t1.c1=t2.c2 group by t1.c2;执行EXPLAIN PERFORMANCE输出为:

第四节 调优方法
1. 更新统计信息
61-- 更新单个表的统计信息2ANALYZE tablename; 3
4-- 更新全库的统计信息5ANALYZE; 6
2. 关键参数调整
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/PerformanceTuningGuide/操作系统参数调优.html
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/PerformanceTuningGuide/SQL调优关键参数调整.html
3. SQL编写建议
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/DeveloperGuide/SQL编写.html
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/PerformanceTuningGuide/经验总结-SQL语句改写规则.html
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/PerformanceTuningGuide/典型SQL调优点.html
注意:
concat()和now()等函数生成的执行计划无法下推,会导致查询性能严重劣化。
4. 实际调优案例
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/PerformanceTuningGuide/实际调优案例.html
第五节 Plan Hint
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/PerformanceTuningGuide/使用Plan-Hint进行调优.html
1. Plan Hint简介
Plan Hint是特殊SQL语法,可用于手工干预SQL执行计划的选择,在SQL中加入hint语法,可以明确指导SQL优化器选择特定执行计划。
Plan Hint通常用于明确知道SQL的最优执行计划或者用于稳定SQL执行计划,达到性能调优效果。
4. 简单示例
131-- 语法格式2SELECT /*+[hint](value) */ * FROM …3SELECT /*+[hint](value) [hint](value) */ * FROM …4
5-- 使用示例6EXPLAIN7SELECT /*+ tablescan(t1) */t1.a FROM t1 WHERE t1.a = 1;8
9-- 其他示例10/*+ [no] tablescan(table) */ -- 禁用或使用顺序扫描11/*+ [no] indexscan/indexonlyscan(table index) */ -- 禁用或使用索引/只索引扫描12/*+ [no] nestloop/hashjoin/mergejoin(table1 table2) */ -- 禁用或使用连接方式(多表连接时,只对对后一次join生效)13/*+ leading(t1 (t2 t3)) */ -- t2与t3表先进行join,再和t1进行join
第六节 分布式优化
1. 分布式执行流程
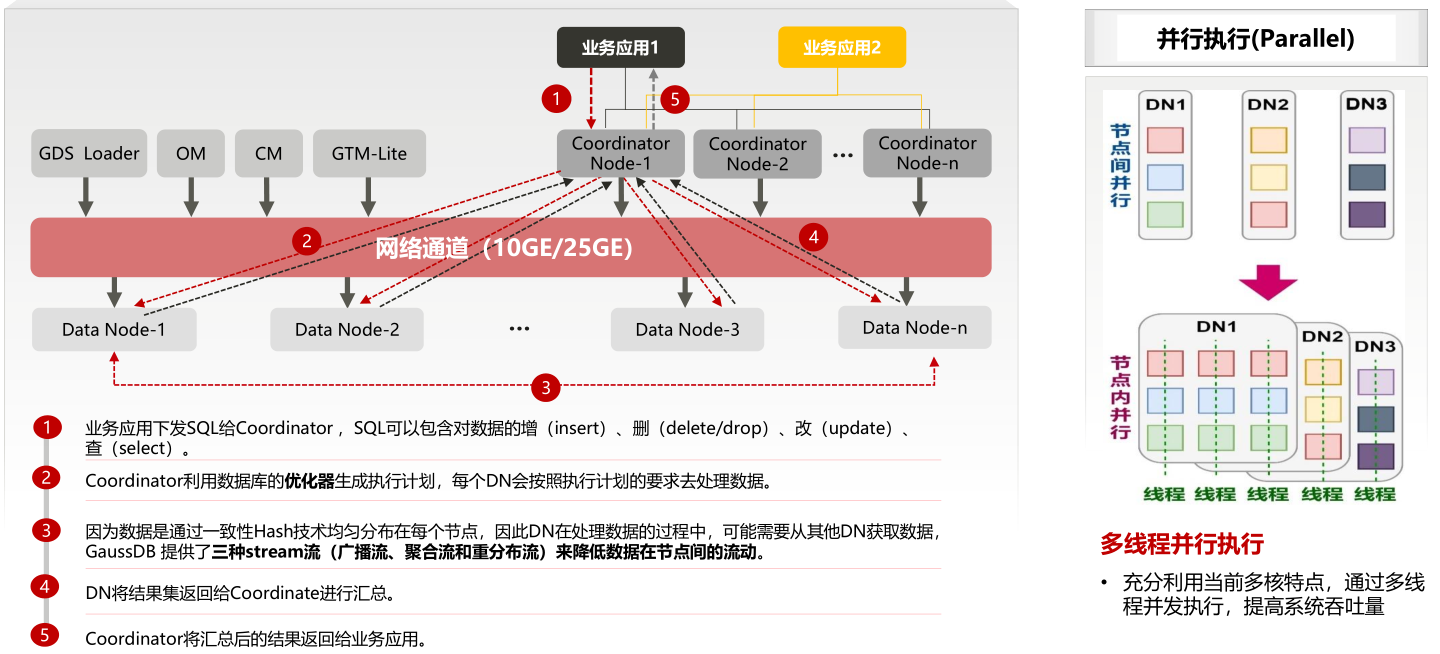
2. 分布式优化思路
算子尽量向数据端下推: 针对SQL语句的算子,尽量把大量的算子下推到DN上执行,CN上执行的算子越少越好。
减少一个SQL语句的跨节点执行:指定分布键过滤条件,SQL语句可下推到单DN执行,节省网络开销,减少CN汇总消耗。
减少分布式事务:
指定分布键过滤条件,事务只涉及到单DN执行,事务可以在本地提交,节省分布式事务管理开销。
