第02篇_Mysql
第01章_MySql概述
第一节 MySql简介
1. 什么是MySql?
MySQL是一个开源的关系型数据库管理系统(RDBMS) ,主要应用在互联网WEB领域。
发展历程简述如下:
1995 年,由瑞典 MySQL AB 公司开发(创始人Michael Widenius)。
2003 年,MySql发布4.0版本,与InnoDB引擎正式结合。
2008 年,被 Sun 公司收购。
2009 年,Sun 又被 Oracle 公司收购。
2010 年,MySql发布5.5版本,InnoDB引擎成为MySql的默认存储引擎。
2016 年9月,MySql发布里程碑版本MySql8.0.0。
扩展:
MySQL6.x 版本之后分为 社区版 和 商业版。
MySQL 的创造者担心 MySQL 有闭源的风险,因此创建了 MySQL 的分支项目 MariaDB。
第二节 安装部署
1. Windwos版本安装
详见部署文档!
2. Linux版本安装
详见部署文档!
3. 远程访问配置
x1-- 修改root用户权限2use mysql;3update user set Host='%' where User='root'; -- % 指的是所有地址4FLUSH PRIVILEGES; -- 刷新权限5
6-- 创建登录用户7create user 'hyx'@'%' identified by 'hyx123456';8
9-- 给登录用户授权10GRANT ALL PRIVILEGES ON [数据库名].[表名] TO '[用户名]'@'[连接地址]' WITH GRANT OPTION; -- 授予连接访问权限11GRANT SELECT, UPDATE, DELETE, INSERT ON dxg .* TO 'username'@'%' WITH GRANT OPTION; -- 授予操作增删改12FLUSH PRIVILEGES; -- 刷新权限13
4. 错误日志
错误日志默认存放在 /var/log/mysqld.log,记录了 mysqld 启动和停止,以及服务器在运行过程中产生的错误信息。
101mysql> show variables like '%log_error%';2+----------------------------+----------------------------------------+3| Variable_name | Value |4+----------------------------+----------------------------------------+5| binlog_error_action | ABORT_SERVER | 6| log_error | /var/log/mysqld.log |7| log_error_services | log_filter_internal; log_sink_internal |8| log_error_suppression_list | |9| log_error_verbosity | 2 |10+----------------------------+----------------------------------------+
第三节 客户端
1. 命令行客户端
131# 登录mysql2mysql -h 106.53.120.230 -P 3306 -u root -phyx123456 test013
4# 执行SQL命令(-e)5C:\Users\Administrator>mysql -h 106.53.120.230 -P 3306 -u root -pHyx147741 test01 -e "select * from stu"6Warning: Using a password on the command line interface can be insecure.7+----+-------+-----+8| id | name | age |9+----+-------+-----+10| 1 | tom | 1 |11+----+-------+-----+12C:\Users\Administrator>13
注意:
将MySql的bin路径(如:D:\MySql\mysql-8.0.22-winx64\bin)配置到
PATH变量。
2. 其它客户端
官方客户端:MySQL Workbench。
通用GUI客户端:SQLyog、DataGrip、Navicat、Dbeaver等。
第四节 体系结构
1. Mysql软件架构
1) 连接层:进行授权认证,提供连接线程等。
2) 服务层:解析SQL语句,进行语法和语义分析,生成执行计划,以及执行存储过程等一些跨存储引擎的功能。
3) 引擎层:负责数据的存储和提取,以及索引的维护。
4) 存储层:将数据(REDOLOG、UNDOLOG、BINLOG、数据块、索引、错误日志、查询日志、慢查询日志等)写入磁盘。
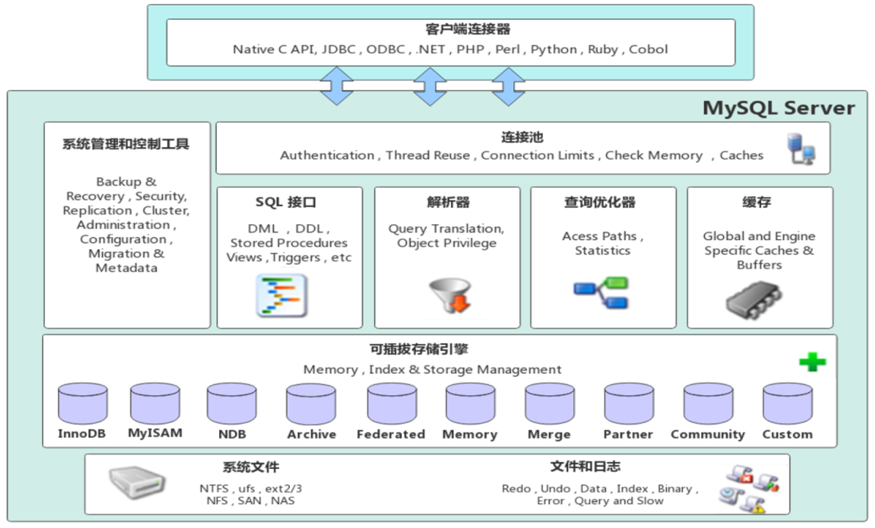
2. 存储引擎介绍
存储引擎是数据存储和提取的核心,插件式的存储引擎架构,使得MySql可以应用在多种不同场景中,并发挥良好作用。
1) 指定存储引擎
存储引擎是表级别的,也称为表类型,一般在创建表时指定,如未指定则为当前数据库的默认存储引擎。
241-- 查询当前数据库支持的存储引擎2SHOW ENGINES; 3+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+4| Engine | Support | Comment | Transactions | XA | Savepoints |5+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+6| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |7| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |8| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |9| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |10| MyISAM | YES | MyISAM storage engine | NO | NO | NO |11| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |12| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |13| CSV | YES | CSV storage engine | NO | NO | NO |14| ARCHIVE | YES | Archive storage engine | NO | NO | NO |15+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+16
17-- 创建表时指定存储引擎18CREATE TABLE MY_INNODB(ID INT, NAME VARCHAR(10)) ENGINE = InnoDB;19CREATE TABLE MY_MYISAM(ID INT, NAME VARCHAR(10)) ENGINE = MyISAM;20CREATE TABLE MY_MEMORY(ID INT, NAME VARCHAR(10)) ENGINE = Memory;21
22-- 查看某表的存储引擎23SHOW CREATE TABLE MY_MYISAM;24
2) 存储引擎特点
InnoDB:兼顾高可靠性和高性能的通用存储引擎,为 MySQL 5.5 之后的默认存储引擎。
MyIASM:MySQL早期的默认存储引擎
Memory:数据存储在内存中,由于受到硬件问题、或断电问题的影响,只能将这些表作为临时表或缓存使用。
| InnoDB | MyISAM | Memory | |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | ||
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 支持 | ||
| 全文索引 | 支持(5.6+) | 支持 | |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 并发访问速度 | 高 | 低 | 低 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | ||
| 存储文件 | xxx.ibd:表结构、数据、索引文件 (二进制数据,可通过 ibd2sdi提取表结构) | xxx.sdi:存储表结构信息 xxx.MYD:存储数据 xxx.MYI:存储索引 | xxx.sdi:存储表结构信息 |
3) 存储引擎选择
在选择存储引擎时,应根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,可以根据实际情况选择多种存储引擎进行组合:
InnoDB:如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
MyISAM: 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。
3. 二进制日志
二进制日志(BINLOG)记录了所有的 DDL语句和 DML语句,但不包括DQL语句,主要用于主从复制和灾难时的数据恢复。
121-- 查询BINLOG配置2mysql> show variables like '%log_bin%';3+---------------------------------+-----------------------------+4| Variable_name | Value |5+---------------------------------+-----------------------------+6| log_bin | ON | -- 是否打开7| log_bin_basename | /var/lib/mysql/binlog | -- 存放目录,以000001等序号拆分8| log_bin_index | /var/lib/mysql/binlog.index | -- 记录了当前服务器关联的binlog文件有哪些9| log_bin_trust_function_creators | OFF |10| log_bin_use_v1_row_events | OFF |11| sql_log_bin | ON |12+---------------------------------+-----------------------------+
1) BINLOG格式
MySQL服务器中提供了多种格式来记录二进制日志,具体格式及特点如下:
| 日志格式 | 含义 |
|---|---|
| STATEMENT | 基于SQL语句的日志记录,记录的是SQL语句,对数据进行修改的SQL都会记录在日志文件中。 |
| ROW | 基于行的日志记录,记录的是每一行的数据变更。(默认) |
| MIXED | 混合了STATEMENT和ROW两种格式,默认采用STATEMENT,在某些特殊情况下会自动切换为ROW进行记录。 |
71-- 查询BINLOG格式2mysql> show variables like '%binlog_format%';3+---------------+-------+4| Variable_name | Value |5+---------------+-------+6| binlog_format | ROW |7+---------------+-------+注意:
如果要修改BINLOG的日志格式,需要在 /etc/my.cnf 中配置 binlog_format 参数并重启服务器。
2) 查看BINLOG
BINLOG是以二进制方式存储的,不能直接读取,需要通过二进制日志查询工具 mysqlbinlog 来查看。
71mysqlbinlog [ 参数选项 ] logfilename2
3参数选项:4 -d 指定数据库名称,只列出指定的数据库相关操作5 -o 忽略掉日志中的前n行命令6 -v 将行事件(数据变更)重构为SQL语句7 -vv 将行事件(数据变更)重构为SQL语句,并输出注释信息
3) 删除BINLOG
对于比较繁忙的业务系统,每天生成的binlog数据巨大,如果长时间不清除,将会占用大量磁盘空间。可以通过以下几种方式清理日志:
| 指令 | 含义 |
|---|---|
| reset master | 删除全部 binlog 日志,删除之后,日志编号将从 binlog.000001重新开始 |
| purge master logs to 'binlog.*' | 删除 * 编号之前的所有日志 |
| purge master logs before 'yyyy-mm-dd hh24:mi:ss' | 删除日志为 "yyyy-mm-dd hh24:mi:ss" 之前产生的所有日志 |
也可以在mysql的配置文件中配置二进制日志的过期时间,设置了之后,二进制日志过期会自动删除。
61mysql> show variables like '%binlog_expire_logs_seconds%';2+----------------------------+---------+3| Variable_name | Value |4+----------------------------+---------+5| binlog_expire_logs_seconds | 2592000 |6+----------------------------+---------+第02章_实例管理
第一节 数据库
1. 查询和选中数据库
91-- 查询所有数据库2show databases; 3
4-- 选中数据库5use test01;6
7-- 查询当前选中数据库8select database();9
2. 创建数据库
31-- 创建数据库并指定字符集和排序规则(utf8mb4_zh_0900_as_cs表示区分重音和大小写)2create database if not exists test01 default charset utf8mb4 default collate utf8mb4_zh_0900_as_cs;3
3. 删除数据库
31-- 删除数据库2drop database if exists test01;3
4. 系统数据库
Mysql数据库安装完成后,自动创建下面四个数据库:
| 数据库 | 用途 |
|---|---|
| mysql | 存储MySQL服务器正常运行所需要的各种信息 (时区、主从、用户、权限等) |
| information_schema | 提供了访问数据库元数据的各种表和视图,包含数据库、表、字段类型及访问权限等 |
| performance_schema | 为MySQL服务器运行时状态提供了一个底层监控功能,主要用于收集数据库服务器性能参数 |
| sys | 包含了一系列方便 DBA 和开发人员利用 performance_schema性能数据库进行性能调优和诊断的视图 |
第二节 用户
1. 查询用户信息