业务流程适配修改,规避分布式事务。
减少数据重分布:
选择关联字段或聚合字段做分布列,以减少跨节点数据分布。
通过数据的冗余设计,以减少跨节点数据分布。
避免数据倾斜,满足各节点对等均衡要求:选择合理的分布列,减少数据倾斜。
3. 分布式执行计划
1) REMOTE_FQS_QUERY
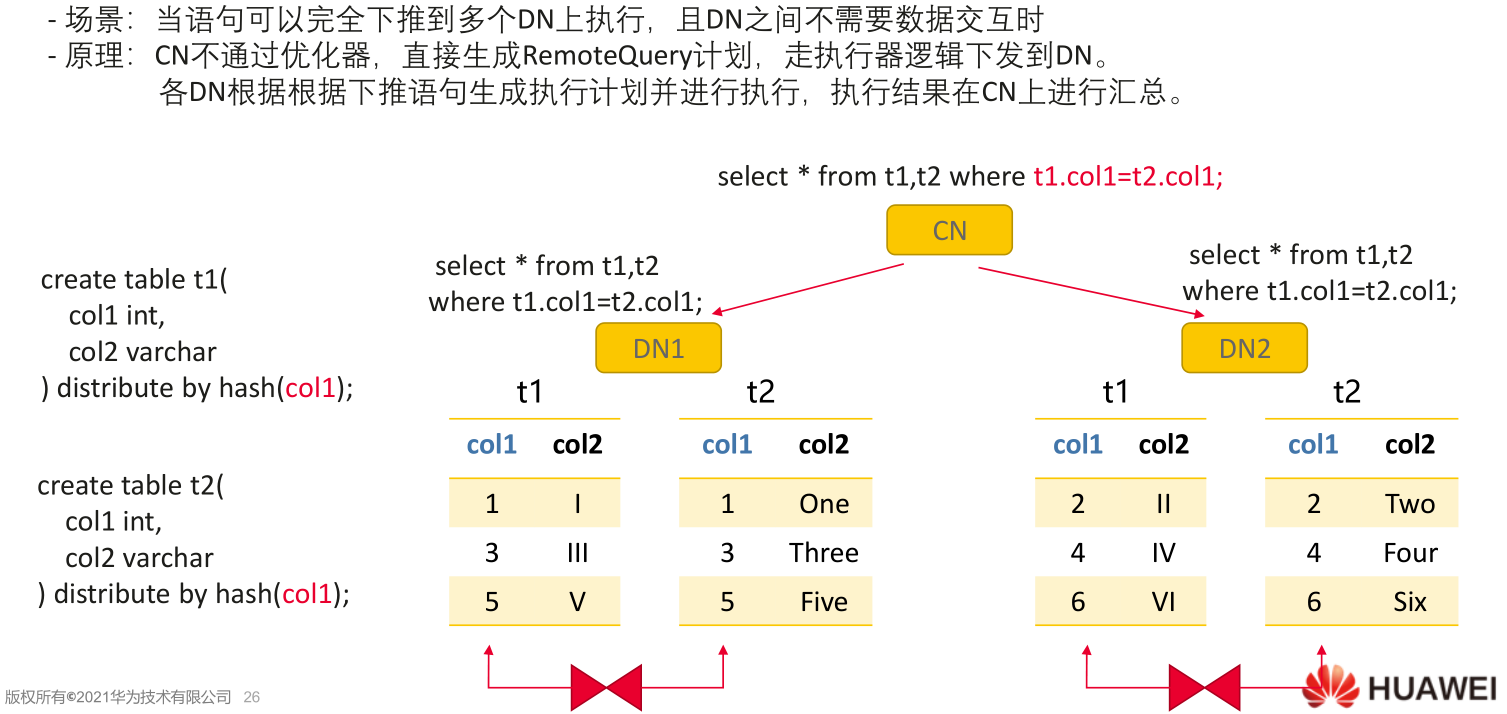
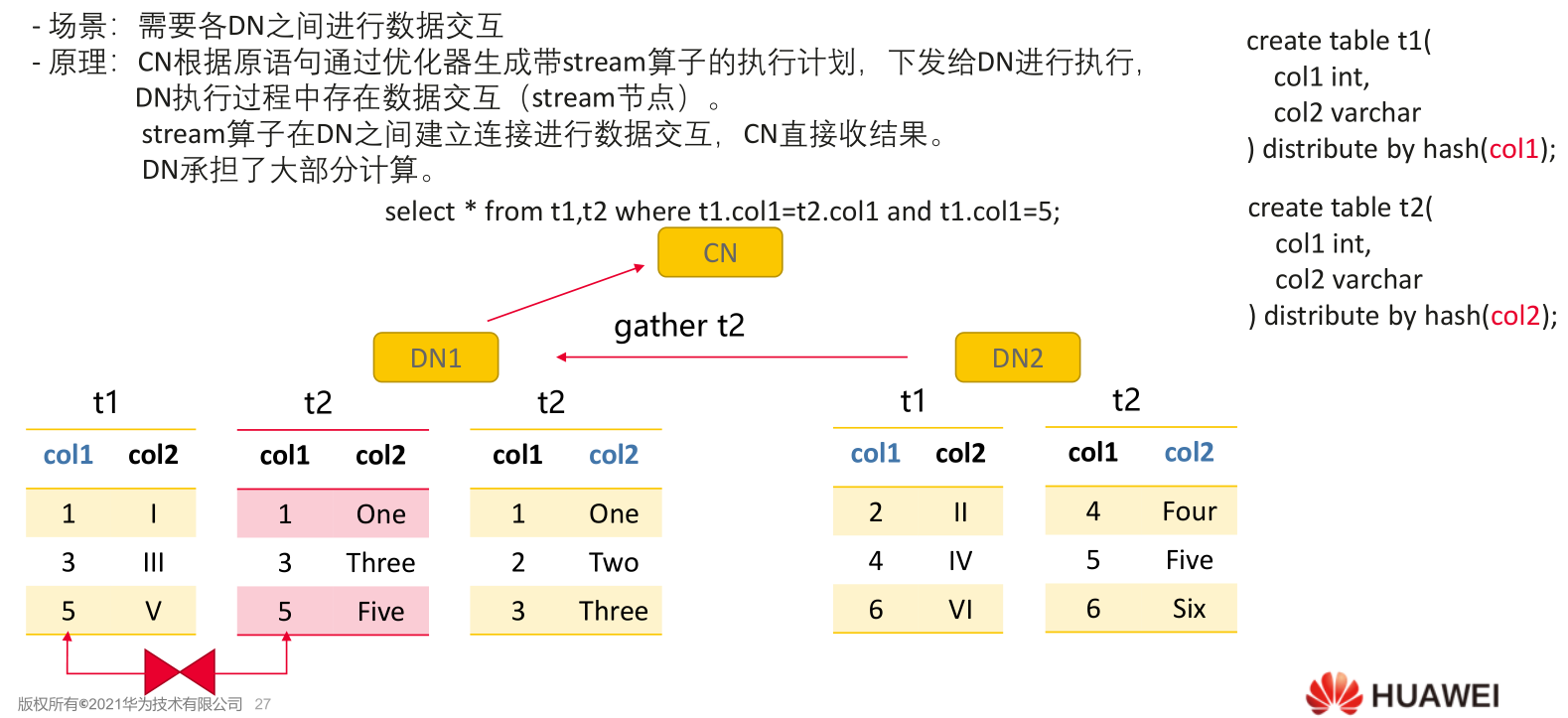
2) STREAM GATHER
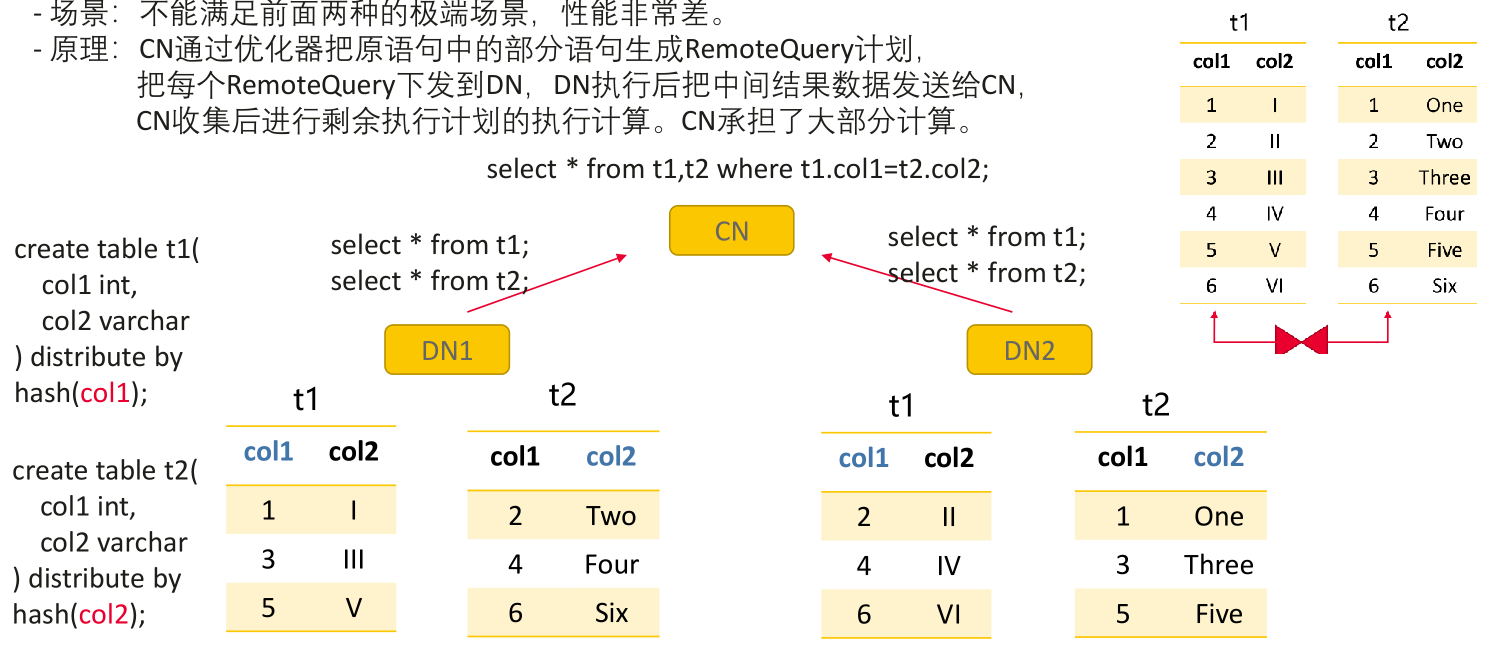
3) PGXC
第06章_过程操作
第一节 存储过程
1. 存储过程简介
241-- 创建表格2openGauss=# CREATE TABLE graderecord 3( 4 number INTEGER, 5 name CHAR(20), 6 class CHAR(20), 7 grade INTEGER8);9
10-- 定义存储过程11openGauss=# CREATE PROCEDURE insert_data (param1 INT = 0, param2 CHAR(20),param3 CHAR(20),param4 INT = 0 ) 12IS13 BEGIN 14 INSERT INTO graderecord VALUES(param1,param2,param3,param4); 15END;16/17
18
19-- 调用存储过程20openGauss=# CALL insert_data(param1:=210101,param2:='Alan',param3:='21.01',param4:=92);21
22-- 删除存储过程23openGauss=# DROP PROCEDURE insert_data;24
第二节 存储函数
1. 存储函数简介
第三节 触发器
1. 事件触发器(DDL触发器)
事件触发器会在指定的ddl事件发生时自动执行函数,目前仅在PG兼容模式下可用。
641-- https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/BriefTutorial/%E4%BA%8B%E4%BB%B6%E8%A7%A6%E5%8F%91%E5%99%A8.html2
3-- 创建事件触发器函数(用于ddl_command_start、ddl_command_end事件)4openGauss=# create function test_event_trigger() returns event_trigger as $$5BEGIN6 RAISE NOTICE 'test_event_trigger: % %', tg_event, tg_tag;7END8$$ language plpgsql;9
10-- 创建事件触发器函数(用于sql_drop事件)11openGauss=# CREATE OR REPLACE FUNCTION drop_sql_command()12RETURNS event_trigger AS $$13BEGIN14RAISE NOTICE '% - sql_drop', tg_tag;15END;16$$ LANGUAGE plpgsql;17
18-- 创建事件触发器函数(用于table_rewrite事件)19openGauss=# CREATE OR REPLACE FUNCTION test_evtrig_no_rewrite() RETURNS event_trigger20LANGUAGE plpgsql AS $$21BEGIN22 RAISE EXCEPTION 'rewrites not allowed';23END;24$$;25