141-- 查询所有用户2select * from mysql.user; 3+-----------+------------------+-------------+-------------+-------------+-------------+-------------+-----------+-------------+---------------+--------------+-----------+------------+-----------------+------------+------------+--------------+------------+-----------------------+------------------+--------------+-----------------+------------------+------------------+----------------+---------------------+--------------------+------------------+------------+--------------+------------------------+----------+------------+-------------+--------------+---------------+-------------+-----------------+----------------------+-----------------------+------------------------------------------------------------------------+------------------+-----------------------+-------------------+----------------+------------------+----------------+------------------------+---------------------+--------------------------+-----------------+4| Host | User | Select_priv | Insert_priv | Update_priv | Delete_priv | Create_priv | Drop_priv | Reload_priv | Shutdown_priv | Process_priv | File_priv | Grant_priv | References_priv | Index_priv | Alter_priv | Show_db_priv | Super_priv | Create_tmp_table_priv | Lock_tables_priv | Execute_priv | Repl_slave_priv | Repl_client_priv | Create_view_priv | Show_view_priv | Create_routine_priv | Alter_routine_priv | Create_user_priv | Event_priv | Trigger_priv | Create_tablespace_priv | ssl_type | ssl_cipher | x509_issuer | x509_subject | max_questions | max_updates | max_connections | max_user_connections | plugin | authentication_string | password_expired | password_last_changed | password_lifetime | account_locked | Create_role_priv | Drop_role_priv | Password_reuse_history | Password_reuse_time | Password_require_current | User_attributes |5+-----------+------------------+-------------+-------------+-------------+-------------+-------------+-----------+-------------+---------------+--------------+-----------+------------+-----------------+------------+------------+--------------+------------+-----------------------+------------------+--------------+-----------------+------------------+------------------+----------------+---------------------+--------------------+------------------+------------+--------------+------------------------+----------+------------+-------------+--------------+---------------+-------------+-----------------+----------------------+-----------------------+------------------------------------------------------------------------+------------------+-----------------------+-------------------+----------------+------------------+----------------+------------------------+---------------------+--------------------------+-----------------+6| % | huangyuanxin | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | | | | | 0 | 0 | 0 | 0 | caching_sha2_password | $A$005$h,%'~n•••DU•4hh+M)A#KBoQY1nl33KDQfKgZX2h67je9w9SoodtkNR82sYTVVB | N | 2022-04-09 18:08:53 | NULL | N | N | N | NULL | NULL | NULL | NULL |7| % | root | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | | | | | 0 | 0 | 0 | 0 | mysql_native_password | *39F2DB45932B8608195CB4C4CE5B1C0FFC443199 | N | 2021-10-22 11:38:46 | 0 | N | Y | Y | NULL | NULL | NULL | NULL |8| localhost | huangyuanxin | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | | | | | •3=•#B#t%gjWkLAymjthb7ZnVGsrX8Z1wBvPkJycMZjBXR4uKDu4 | N | 2022-04-09 18:05:22 | NULL | N | N | N | NULL | NULL | NULL | NULL |9| localhost | mysql.infoschema | Y | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | | | | | 0 | 0 | 0 | 0 | caching_sha2_password | $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED | N | 2021-09-01 12:20:14 | NULL | Y | N | N | NULL | NULL | NULL | NULL |10| localhost | mysql.session | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | Y | N | N | N | N | N | N | N | N | N | N | N | N | N | | | | | 0 | 0 | 0 | 0 | caching_sha2_password | $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED | N | 2021-09-01 12:20:14 | NULL | Y | N | N | NULL | NULL | NULL | NULL |11| localhost | mysql.sys | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | N | | | | | 0 | 0 | 0 | 0 | caching_sha2_password | $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED | N | 2021-09-01 12:20:14 | NULL | Y | N | N | NULL | NULL | NULL | NULL |12+-----------+------------------+-------------+-------------+-------------+-------------+-------------+-----------+-------------+---------------+--------------+-----------+------------+-----------------+------------+------------+--------------+------------+-----------------------+------------------+--------------+-----------------+------------------+------------------+----------------+---------------------+--------------------+------------------+------------+--------------+------------------------+----------+------------+-------------+--------------+---------------+-------------+-----------------+----------------------+-----------------------+------------------------------------------------------------------------+------------------+-----------------------+-------------------+----------------+------------------+----------------+------------------------+---------------------+--------------------------+-----------------+13注:Mysql中使用Host和User来唯一标识一个用户,其中Host表示允许登录的机器(localhost只能本地访问,%则无限制),User表示登录名。14
2. 修改用户信息
91-- 创建新用户2CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码'; 3
4-- 修改用户密码5ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码' ; 6
7-- 删除用户8DROP USER '用户名'@'主机名' ; 9
第三节 权限
1. 查询权限信息
101-- 查询用户权限2mysql> SHOW GRANTS FOR 'root'@'%';3+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+4| Grants for root@% |5+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+6| GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, RELOAD, SHUTDOWN, PROCESS, FILE, REFERENCES, INDEX, ALTER, SHOW DATABASES, SUPER, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, REPLICATION SLAVE, REPLICATION CLIENT, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, CREATE USER, EVENT, TRIGGER, CREATE TABLESPACE, CREATE ROLE, DROP ROLE ON *.* TO `root`@`%` WITH GRANT OPTION |7| GRANT APPLICATION_PASSWORD_ADMIN,BACKUP_ADMIN,BINLOG_ADMIN,BINLOG_ENCRYPTION_ADMIN,CONNECTION_ADMIN,ENCRYPTION_KEY_ADMIN,GROUP_REPLICATION_ADMIN,PERSIST_RO_VARIABLES_ADMIN,REPLICATION_SLAVE_ADMIN,RESOURCE_GROUP_ADMIN,RESOURCE_GROUP_USER,ROLE_ADMIN,SERVICE_CONNECTION_ADMIN,SESSION_VARIABLES_ADMIN,SET_USER_ID,SYSTEM_USER,SYSTEM_VARIABLES_ADMIN,TABLE_ENCRYPTION_ADMIN,XA_RECOVER_ADMIN ON *.* TO `root`@`%` WITH GRANT OPTION |8+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+9注:Mysql中常用的权限有 ALL/ALL PRIVILEGES(所有权限)、SELECT(查询)、INSERT(插入)、UPDATE(修改)、DELETE(删除)、ALTER(修改表)、DROP(删除库/表/视图)、CREATE(创建库/表)等。10
2. 授权与回收
61-- 授予权限 2grant all on db01.* to 'huangyuanxin'@'%'; -- GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名'3
4-- 回收权限5revoke all on db01.* from 'huangyuanxin'@'%'; -- REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名'6
第四节 事务
1. 事务控制命令
211-- 查看事务隔离级别2SELECT @@TRANSACTION_ISOLATION;3+-------------------------+4| @@TRANSACTION_ISOLATION |5+-------------------------+6| REPEATABLE-READ |7+-------------------------+8
9-- 设置事务隔离级别10SET [ SESSION | GLOBAL ] TRANSACTION ISOLATION LEVEL { READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE }11
12-- 开启事务13START TRANSACTION(或BEGIN)14
15-- 提交事务16COMMIT;17
18-- 回滚事务19ROLLBACK; 20
21
第五节 锁
1. 全局锁
1) 全局锁简介
全局锁就是对整个数据库加锁,加锁后数据库处于只读状态,后续的DML语句和DDL语句,以及尚未提交的事务都将会被阻塞。
其典型的应用场景就是做全库的逻辑备份,先对所有的表进行锁定,然后获取全局事务快照,从而保证数据的业务准确性。
扩展:为什么全库逻辑备份,需要加全局锁呢?
例如我们有库存表和订单表,在备份库存表后,将要备份订单表时,客户下单,在同一个事务扣减库存,并新增订单。
当未加全局锁时,库存表备份的是该事务之前的数据,但订单表备份是该事务提交之后的数据,库存和订单就对不上了。
但如果加了全局锁,在备份库存表前,已经获取到了全局事务快照,即使有新订单,也不会进行备份,保证数据一致性。
2) 全局加锁和解锁
91-- 加全局锁2flush tables with read lock;3
4-- 备份操作5mysqldump --single-transaction -h106.53.120.230 -P3306 -uroot -pHyx147741 test01 > D:\test01.sql6
7-- 释放锁8unlock tables; 9
注意:
上述操作流程仅作参考,实际上,mysqldump备份时会自动加全局锁,无需手动添加。
默认情况下,mysqldump在整个备份过程中,都将无法执行写操作,造成业务停摆。
可以通过添加
--single-transaction参数,让它仅在生成全局事务快照时加锁,并且也能保证数据一致性。
2. 表级锁
表级锁即对整张表加锁,容易发生锁冲突,并发性能较低。表级锁可分为表锁、元数据锁(DML)、意向锁。
1) 表锁
71-- 加表锁2LOCK TABLES TB_USER READ; -- 读模式:当前事务加读锁后,其它事务可以读,但不能写3LOCK TABLES TB_USER WRITE; -- 写模式:当前事务加写锁后,其它事务既不可以读,也不可以写4
5-- 释放锁6UNLOCK TABLES;7
2) 元数据锁
元数据锁(DML)即对表结构加锁,当执行DQL或DML操作时,将会加读锁,当执行DDL语句时,将会加写锁,可通过如下SQL语句查看:
141-- 查询元数据锁2mysql> SELECT OBJECT_TYPE,OBJECT_SCHEMA,OBJECT_NAME,LOCK_TYPE,LOCK_DURATION 3 FROM PERFORMANCE_SCHEMA.METADATA_LOCKS;4+-------------------+--------------------+----------------+---------------------+---------------+5| object_type | object_schema | object_name | lock_type | lock_duration |6+-------------------+--------------------+----------------+---------------------+---------------+7| TABLE | test01 | TB_USER | SHARED_READ_ONLY | TRANSACTION |8| TABLE | performance_schema | metadata_locks | SHARED_READ | TRANSACTION |9| SCHEMA | performance_schema | NULL | INTENTION_EXCLUSIVE | TRANSACTION |10| COLUMN STATISTICS | performance_schema | metadata_locks | SHARED_READ | STATEMENT |11| COLUMN STATISTICS | performance_schema | metadata_locks | SHARED_READ | STATEMENT |12| COLUMN STATISTICS | performance_schema | metadata_locks | SHARED_READ | STATEMENT |13+-------------------+--------------------+----------------+---------------------+---------------+14
常见SQL操作加的元数据锁如下:
| SQL操作 | 锁类型 | 说明 |
|---|---|---|
| lock tables xxxx read | SHARED_READ_ONLY | |
| lock tables xxxx write | SHARED_NO_READ_WRITE | |
| select、select ... lock in share mode | SHARED_READ | 可兼容SHARED_READ和SHARED_WRITE |
| insert 、update、delete、select ... for update | SHARED_WRITE | 可兼容SHARED_READ和SHARED_WRITE |
| alter table | EXCLUSIVE | 对所有的元数据锁(MDL)都互斥 |
3) 意向锁
意向锁用于优化表锁的加锁操作,当未引入意向锁时,如果要加表锁,则必须逐行检查每一行数据,防止与行锁冲突。
当引入意向锁后,SQL操作在加行锁的同时,也会在表级加意向锁,后续若要添加表锁,只需与表级的意向锁判断兼容性即可。
| SQL操作 | 意向锁类型 | 表锁兼容性 |
|---|---|---|
| select ... lock in share mode | 意向共享锁(IS) | 表锁-READ可兼容;表锁-WRITE不兼容 |
| insert、update、delete、select...for update | 意向排他锁(IX) | 表锁-READ和表锁-WRITE都不兼容 |
查询意向锁的SQL语句如下:
41-- 查询意向锁2select object_schema,object_name,index_name,lock_type,lock_mode,lock_data 3 from performance_schema.data_locks;4
注意:
普通select语句并不会添加意向锁,只有特殊的select语句才会加 IS 锁或 IX 锁。
意向锁之间,即使是 IX 锁和 IX 锁,也不会相互排斥。
3. 行级锁
1) 行级锁简介
在InnoDB引擎中,通过对索引加锁,实现了行级锁效果,常见SQL语句所加的行级锁如下:
| SQL操作 | 行级锁类型 | 说明 |
|---|---|---|
| SELECT | 不加锁 | |
| SELECT ... LOCK IN SHARE MODE | 行锁-READ | |
| SELECT ... FOR UPDATE | 行锁-WRITE | |
| INSERT、UPDATE、DELETE | 行锁-WRITE |
注意:
InnoDB引擎是对索引加锁,而非对记录加锁,如果SQL未走索引,则会对整个表加表锁。
在Oracle中,行级锁仅支持写模式加锁,不支持读模式加锁,而InnoDB引擎都支持。
查询行级锁及相关的意向锁SQL如下:
31-- 查询行级锁和意向锁2select object_schema,object_name,index_name,lock_type,lock_mode,lock_data3 from performance_schema.data_locks;根据不同的事务隔离级别和SQL索引情况,行级锁又分如下:
1) 行锁(RecordLock):仅对单行索引加锁,可防止其它事务修改该行数据。
2) 间隙锁(GapLock):仅对索引行之间的间隙加锁,可防止其它事务在该间隙中插入数据(可能产生幻读)。
3) 临键锁(NextKeyLock):行锁和间隙锁的组合,不仅锁住该行索引,也锁住该行之前的间隙。
2) 加锁流程
在RR隔离级别下,默认使用临键锁(NextKeyLock)扫描,以防止幻读。
当扫描的索引是唯一索引,并进行等值匹配,且数据恰好存在时,将优化为行锁,仅对该行索引加锁。
当扫描的索引是唯一索引,并进行等值匹配,但数据不存在时,将优化为间隙锁,对前后两行索引之间的间隙加锁。
当扫描的索引是唯一索引,但进行的是范围匹配时,将会一路加临键锁,直到不满足条件的第一个值为止。
当扫描的索引是非唯一索引,并进行等值匹配时,将会一路加临键锁,直到最后一个值不满足查询需求,在此之间加间隙锁。
当不走索引时,将升级为表锁,对所有记录加锁。
注意:
间隙锁唯一目的是防止其他事务在间隙插入新记录。
间隙锁可以共存,一个事务采用的间隙锁不会阻止另一个事务在同一间隙上采用间隙锁(即可以对同一个间隙进行UPDATE)。
3) 示例说明
3041-- ------------------------表结构和数据---------------------------- --2-- 表结构3CREATE TABLE `stu` (4`id` int NOT NULL PRIMARY KEY AUTO_INCREMENT, -- 主键,唯一索引5`name` varchar(255) DEFAULT NULL,6`age` int NOT NULL7) ENGINE = InnoDB CHARACTER SET = utf8mb4;8
9-- 数据10INSERT INTO `stu` VALUES (1, 'tom', 1);11INSERT INTO `stu` VALUES (3, 'cat', 3);12INSERT INTO `stu` VALUES (8, 'rose', 8);13INSERT INTO `stu` VALUES (11, 'jetty', 11);14INSERT INTO `stu` VALUES (19, 'lily', 19);15INSERT INTO `stu` VALUES (25, 'luci', 25);16
17-- ------------------------普通SELECT语句不加锁---------------------------- --18-- 开启事务,执行SELECT语句19mysql> begin;20mysql> select * from stu where id = 1;21
22-- 查询data_locks未发现加锁23mysql> select object_schema,object_name,index_name,lock_type,lock_mode,lock_data 24 from performance_schema.data_locks;25 26
27-- --------------------- 共享锁之间可兼容,共享锁和排他锁互斥 ------------------------- --28-- A客户端开启事务,执行SELECT...lock in share mode语句29mysql-A> begin;30mysql-A> select * from stu where id = 1 lock in share mode;31+---------------+-------------+------------+-----------+---------------+-----------+32| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |33+---------------+-------------+------------+-----------+---------------+-----------+34| test01 | stu | NULL | TABLE | IS | NULL |35| test01 | stu | PRIMARY | RECORD | S,REC_NOT_GAP | 1 | -- 共享模式行锁36+---------------+-------------+------------+-----------+---------------+-----------+37
38-- B客户端还能继续添加S锁39mysql-B> select * from stu where id = 1 lock in share mode;40+---------------+-------------+------------+-----------+---------------+-----------+41| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |42+---------------+-------------+------------+-----------+---------------+-----------+43| test01 | stu | NULL | TABLE | IS | NULL |44| test01 | stu | PRIMARY | RECORD | S,REC_NOT_GAP | 1 | -- B客户端的锁45| test01 | stu | NULL | TABLE | IS | NULL |46| test01 | stu | PRIMARY | RECORD | S,REC_NOT_GAP | 1 | -- A客户端的锁47+---------------+-------------+------------+-----------+---------------+-----------+48