26-- 创建事件类型为ddl_command_start的事件触发器27openGauss=# create event trigger regress_event_trigger on ddl_command_start28 execute procedure test_event_trigger();29
30-- 创建事件类型为ddl_command_end的事件触发器31openGauss=# create event trigger regress_event_trigger_end on ddl_command_end32 execute procedure test_event_trigger();33
34-- 创建事件类型为sql_drop的事件触发器35openGauss=# CREATE EVENT TRIGGER sql_drop_command ON sql_drop36 EXECUTE PROCEDURE drop_sql_command();37
38-- 创建事件类型为table_rewrite的事件触发器39openGauss=# create event trigger no_rewrite_allowed on table_rewrite40 when tag in ('alter table') execute procedure test_evtrig_no_rewrite();41
42-- 执行ddl语句查看事件触发器效果(触发ddl_command_start与ddl_command_end)43openGauss=# create table event_trigger_table (a int);44
45-- 执行alter table语句查看事件触发器效果(触发ddl_command_start与table_rewrite,ddl_command_end由于禁止rewrite报错不触发)46openGauss=# alter table event_trigger_table alter column a type numeric;47
48-- 执行drop语句查看事件触发器效果(触发ddl_command_start、sql_drop与ddl_command_end)49openGauss=# drop table event_trigger_table;50
51-- 修改事件触发器52openGauss=# create role regress_evt_user WITH ENCRYPTED PASSWORD 'EvtUser123';53openGauss=# ALTER EVENT TRIGGER regress_event_trigger RENAME TO regress_event_trigger_start;54-- 应该失败,事件触发器的owner只能为超级用户55openGauss=# ALTER EVENT TRIGGER regress_event_trigger_start owner to regress_evt_user;56openGauss=# ALTER EVENT TRIGGER regress_event_trigger_start disable;57openGauss=# ALTER EVENT TRIGGER regress_event_trigger_start enable always;58
59-- 删除事件触发器60openGauss=# DROP EVENT TRIGGER regress_event_trigger_start;61openGauss=# DROP EVENT TRIGGER regress_event_trigger_end;62openGauss=# DROP EVENT TRIGGER sql_drop_command;63openGauss=# DROP EVENT TRIGGER no_rewrite_allowed;64