49-- 但B客户端不能继续添加X锁50mysqlB> update stu set name='hyx' where id = 1; -- 卡住51
52
53-- --------------------- 排他锁和排他锁互斥 ------------------------- --54-- A客户端添加排他锁55mysql-A> update stu set name='hyx' where id = 1; 56+---------------+-------------+------------+-----------+---------------+-----------+57| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |58+---------------+-------------+------------+-----------+---------------+-----------+59| test01 | stu | NULL | TABLE | IX | NULL |60| test01 | stu | PRIMARY | RECORD | X,REC_NOT_GAP | 3 |61+---------------+-------------+------------+-----------+---------------+-----------+62
63-- B客户端卡住,等待A客户端提交或回滚事务64mysqlB> update stu set name='hyx' where id = 1; 65
66
67
68-- --------------------- 不走索引则锁住全部记录 ------------------------- --69mysql> update stu set name='hyx01' where name = 'hyx'; -- name字段无索引70+---------------+-------------+-----------------+-----------+---------------+------------------------+71| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |72+---------------+-------------+-----------------+-----------+---------------+------------------------+73| test01 | EMP | NULL | TABLE | IX | NULL |74| test01 | EMP | GEN_CLUST_INDEX | RECORD | X | supremum pseudo-record | -- 无穷大也会被加锁75| test01 | EMP | GEN_CLUST_INDEX | RECORD | X | 0x0000012AC508 |76| test01 | EMP | GEN_CLUST_INDEX | RECORD | X | 0x0000012AC507 | -- 每行记录都会加锁(注:该表删掉了部分)77+---------------+-------------+-----------------+-----------+---------------+------------------------+78
79
80-- --------------------- 唯一索引上的等值查询(记录存在时) ------------------------- --81mysql> select * from stu;82+----+-------+-----+83| id | name | age |84+----+-------+-----+85| 19 | lily | 19 |86+----+-------+-----+87
88mysql> update stu set name = 'hyx' where id = 19;89+---------------+-------------+------------+-----------+---------------+-----------+90| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |91+---------------+-------------+------------+-----------+---------------+-----------+92| test01 | stu | NULL | TABLE | IX | NULL | -- 表级意向排他锁93| test01 | stu | PRIMARY | RECORD | X,REC_NOT_GAP | 19 | -- 对应记录加行锁(REC_NOT_GAP)94+---------------+-------------+------------+-----------+---------------+-----------+95
96
97-- --------------------- 唯一索引上的等值查询(记录不存在时) ------------------------- --98mysql-A> select * from stu;99+----+-------+-----+100| id | name | age |101+----+-------+-----+102| 19 | lily | 19 |103| 25 | luci | 25 |104+----+-------+-----+105
106mysql-A> update stu set name = 'hyx' where id = 20;107+---------------+-------------+------------+-----------+---------------+-----------+108| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |109+---------------+-------------+------------+-----------+---------------+-----------+110| test01 | stu | NULL | TABLE | IX | NULL | 111| test01 | stu | PRIMARY | RECORD | X,GAP | 25 | -- 由于记录不存在,在该间隙添加间隙锁112+---------------+-------------+------------+-----------+---------------+-----------+113
114-- 间隙两端的记录可以更新115mysql-B> update stu set name = 'hyx' where id = 19; -- OK116mysql-B> update stu set name = 'hyx' where id = 25; -- OK117
118-- 并且被加锁的间隙也可以更新119mysql-B> update stu set name = 'hyx' where id = 20; -- OK 实际上该更新操作不会修改任何数据,不会造成幻读120
121-- 但是被加锁的间隙不能插入数据122mysql-B> insert into stu(id,name,age) values(20,'hyx',18); -- 卡死,但会添加插入意向锁(INSERT_INTENTION)123+---------------+-------------+------------+-----------+------------------------+-----------+124| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |125+---------------+-------------+------------+-----------+------------------------+-----------+126| test01 | stu | NULL | TABLE | IX | NULL |127| test01 | stu | PRIMARY | RECORD | X,GAP,INSERT_INTENTION | 25 | -- B客户端的间隙锁和插入意向锁128| test01 | stu | NULL | TABLE | IX | NULL |129| test01 | stu | PRIMARY | RECORD | X,GAP | 25 | -- A客户端的间隙锁130+---------------+-------------+------------+-----------+------------------------+-----------+131
132-- 当A客户端释放锁后,B客户端即可插入成功133mysql-A> rollback;134mysql-B> insert into stu(id,name,age) values(20,'hyx',18); -- 插入成功,并移除INSERT_INTENTION135
136
137
138-- --------------------- 唯一索引上的范围查询 ------------------------- --139mysql> select * from stu;140+----+-------+-----+141| id | name | age |142+----+-------+-----+143| 11 | jetty | 11 |144| 19 | hyx | 19 |145| 20 | hyx | 18 |146| 25 | hyx | 25 |147+----+-------+-----+148
149-- 大于150mysql> update stu set name = 'hyx' where id > 19; 151+---------------+-------------+------------+-----------+---------------+------------------------+152| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |153+---------------+-------------+------------+-----------+---------------+------------------------+154| test01 | stu | NULL | TABLE | IX | NULL | 155| test01 | stu | PRIMARY | RECORD | X | supremum pseudo-record | -- 临键锁(25,+∞]156| test01 | stu | PRIMARY | RECORD | X | 25 | -- 临键锁(20,25]157| test01 | stu | PRIMARY | RECORD | X | 20 | -- 临键锁(19,20]158+---------------+-------------+------------+-----------+---------------+------------------------+159
160-- 大于等于161mysql> update stu set name = 'hyx' where id >= 19; 162+---------------+-------------+------------+-----------+---------------+------------------------+163| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |164+---------------+-------------+------------+-----------+---------------+------------------------+165| test01 | stu | NULL | TABLE | IX | NULL | 166| test01 | stu | PRIMARY | RECORD | X,REC_NOT_GAP | 19 | -- 行锁id=19 (注:非唯一索引此情形将加临键锁)167| test01 | stu | PRIMARY | RECORD | X | supremum pseudo-record | -- 临键锁(25,+∞]168| test01 | stu | PRIMARY | RECORD | X | 25 | -- 临键锁(20,25]169| test01 | stu | PRIMARY | RECORD | X | 20 | -- 临键锁(19,20]170+---------------+-------------+------------+-----------+---------------+------------------------+171
172
173mysql> select * from stu3;174+----+-------+-----+175| id | name | age |176+----+-------+-----+177| 1 | tom | 18 |178| 2 | cat | 19 |179| 3 | rose | 19 |180| 4 | jetty | 19 |181| 5 | lily | 20 |182+----+-------+-----+183
184-- 小于185mysql> update stu3 set name = 'hyx' where id < 3; 186+---------------+-------------+------------+-----------+---------------+-----------+187| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |188+---------------+-------------+------------+-----------+---------------+-----------+189| test01 | stu3 | NULL | TABLE | IX | NULL | 190| test01 | stu3 | PRIMARY | RECORD | X | 1 | -- 临键锁(-∞,1] 191| test01 | stu3 | PRIMARY | RECORD | X | 2 | -- 临键锁(1,2]192| test01 | stu3 | PRIMARY | RECORD | X | 3 | -- 临键锁(2,3] (注:额外对id=3加行锁,可能影响业务)193+---------------+-------------+------------+-----------+---------------+-----------+194
195-- 小于等于196mysql> update stu3 set name = 'hyx' where id <=3;197+---------------+-------------+------------+-----------+---------------+-----------+198| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |199+---------------+-------------+------------+-----------+---------------+-----------+200| test01 | stu3 | NULL | TABLE | IX | NULL |201| test01 | stu3 | PRIMARY | RECORD | X | 1 | -- 临键锁(-∞,1]202| test01 | stu3 | PRIMARY | RECORD | X | 2 | -- 临键锁(1,2]203| test01 | stu3 | PRIMARY | RECORD | X | 4 | -- 临键锁(3,4] (注:额外对id=4及之前的间隙加锁,可能影响业务)204| test01 | stu3 | PRIMARY | RECORD | X | 3 | -- 临键锁(2,3]205+---------------+-------------+------------+-----------+---------------+-----------+2069 rows in set (0.01 sec)207
208-- 先执行小于再执行等于209mysql> update stu3 set name = 'hyx' where id < 3; 210mysql> update stu3 set name = 'hyx' where id = 3;211+---------------+-------------+------------+-----------+---------------+-----------+212| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |213+---------------+-------------+------------+-----------+---------------+-----------+214| test01 | stu3 | NULL | TABLE | IX | NULL |215| test01 | stu3 | PRIMARY | RECORD | X | 1 | -- 临键锁(1,2]216| test01 | stu3 | PRIMARY | RECORD | X | 2 | -- 临键锁(1,2]217| test01 | stu3 | PRIMARY | RECORD | X | 3 | -- 临键锁(2,3] (注:这里只会将3及之前的记录加临键锁,符合业务需要)218+---------------+-------------+------------+-----------+---------------+-----------+219
220
221-- ------------------ 非唯一索引上的等值查询 ----------------------- --222mysql> select * from stu3;223+----+-------+-----+224| id | name | age |225+----+-------+-----+226| 1 | tom | 18 |227| 2 | cat | 19 |228| 3 | rose | 19 |229| 4 | jetty | 19 |230| 5 | lily | 20 |231+----+-------+-----+232
233-- 创建非唯一索引234mysql> create index stu_age_idx on stu3(age);235
236-- 非唯一索引的等值查询,可能更新多条记录237mysql> update stu3 set name = 'hyx' where age = 19; 238+---------------+-------------+-------------+-----------+---------------+-----------+239| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |240+---------------+-------------+-------------+-----------+---------------+-----------+241| test01 | stu3 | NULL | TABLE | IX | NULL | 242| test01 | stu3 | stu_age_idx | RECORD | X | 19, 2 | -- 临键锁(18->1,19->2] (注:额外锁住了第1个匹配值之前的间隙,可能影响业务)243| test01 | stu3 | stu_age_idx | RECORD | X | 19, 3 | -- 临键锁(19->2,19->3] 244| test01 | stu3 | stu_age_idx | RECORD | X | 19, 4 | -- 临键锁(19->3,19->4] 245| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 2 | -- 行锁id=2 (注:在非主键索引上加锁,必须额外锁住主键上的对应行)246| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 3 | -- 行锁id=3247| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 4 | -- 行锁id=4248| test01 | stu3 | stu_age_idx | RECORD | X,GAP | 20, 5 | -- 间隙锁(19->4,20->5) (注:额外锁住了第1个不匹配值之前的间隙,可能影响业务)249+---------------+-------------+-------------+-----------+---------------+-----------+250
251
252-- ------------------ 非唯一索引上的范围查询 ----------------------- --253mysql> select * from stu3;254+----+-------+-----+255| id | name | age |256+----+-------+-----+257| 1 | tom | 10 |258| 2 | cat | 20 |259| 3 | rose | 30 |260| 4 | jetty | 40 |261| 5 | lily | 50 |262+----+-------+-----+263
264-- 大于(和唯一索引范围查询表现类似)265mysql> update stu3 set name = 'hyx' where age > 30;266+---------------+-------------+-------------+-----------+---------------+------------------------+267| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |268+---------------+-------------+-------------+-----------+---------------+------------------------+269| test01 | stu3 | NULL | TABLE | IX | NULL | 270| test01 | stu3 | stu_age_idx | RECORD | X | supremum pseudo-record | -- 临键锁(50->5,+∞] 271| test01 | stu3 | stu_age_idx | RECORD | X | 40, 4 | -- 临键锁(30->3,40->4]272| test01 | stu3 | stu_age_idx | RECORD | X | 50, 5 | -- 临键锁(40->4,50->5]273| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 5 | -- 行锁id=5 274| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 4 | -- 行锁id=4275+---------------+-------------+-------------+-----------+---------------+------------------------+276
277-- 大于 && 小于等于(此种情形会额外对限定之外的记录添加“行锁”,影响非常大)278mysql> update stu3 set name = 'hyx' where age > 20 and age <= 40;279+---------------+-------------+-------------+-----------+---------------+-----------+280| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |281+---------------+-------------+-------------+-----------+---------------+-----------+282| test01 | stu3 | NULL | TABLE | IX | NULL |283| test01 | stu3 | stu_age_idx | RECORD | X | 30, 3 | -- 临键锁(20->2,30->3]284| test01 | stu3 | stu_age_idx | RECORD | X | 40, 4 | -- 临键锁(30->3,40->4]285| test01 | stu3 | stu_age_idx | RECORD | X | 50, 5 | -- 临键锁(40=>4,50->5] (注:额外对age=50及之前的间隙加锁,可能影响业务)286| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 3 | -- 行锁id=3287| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 5 | -- 行锁id=5 288| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 4 | -- 行锁id=4 289+---------------+-------------+-------------+-----------+---------------+-----------+290