2. 数据变更触发器(DML触发器)
751-- https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/BriefTutorial/%E8%A7%A6%E5%8F%91%E5%99%A8.html2
3-- 创建源表及触发表4CREATE TABLE test_trigger_src_tbl(id1 INT, id2 INT, id3 INT);5CREATE TABLE test_trigger_des_tbl(id1 INT, id2 INT, id3 INT);6
7-- 创建触发器函数8CREATE OR REPLACE FUNCTION tri_insert_func() RETURNS TRIGGER AS9 $$10 DECLARE11 BEGIN12 INSERT INTO test_trigger_des_tbl VALUES(NEW.id1, NEW.id2, NEW.id3);13 RETURN NEW;14 END15 $$ LANGUAGE PLPGSQL;16
17CREATE OR REPLACE FUNCTION tri_update_func() RETURNS TRIGGER AS18 $$19 DECLARE20 BEGIN21 UPDATE test_trigger_des_tbl SET id3 = NEW.id3 WHERE id1=OLD.id1;22 RETURN OLD;23 END24 $$ LANGUAGE PLPGSQL;25
26CREATE OR REPLACE FUNCTION TRI_DELETE_FUNC() RETURNS TRIGGER AS27 $$28 DECLARE29 BEGIN30 DELETE FROM test_trigger_des_tbl WHERE id1=OLD.id1;31 RETURN OLD;32 END33 $$ LANGUAGE PLPGSQL;34
35-- 创建INSERT触发器36CREATE TRIGGER insert_trigger37 BEFORE INSERT ON test_trigger_src_tbl38 FOR EACH ROW39 EXECUTE PROCEDURE tri_insert_func();40
41-- 创建UPDATE触发器42CREATE TRIGGER update_trigger43 AFTER UPDATE ON test_trigger_src_tbl 44 FOR EACH ROW45 EXECUTE PROCEDURE tri_update_func();46
47-- 创建DELETE触发器48CREATE TRIGGER delete_trigger49 BEFORE DELETE ON test_trigger_src_tbl50 FOR EACH ROW51 EXECUTE PROCEDURE tri_delete_func();52
53-- 执行INSERT触发事件并检查触发结果54INSERT INTO test_trigger_src_tbl VALUES(100,200,300);55SELECT * FROM test_trigger_src_tbl;56SELECT * FROM test_trigger_des_tbl; //查看触发操作是否生效。57
58-- 执行UPDATE触发事件并检查触发结果59UPDATE test_trigger_src_tbl SET id3=400 WHERE id1=100;60SELECT * FROM test_trigger_src_tbl;61SELECT * FROM test_trigger_des_tbl; //查看触发操作是否生效62