291-- 大于等于 && 小于292mysql> update stu3 set name = 'hyx' where age >= 20 and age < 40;293+---------------+-------------+-------------+-----------+---------------+-----------+294| object_schema | object_name | index_name | lock_type | lock_mode | lock_data |295+---------------+-------------+-------------+-----------+---------------+-----------+296| test01 | stu3 | NULL | TABLE | IX | NULL |297| test01 | stu3 | stu_age_idx | RECORD | X | 20, 5 | -- 这里没看明白?这个5是啥?298| test01 | stu3 | stu_age_idx | RECORD | X | 20, 2 | -- 临键锁(10->1,20->2] (注:额外对20之前的间隙加锁,可能影响业务)299| test01 | stu3 | stu_age_idx | RECORD | X | 30, 3 | -- 临键锁(20->2,30->3]300| test01 | stu3 | stu_age_idx | RECORD | X | 40, 4 | -- 临键锁(30->3,40->4]301| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 2 | -- 行锁id=2302| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 4 | -- 行锁id=4303| test01 | stu3 | PRIMARY | RECORD | X,REC_NOT_GAP | 3 | -- 行锁id=3304+---------------+-------------+-------------+-----------+---------------+-----------+
第六节 备份恢复
1. mysqldump
mysqldump 是 MySQL 自带的逻辑备份工具。备份时将数据库转换为SQL脚本文件,恢复时通过执行脚本来进行恢复。执行流程如下:
1) 调用FTWRL(flush tables with read lock),加全局读锁,禁止全库写操作。
2) 开启快照读,获取此时的快照(仅对innodb表起作用)。
3) 备份非innodb表数据(*.frm,*.myi,*.myd等)。
4) 非innodb表备份完毕后,释放FTWRL锁。
5) 通过读视图逐一备份innodb表数据。
6) 备份完成。
251# 语法格式2mysqldump [options] db_name [tables]3mysqldump [options] --database/-B db1 [db2 db3...]4mysqldump [options] --all-databases/-A5
6# 输出选项7--add-drop-database 添加 drop database 语句8--add-drop-table 添加 drop table 语句,默认开启; 9--skip-add-drop-table 不添加 drop table 语句10-n, --no-create-db 不包含数据库的创建语句11-t, --no-create-info 不包含数据表的创建语句12-d --no-data 不包含数据13-T, --tab=name 生成两个文件(包含表结构的.sql文件和包含数据的.txt文件)14
15# 生产备份示例16mysqldump -h 106.53.120.230 -P3306 -u root -phyx123456 kfms --complete-insert --add-drop-table --skip-add-locks --set-gtid-purged=OFF | pv -t -n --bytes > /data/kfms01.sql17
18# 生产恢复示例19mysql -h 106.53.120.230 -P3306 -u root -phyx123456 kfms < /data/kfms01.sql20
21# 扩展:备份单个库到服务端,并将表结构(.sql)和数据(.txt)分开存储22# 注意:目录必须为 show variables like 'secure_file_priv' 指定的信任目录23# 提示:mysqldump -T 备份的文件用 mysqlimport -uroot -p2143 test /tmp/city.txt 恢复24mysqldump -h 106.53.120.230 -P 3306 -u root -pHyx147741 -T /var/lib/mysql-files/ test01 # 测试报错!25
2. mydumper
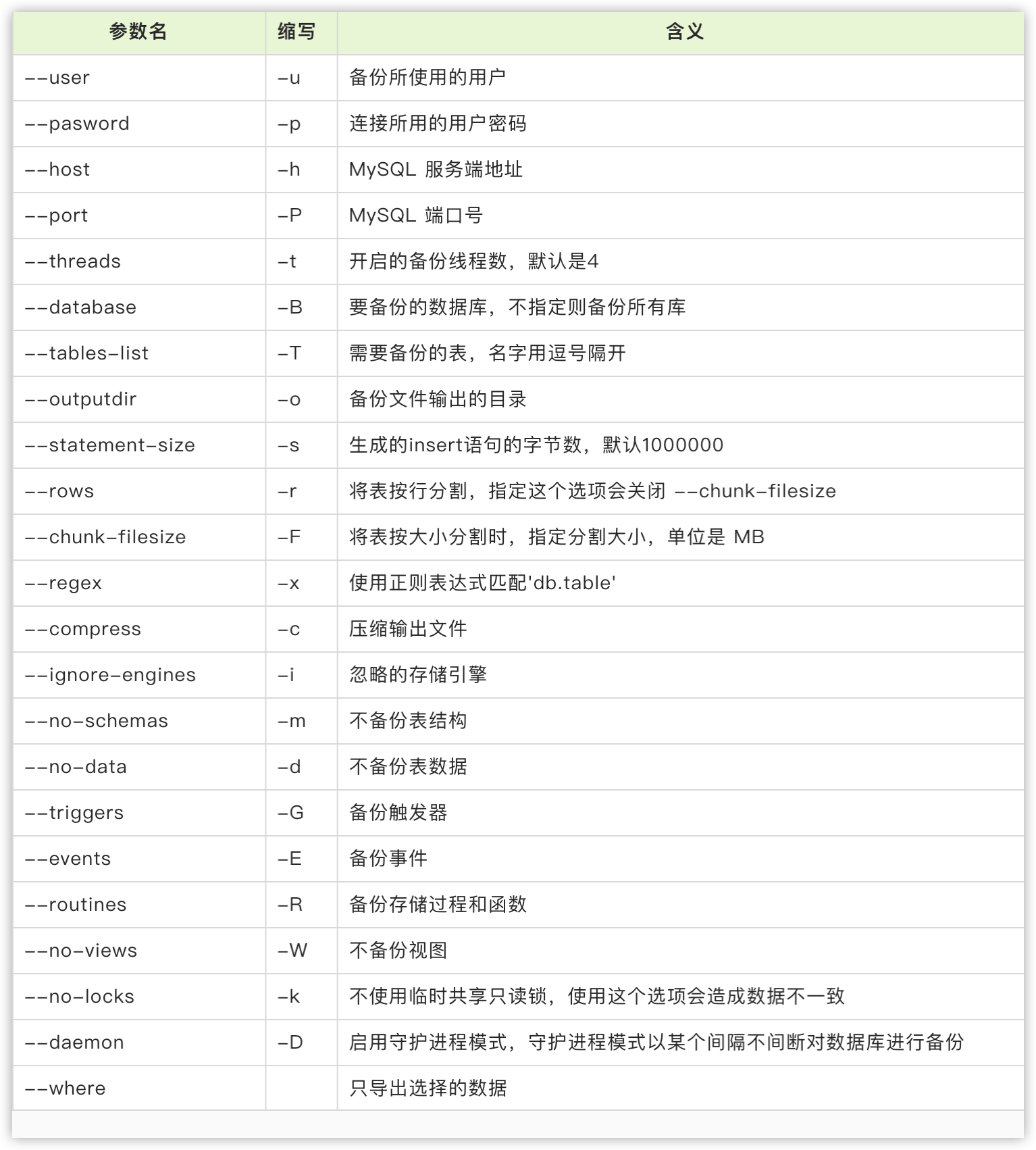
mydumper是一款社区开源的MySql逻辑备份和恢复工具,主要有以下几点特性:
1) 支持多线程导出数据和恢复,速度更快。
2) 支持按照指定大小将备份文件切割,也支持将导出文件压缩,节约空间。
3) 支持数据与建表语句分离。
4) 支持以守护进程模式工作,定时快照和连续二进制日志。
它的官网地址为:https://launchpad.net/mydumperGitHub,GITHUB地址为:https://github.com/maxbube/mydumper,安装步骤如下:
191# 1. 方式一:编译安装2[root@localhost ~]# yum -y install glib2-devel mysql-devel zlib-devel pcre-devel zlib gcc-c++ gcc cmake3[root@localhost ~]# wget https://launchpad.net/mydumper/0.9/0.9.1/+download/mydumper-0.9.1.tar.gz4[root@localhost ~]# tar zxf mydumper-0.9.1.tar.gz5[root@localhost ~]# cd mydumper-0.9.1/6[root@localhost mydumper-0.9.1]# cmake .7[root@localhost mydumper-0.9.1]# make8[root@localhost mydumper-0.9.1]# make install9
10# 2. 方式二:rpm 包安装。地址:https://github.com/maxbube/mydumper/releases 请根据自己的系统类型选择下载版本。11[root@localhost ~]# yum install https://github.com/maxbube/mydumper/releases/download/v0.10.7-2/mydumper-0.10.7-2.el7.x86_64.rpm12
13# 3. 安装完成后生成两个二进制文件 mydumper 和 myloader 位于 /usr/local/bin 目录下14[root@localhost bin]# ls /usr/local/bin/15mydumper myloader16
17##4. 检查安装是否成功18[root@localhost bin]# mydumper --help19
下面是一些常见的使用场景:
251# 备份全部数据库 2# 全量备份 会备份 mysql、sys 系统库及其他自建库3mydumper -u root -p 123456 -o /mysql_backup/all/ 4
5# 备份全部数据库 包含触发器、事件、存储过程及函数6mydumper -u root -p 123456 -G -R -E -o /mysql_backup/all2/7
8# 备份指定库9mydumper -u root -p 123456 -G -R -E -B db1 -o /mysql_backup/db1/10
11# 使用正则 排除系统库12mydumper -u root -p 123456 -G -R -E --regex '^(?!(mysql|sys))' -o /mysql_backup/all313
14# 备份指定表15mydumper -u root -p 123456 -B db1 -T tb1,tb2 -o /mysql_backup/tb/16
17# 只备份表结构18mydumper -u root -p 123456 -d -B db1 -o /mysql_backup/nodata/19
20# 只备份表数据21mydumper -u root -p 123456 -m -B db1 -o /mysql_backup/noschema/22
23# 压缩备份某个表24mydumper -u root -p 123456 -B db1 -T tb1 -c -o /mysql_backup/compress/25
详细参数说明如下:
3. select… into outfile
select… into outfile 是MySQL支持的备份恢复命令。备份时将SELECT查询的结果集转换为CVS格式文件,恢复时从CVS文件读取。
131-- 备份2-- 注意1:提前使用 use 选中数据库3-- 注意2:备份目录必须是信任目录,通过 show variables like 'secure_file_priv' 查询4select * from CUACCT 5 into outfile '/var/lib/mysql-files/cuacct.csv' 6 fields terminated by ',' enclosed by"" lines terminated by '\n';7
8-- 恢复9-- 注意:需提前检查表中数据与文件数据是否存在冲突10load data infile '/var/lib/mysql-files/cuacct.csv' 11into table CUACCT 12CHARACTER SET UTF8 fields terminated by ',' enclosed by "" lines terminated by '\n';13
4. Xtrabackup
Xtrabackup是由percona开源的免费数据库热备份软件,它能对InnoDB数据库和XtraDB存储引擎的数据库非阻塞的备份(对于MyISAM的备份同样需要加表锁);
Xtrabackup安装完成后有4个可执行文件,其中2个比较重要的备份工具是 innobackupex、xtrabackup。
xtrabackup:是专门用来备份InnoDB表的,和mysql server没有交互。
innobackupex:是一个封装xtrabackup的Perl脚本,支持同时备份innodb和myisam,但在对myisam备份时需要加一个全局的读锁。
xbcrypt:加密解密备份工具。
xbstream:流传打包传输工具,类似tar。
备份开始时首先会开启一个后台检测进程,实时检测 redo log 的变化,一旦发现有新的日志写入,立刻将日志记入后台日志文件xtrabackup_log 中,之后复制innodb的数据文件和系统表空间文件ibdatax,复制结束后,将执行flush tables with readlock,然后复制.frm MYI MYD等文件,最后执行unlock tables,最终停止xtrabackup_log。
5. 性能对比
在 MySql8.0 环境下同机备份100万CUACCT_LOG结果如下:
| 备份方式 | 备份时间 | 备份文件大小 | 恢复时间 |
|---|---|---|---|
| mysqldump | 8s | 264M | 45s |
| mydumper | 6s | 265M | 41s |
| select… into outfile | 4.5s | 220M | 41s |
第03章_数据对象
第一节 数据类型
1. 数值类型
| 类型 | 大小 | 补充说明 |
|---|---|---|
| TINYINT | 1byte | |
| SMALLINT | 2bytes | |
| INT/INTEGER | 4bytes | 特殊示例: int(d) zerofill,其中d表示显示宽度(默认11),zerofill表示用0填充。 |
| BIGINT | 8bytes | |
| FLOAT | 4bytes | |
| DOUBLE | 8bytes | |
| DECIMAL(p,s) | 精确小数。其中p表示最大有效数字,s表示最大小数位数,p-s就是最大整数位数。 |
2. 字符串类型
| 类型 | 大小 | 补充说明 |
|---|---|---|
| CHAR | 0-255bytes | 定长字符串(默认以空格填充) |
| VARCHAR | 0-65535bytes | 变长字符串 |
| BLOB | 0-65535bytes | 二进制形式的长文本数据 |
| LONGBLOB | 0-4294967295bytes | 二进制形式的极大文本数据 |
注意:
CHAR类型字段存储时在右侧填充空格以达到指定的长度,在检索时去掉右边所有空格。
VARCHAR类型字段存储时右边不会填充空格,且在检索数据时,会保留数据尾部的空格。
3. 日期时间类型
| 类型 | 大小 | 补充说明 |
|---|---|---|
| DATE | 3bytes | YYYY-MM-DD |
| TIME | 3bytes | HH:MM:SS |
| YEAR | 1bytes | YYYY(1901-2155) |
| DATETIME | 8bytes | YYYY-MM-DDHH:MM:SS |
| TIMESTAMP | 4bytes | YYYY-MM-DDHH:MM:SS(1970-01-01 00:00:01 至 2038-01-19 03:14:07) |
注意:
TIMESTAMP底层以时间戳方式存储,在存储和查询时都要进行时区转换,不同时区对同一数据可能看到不同展示。
DATETIME存储和查询始终以插入时当地的时区为准,其他时区的人查看数据可能会有误差。
第二节 数据表
1. 查询表信息
101-- 查询当前数据库所有表2show tables; 3SELECT TABLE_NAME FROM information_schema.tables WHERE TABLE_SCHEMA = database() AND TABLE_TYPE = 'BASE TABLE';4
5-- 查询表结构6desc tb_user;7
8-- 查询建表语句(注意:该建表语句是数据库反向生成的,可能带有存储引擎、字符集等默认选项)9show create table tb_user;10
2. 创建和删除表
141-- 创建普通表2CREATE TABLE EMP(3 ID INT AUTO_INCREMENT COMMENT '编号',4 WORKNO VARCHAR(10) COMMENT '工号',5 NAME VARCHAR(10) COMMENT '姓名',6 GENDER CHAR(1) COMMENT '性别',7 AGE TINYINT UNSIGNED COMMENT '年龄',8 IDCARD CHAR(18) COMMENT '身份证号',9 ENTRYDATE DATE COMMENT '入职时间'10) COMMENT '员工表';11
12-- 删除表13DROP TABLE IF EXISTS EMP;14
提示:
如果出现关键字冲突,可以使用着重号(`)框起来。
3. 修改表结构
151-- 添加字段2ALTER TABLE EMP ADD NICKNAME VARCHAR(20) COMMENT '昵称'; 3
4-- 修改数据类型5ALTER TABLE EMP MODIFY NICKNAME VARCHAR(32); 6
7-- 修改字段名和类型8ALTER TABLE EMP CHANGE NICKNAME USERNAME varchar(64) COMMENT '昵称'; 9
10-- 删除字段11ALTER TABLE EMP DROP USERNAME;12
13-- 修改表名14ALTER TABLE EMP RENAME TO EMPLOYEE; 15
第三节 约束
1. 添加约束
311-- 创建表时添加约束2CREATE TABLE TB_USER(3 ID INT PRIMARY KEY AUTO_INCREMENT COMMENT 'ID唯一标识', -- 主键约束,自增列4 NAME VARCHAR(10) NOT NULL UNIQUE COMMENT '姓名' , -- 非空约束,唯一性约束5 AGE INT CHECK (AGE > 0 && AGE <= 120) COMMENT '年龄' , -- 检查约束6 STATUS CHAR(1) DEFAULT '1' COMMENT '状态', -- 默认值约束7 GENDER CHAR(1) COMMENT '性别'8 -- CONSTRAINT uk_name_pwd UNIQUE(NAME,PASSWORD) -- 表级唯一约束9 -- CONSTRAINT emp5_id_pk PRIMARY KEY(id) -- 表级主键约束10 -- foreign key (deptid) references dept(did) -- 外键约束11);12
13-- 添加主键约束14ALTER TABLE student ADD CONSTRAINT pk_student_id PRIMARY KEY (student_id); 15
16-- 添加自增列17alter table employee modify eid int auto_increment;18
19-- 添加非空约束20alter table student modify sname varchar(20) not null; 21
22-- 添加默认值约束23alter table employee modify tel char(11) default '' not null; -- 给tel字段增加默认值约束,并保留非空约束24
25-- 添加唯一约束26ALTER TABLE USER ADD CONSTRAINT uk_name_pwd UNIQUE(NAME,PASSWORD);27ALTER TABLE USER MODIFY NAME VARCHAR(20) UNIQUE;28
29-- 添加外键约束30-- 对于外键约束,最好是采用: ON UPDATE CASCADE ON DELETE RESTRICT 的方式31ALTER TABLE TB_USER ADD CONSTRAINT FK_EMP_DEPT_ID FOREIGN KEY (DEPT_ID) REFERENCES DEPT(ID) ; 注意:
自增列关键字AUTO_INCREMENT必须加在整数类型的主键列或唯一索引列之上,且最多存在1个。
MySQL 8.0之后将自增列的计数器持久化到重做日志中,重启数据库不会再生成已删除的重复序号。
主表dept必须先创建成功,然后才能创建emp表,指定外键成功,删除表时,先删除从表emp,再删除主表dept。
2. 查看和删除约束
431-- 查看约束2mysql> DESC TB_USER;3+--------+-------------+------+-----+---------+-------+4| Field | Type | Null | Key | Default | Extra |5+--------+-------------+------+-----+---------+-------+6| ID | int(11) | NO | PRI | NULL | |7| NAME | varchar(10) | NO | UNI | NULL | |8| AGE | int(11) | YES | | NULL | |9| STATUS | char(1) | YES | | 1 | |10| GENDER | char(1) | YES | | NULL | |11+--------+-------------+------+-----+---------+-------+12mysql> SELECT * FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE table_name='TB_USER';13+--------------------+-------------------+-----------------+--------------+------------+-----------------+----------+14| CONSTRAINT_CATALOG | CONSTRAINT_SCHEMA | CONSTRAINT_NAME | TABLE_SCHEMA | TABLE_NAME | CONSTRAINT_TYPE | ENFORCED |15+--------------------+-------------------+-----------------+--------------+------------+-----------------+----------+16| def | test01 | PRIMARY | test01 | TB_USER | PRIMARY KEY | YES |17| def | test01 | NAME | test01 | TB_USER | UNIQUE | YES |18| def | test01 | TB_USER_chk_1 | test01 | TB_USER | CHECK | YES |19+--------------------+-------------------+-----------------+--------------+------------+-----------------+----------+20
21-- 删除主键约束22ALTER TABLE TB_USER DROP PRIMARY KEY;23
24-- 删除自增列25alter table 表名称 modify 字段名 数据类型; #去掉auto_increment相当于删除26
27-- 删除非空约束28ALTER TABLE emp MODIFY sex VARCHAR(30) NULL; -- 不写NOT NULL就相当于删除29
30-- 删除默认值约束31alter table employee modify tel char(11) not null; -- 删除tel字段默认值约束,保留非空约束32
33-- 删除唯一约束34-- 删除唯一约束通过删除对应的唯一索引来实现,可以通过 show index from 表名称 查看表的索引35ALTER TABLE USER DROP INDEX uk_name_pwd; 36
37-- 删除CHECK约束38ALTER TABLE TB_USER DROP CHECK TB_USER_chk_1;39 40-- 删除外键约束41-- 删除外键约束后可能还需要手动删除相关索引42ALTER TABLE TB_USER DROP FOREIGN KEY FK_EMP_DEPT_ID; 43
第四节 索引
1. 索引简介
索引(index)是帮助MySQL高效获取数据的结构,有利于提高数据检索和排序的效率,降低数据库的IO/CPU成本,但是索引也会占用一定的空间,并且在执行DML语句时需对其进行维护。
在MySQL数据库中,将索引按功能类型分为主键索引、唯一索引、普通索引、全文索引等。
| 功能类型 | 关键字 | 特点说明 |
|---|---|---|
| 主键索引 | PRIMARY | 针对表中主键创建的唯一性非空索引,默认创建,且只能有一个 |
| 唯一索引 | UNIQUE | 针对表中具有唯一性特征的列建立的索引,可以保证列值的唯一性,但不能保证非空 |
| 普通索引 | 无 | 有利于快速检索和排序数据 |
| 全文索引 | FULLTEXT | 类似于ElasticSearch中的倒排索引,用于查找文本中的关键词 |
2. 索引语法
121-- 查看索引2SHOW INDEX FROM table_name ; 3
4-- 创建索引5CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name,... ) ;6
7-- 前缀索引8CREATE INDEX IDX_XXXX ON TABLE_NAME(COLUMN(N)); -- 使用字段的前N个字符作为索引,适用于对长文本做索引9
10-- 删除索引11DROP INDEX index_name ON table_name ;12
第五节 视图
1. 视图语法
171-- 查询所有视图2SELECT TABLE_NAME FROM information_schema.views WHERE TABLE_SCHEMA = database();3SELECT TABLE_NAME FROM information_schema.tables WHERE TABLE_SCHEMA = database() AND TABLE_TYPE = 'VIEW';4