63-- 执行DELETE触发事件并检查触发结果64DELETE FROM test_trigger_src_tbl WHERE id1=100;65SELECT * FROM test_trigger_src_tbl;66SELECT * FROM test_trigger_des_tbl; //查看触发操作是否生效67
68-- 修改触发器69ALTER TRIGGER delete_trigger ON test_trigger_src_tbl RENAME TO delete_trigger_renamed;70
71-- 删除触发器72DROP TRIGGER insert_trigger ON test_trigger_src_tbl;73DROP TRIGGER update_trigger ON test_trigger_src_tbl;74DROP TRIGGER delete_trigger_renamed ON test_trigger_src_tbl;75
附录
一、Gauss与Oracle差异对比
注:本对比中Gauss采用 V500R002C10 版本,Oracle采用 Oracle11.2.0.4 版本。
1. 基本特性差异
861-- 1. 标识符(表名和字段名等)大小写2Oracle:标识符默认大写。3Gauss :标识符默认小写。4
5-- 2. 事务自动提交6Oracle:默认手动提交。7Gauss :默认自动提交,可使用 start transaction 手动开启事务。8
9-- 3. 虚表(DUAL)10Oracle:初始库中存在虚表。11Gauss :需要手动创建虚表。12 CREATE OR REPLACE VIEW DUAL AS (SELECT 'X'::TEXT AS DUMMY);13 GRANT SELECT ON TABLE DUAL TO PUBLIC;14
15-- 4. 虚拟字段/虚拟列16Oracle:可以使用虚拟字段作为分区列,但不能对虚拟列进行insert和update。17Gauss :不可以使用虚拟字段作为分区列,且不能对虚拟列进行insert和update。18 create table t_virtual(c1 int,c2 int,v_c3 int GENERATED ALWAYS AS(c1 + c2) stored);19 create table t_virtual(c1 int,c2 int,v_c3 int GENERATED ALWAYS AS(c1 + c2));20 21-- 5. 自动分区22Oracle:支持自动创建分区,语法:INTERVAL (NUMTOYMINTERVAL(1, 'MONTH'))。23Gauss集中式:支持自动创建分区,语法:INTERVAL ('1 month')。24Gauss分布式:不支持自动创建分区,且不能在非分布键上创建分区。25
26-- 6. 查看执行计划27Oracle:explain sql。28Gauss :explain plan for sql。29
30-- 7. 插入重复行31Oracle:通过指定hint方式,略唯一约束冲突,回滚当前行,继续完成其他行的插入。32Gauss :通过特殊子句实现。33 INSERT /*+IGNORE_ROW_ON_DUPKEY_INDEX(t3,idx_t3_col3) */ INTO t3 (col3_a,col3_b) VALUES (1,3);34 INSERT INTO t3 (col3_a,col3_b) VALUES (1,3) ON DUPLICATE KEY update NOTHING;35 36-- 8. 序列调用方式37Oracle:只可以使用 select seq01.nextval from dual 方式调用。38Gauss :不仅可以使用上述方式调用,还可以使用 SELECT nextval('seq01') 方式调用。39
40-- 9. 关于四种不等于 != <> ! = < >41Oracle:上述四种不等于都和预期一致。42Gauss :不带空格的和预期一致。但 ! = 查询结果不正确,< >语法报错!43
44-- 10. 函数调用方式45Oracle:可以使用 CALL 和 exec 调用函数。46Gauss :只能使用 CALL 调用函数。47
48-- 11. 分页查询方式49select * from my_tables WHERE rownum<=3; -- Gauss集中式、Oracle50select * from my_tables limit 1; -- Gauss集中式、Gauss分布式51select * from my_tables limit 1,3; -- Gauss集中式、Gauss分布式52
53-- 12. 便捷类型转换54Oracle:不支持使用::进行类型转换55Gauss :select '2022-11-09'::timestamp56
57-- 13. 查询表的别名58Oracle:不支持在查询表和其别名之间添加as59Gauss :支持60
61-- 14. 创建序列语法62Oracle:不支持省略 start with 子句中的 with 。63Gauss :可将 start with 简写为 start 。64
65-- 15. 字符串与NULL拼接66Oracle和Gauss(Oracle兼容):select 'a'||null as a from dual; -- a67Gauss(PG兼容):select 'a'||null as a; -- 返回None68
69-- 16. 空字符串处理70Oracle和Gauss(Oracle兼容):将空字符串作为NULL处理,即 IS NULL 满足,但 = '' 不满足71Gauss(PG兼容):保留空字符串语义,即 IS NULL 不满足,但 = '' 满足72
73-- 17. CHAR(N)/VARCHAR(N)字符数和字节数差异74Oracle和Gauss(Oracle兼容):以字节为计数单位,CHAR(N)或VARCHAR2(N)可存储N/2或N/3个字符。75Gauss(PG兼容):以字符为计数单位,CHAR(N)或VARCHAR2(N)可存储N个字符。76注:两者都是英文占1个字节,中文占2个(GBK)或3个(UTF8)字节。77
78-- 18. NVARCHAR2(N)字符数和字节数差异79当使用UTF8编码时:都以字符计数,可以插入N个中文或N个英文字母,但Oracle中文和字母都占2个字节,而Gauss字母占1个字节,中文占3个字节80当使用GBK编码时:都以字节计数,可以插入N/2个中文或N个英文字母,但Oracle和Gauss(Oracle兼容)中文和字母都占2个字节,而Gauss(PG兼容)字母占1个字节,中文占3个字节。81
82-- 19. 将CHAR类型修改为VARCHAR类型时83Oracle:char类型字段值为空格,转换为varchar后还是空格。84Gauss(ORACLE兼容):char类型字段值为空格,转换成varchar后变成了null。85Gauss(PG兼容):char类型字段值为空格,转换成varchar后变成了空字符串。86
2. 字段类型差异
91-- 1. 关于INTEGER类型2Oracle:是NUMBER的子类型,等同于NUMBER(38,0)。3Gauss :4字节长度,范围是 -2147483648 ~ 2147483647。4
5-- 2. 关于Date类型6Oracle:默认查询为 YYYY-MM-DD HH24:MI:SS 格式7Gauss集中式(ORACLE兼容):默认查询为 YYYY-MM-DD 格式8Gauss集中式(PG兼容):将被替换为 TIMESTAMP(0) WITHOUT TIME ZONE 类型9
3. 常用函数差异
251-- 取当前日期时间2Oracle:select SYSTIMESTAMP FROM DUAL;3Gauss :select sysdate;4
5-- 字符串转日期6Oracle:select to_timestamp_TZ('22-11-07 11.23.43.033','YY-MM-DD HH24.mi.SS.FF');7Gauss :select to_timestamp('22-11-07 11.23.43.033','YY-MM-DD HH24.mi.SS.FF');8
9-- 哈希值10Oracle:select ORA_HASH('hello');11Gauss :select hashbpchar('hello');12
13-- MOD(1,0)函数差异14Oracle和Gauss(Oracle兼容):当除数为0时,返回被除数15Gauss(PG兼容):报错16
17-- TO_NUMBER/TO_DATE函数差异18Oracle和Gauss(Oracle兼容):被转换的值为空字符串时,返回NULL19Gauss(PG兼容):报错20
21-- TO_TIMESTAMP函数差异22Oracle和Gauss(Oracle兼容):被转换的值为空字符串时,返回NULL23Gauss(PG兼容):返回0001-01-01 00:00:00.00024
25
4. GaussDB分布式功能限制
71-- 1. 关于数据分布21) 创建表时需指定分布键,否则将采用主键或第一列作为分布键。32) 分布键的值在插入时确定,之后不可以通过UPDATE进行修改。43) 创建唯一索引时,必须包含所有分布键。53) 分片表不支持外键约束。64) 不支持自动创建分区,且不能在非分布键上创建分区。7
二、应用开发简介
1. 安装驱动
安装Jar包
mvn install:install-file -Dfile=./postgresql.jar -DgroupId=org.opengauss -DartifactId=opengauss-jdbc -Dversion=2.0.0 -Dpackaging=jar
171D:\KingDom\SourceCode\kfms-java\2.DevelopmentDoc\2.4Design\2.4.1Overall\第三方文档\Gauss>mvn install:install-file -Dfile=./postgresql.jar -DgroupId=org.opengauss -DartifactId=opengauss-jdbc -Dversion=2.0.0 -Dpackaging=jar2[INFO] Scanning for projects...3[INFO]4[INFO] ------------------< org.apache.maven:standalone-pom >-------------------5[INFO] Building Maven Stub Project (No POM) 16[INFO] --------------------------------[ pom ]---------------------------------7[INFO]8[INFO] --- maven-install-plugin:2.4:install-file (default-cli) @ standalone-pom ---9[INFO] Installing D:\KingDom\SourceCode\kfms-java\2.DevelopmentDoc\2.4Design\2.4.1Overall\第三方文档\Gauss\postgresql.jar to C:\Users\Administrator\.m2\repository\org\opengauss\opengauss-jdbc\2.0.0\opengauss-jdbc-2.0.0.jar10[INFO] Installing C:\Users\ADMINI~1\AppData\Local\Temp\mvninstall4432540172902929680.pom to C:\Users\Administrator\.m2\repository\org\opengauss\opengauss-jdbc\2.0.0\opengauss-jdbc-2.0.0.pom11[INFO] ------------------------------------------------------------------------12[INFO] BUILD SUCCESS13[INFO] ------------------------------------------------------------------------14[INFO] Total time: 0.455 s15[INFO] Finished at: 2022-04-29T16:32:53+08:0016[INFO] ------------------------------------------------------------------------17
导入Jar包
101<dependency>2 <groupId>org.opengauss</groupId>3 <artifactId>opengauss-jdbc</artifactId>4 <version>2.0.1-compatibility</version>5</dependency>6<dependency>7 <groupId>org.postgresql</groupId>8 <artifactId>postgresql</artifactId>9 <version>42.2.2</version>10</dependency>
2. mybatis-config.xml
281 2 4 5<configuration>6 <environments default="pgsql">7 <environment id="pgsql">8 <transactionManager type="JDBC"></transactionManager>9 <dataSource type="POOLED">10 <property name="driver" value="org.postgresql.Driver"/>11 <property name="url" value="jdbc:postgresql://10.203.60.3:8123/kcia"/>12 <property name="username" value="kciauser"/>13 <property name="password" value="SZtest898"/>14 </dataSource>15 </environment>16 </environments>17
18 <databaseIdProvider type="DB_VENDOR">19 <property name="SQL Server" value="sqlserver"/>20 <property name="DB2" value="db2"/>21 <property name="Oracle" value="oracle" />22 <property name="PostgreSQL" value="pgsql" />23 </databaseIdProvider>24
25 <mappers>26 <package name="com.szkingdom.kfms.mapper"/>27 </mappers>28</configuration>