5-- 创建视图6CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]7
8-- 查看视图定义9SHOW CREATE VIEW 视图名称;10
11-- 修改视图定义12CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]13ALTER VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]14
15-- 删除视图16DROP VIEW [IF EXISTS] 视图名称 [,视图名称] ... 17
2. 检查选项
Mysql支持通过视图来执行DML操作,但可能出现修改到视图查询之外的行的情况,此时,可添加WITH CHECK OPTION子句来做检查。
该子句有两种模式:
CASCADED:默认值,不仅会检查当前视图,还会检查该视图所查询的其它视图。
LOCAL:仅检查当前视图,如果所查询的其它视图未添加WITH CHECK OPTION子句,则不会进行检查。
注意:
必须保证视图和表中的数据是一对一的关系,若包含DISTINCT、聚合函数、Group By、Union等,则不可执行DML操作。
第六节 序列
1. 序列语法
91-- 查询所有序列2
3
4-- 创建序列5CREATE SEQUENCE sequence_name START WITH start_value INCREMENT BY increment_value;6
7-- 使用序列8INSERT INTO table_name (column_name) VALUES (NEXT VALUE FOR sequence_name);9
第七节 分区表
1. 分区表语法
671-- 列表分区2CREATE TABLE employees (3 id INT NOT NULL,4 fname VARCHAR(30),5 lname VARCHAR(30),6 hired DATE NOT NULL DEFAULT '1970-01-01',7 separated DATE NOT NULL DEFAULT '9999-12-31',8 job_code INT,9 store_id INT10)11PARTITION BY LIST(store_id) (12 PARTITION pNorth VALUES IN (3,5,6,9,17),13 PARTITION pEast VALUES IN (1,2,10,11,19,20),14 PARTITION pWest VALUES IN (4,12,13,14,18),15 PARTITION pCentral VALUES IN (7,8,15,16)16);17
18 19-- 哈希分区20-- 基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。21-- 这个函数可以包含myql中有效的、产生非负整数值的任何表达式22CREATE TABLE employees (23 id INT NOT NULL,24 fname VARCHAR(30),25 lname VARCHAR(30),26 hired DATE NOT NULL DEFAULT '1970-01-01',27 separated DATE NOT NULL DEFAULT '9999-12-31',28 job_code INT,29 store_id INT30)31PARTITION BY LINEAR HASH(YEAR(hired))32PARTITIONS 4;33
34
35-- Key分区36-- 类似于hash分区,区别在于key分区只支持一列或多列,且mysql服务器提供其自身的哈希函数,必须有一列或多列包含整数值37CREATE TABLE tk (38 col1 INT NOT NULL,39 col2 CHAR(5),40 col3 DATE41)42PARTITION BY LINEAR KEY (col1)43PARTITIONS 3;44
45
46-- 二级分区47-- 在分区的基础之上,再进行分区后存储48CREATE TABLE `t_partition_by_subpart`49(50 `id` INT AUTO_INCREMENT,51 `sName` VARCHAR(10) NOT NULL,52 `sAge` INT(2) UNSIGNED ZEROFILL NOT NULL,53 `sAddr` VARCHAR(20) DEFAULT NULL,54 `sGrade` INT(2) NOT NULL,55 `sStuId` INT(8) DEFAULT NULL,56 `sSex` INT(1) UNSIGNED DEFAULT NULL,57 PRIMARY KEY (`id`, `sGrade`)58) ENGINE = INNODB59PARTITION BY RANGE(id)60SUBPARTITION BY HASH(sGrade) SUBPARTITIONS 261(62 PARTITION p0 VALUES LESS THAN(5),63 PARTITION p1 VALUES LESS THAN(10),64 PARTITION p2 VALUES LESS THAN(15)65);66
67
第04章_数据操作
基本SQL语法另请查阅《Oracle学习笔记(基础篇).md》,不再重复介绍。
第一节 数据修改
1. 批量插入
51-- 批量插入2INSERT INTO EMP 3 VALUES(3,'3','韦一笑','男',38,'123456789012345670','2005-01-01'),4 (4,'4','赵敏','女',18,'123456789012345670','2005-01-01');5
2. 归并数据
71-- ON DUPLICATE KEY方式实现2-- 注意:在高并发环境下,此种方式可能会导致主从不一致3INSERT INTO T1 SELECT ID,NAME,SALE,NOW() FROM T2 ON DUPLICATE KEY UPDATE SALE=VALUES(SALE);4
5-- REPLACE INTO方式实现(先删除后插入)6REPLACE INTO T1 SELECT ID,NAME,SALE,NOW() FROM T2;7
3. 相关修改
91-- 相关更新2-- 修改 department_name 字段为员工对应的部门名称3UPDATE employees e4 SET department_name = (SELECT department_name FROM departments d WHERE e.department_id = d.department_id);5 6-- 相关删除7-- 删除表employees中,其与emp_history表皆有的数据8DELETE FROM employees e9 WHERE employee_id in (SELECT employee_id FROM emp_history WHERE employee_id = e.employee_id);
第二节 数据查询
1. 分页查询
121-- 语法格式2SELECT * FROM EMP LIMIT [起始索引,] 查询记录数; -- 起始索引从0开始,一般为“(查询页码 - 1)* 每页显示记录数”3
4-- 查询前N条5SELECT * FROM EMP LIMIT 10;6
7-- 从第M条开始查询N条8SELECT * FROM EMP LIMIT 1000,10;9
10-- 分页查询优化(用业务键定位起始索引)11SELECT * FROM EMP WHERE ID >= 1000 ORDER BY ID LIMIT 10;12
2. 表达式
61-- 简单IF判断2SELECT IF(FALSE, 'Ok', 'Error'); -- 表达式1为true则返回参数2,否则返回参数3 Error3
4-- 特殊的,IF判断是否为空5SELECT IFNULL(NULL,'DEFAULT') FROM DUAL; -- Default6
注意:
其它两种基本的SQL99表达式(IF模型/SWITCH模型)都支持,但是不支持Oracle独有的decode函数
3. 正则查询
271-- 查询以特定字符或字符串开头的记录2SELECT * FROM fruits WHERE f_name REGEXP '^b';3
4-- 查询以特定字符或字符串结尾的记录5SELECT * FROM fruits WHERE f_name REGEXP 'y$';6
7-- 用符号"."来替代字符串中的任意一个字符8SELECT * FROM fruits WHERE f_name REGEXP 'a.g';9
10-- 使用"*"和"+"来匹配多个字符 11SELECT * FROM fruits WHERE f_name REGEXP '^ba*';12SELECT * FROM fruits WHERE f_name REGEXP '^ba+';13
14-- 匹配指定字符串15SELECT * FROM fruits WHERE f_name REGEXP 'on'; -- 包含on16SELECT * FROM fruits WHERE f_name REGEXP 'on|ap'; -- 包含on或ap17
18-- 匹配指定字符中的任意一个19SELECT * FROM fruits WHERE f_name REGEXP '[ot]';20SELECT * FROM fruits WHERE s_id REGEXP '[456]';21
22-- 匹配指定字符以外的字符23SELECT * FROM fruits WHERE f_id REGEXP '[^a-e1-2]';24
25-- 使用{n,}或者{n,m}来指定字符串连续出现的次数26SELECT * FROM fruits WHERE f_name REGEXP 'x{2,}';27SELECT * FROM fruits WHERE f_name REGEXP 'ba{1,3}';
4. 公用表达式(CTE)
171-- 普通公用表达式2WITH emp_dept_id AS (SELECT DISTINCT department_id FROM employees)3SELECT * FROM departments d JOIN emp_dept_id e 4 ON d.department_id = e.department_id;5
6-- 递归公用表达式7-- 列出所有具有下下属身份的人员信息8WITH RECURSIVE cte AS (9 SELECT employee_id,last_name,manager_id,1 AS n 10 FROM employees 11 WHERE employee_id = 100 -- 种子查询,找到第一代领导12UNION ALL13 SELECT a.employee_id,a.last_name,a.manager_id,n+1 14 FROM employees AS a 15 JOIN cte ON (a.manager_id = cte.employee_id) -- 递归查询,找出以递归公用表表达式的人为领导的人16) 17SELECT employee_id,last_name FROM cte WHERE n >= 3;
第三节 内置函数
1. 数值函数和字符串函数
1) Mysql字符串拼接只能用
concat函数,不能用||或+号拼接,但是可以输入多个参数,如:select concat('A','B','C')。2) Mysql不支持trunc、initcap和lengthb函数,并且length函数执行结果和Oracle不一致(Oracle返回字符数,Mysql返回字节数)。
3) Mysql的子串截取函数,除了substr外,还可以用substring,功能和参数含义相同。
4) 关于instr的区别:Mysql中instr('','')返回1,而Oracle中将''视为null,返回null。
5) 关于substr的区别:Mysql中substr('abc',0,1)返回'',而Oracle中与substr('abc',1,1)效果一致,都返回'a'。
71-- 字符串拼接2mysql> select concat('a','b','c') c1, concat_ws('|','a','b','c') c2;3+------+-------+4| c1 | c2 |5+------+-------+6| abc | a|b|c |7+------+-------+
2. 日期时间函数
621-- 1. 当前日期时间2-- 其中SYSDATE()获取的是动态实时时间,其它的获取的是SQL语句执行开始的时间3SELECT CURDATE() 当前日期01, CURRENT_DATE 当前日期02, DATE(NOW()) 当前日期03, 4 CURTIME() 当前时间01, CURRENT_TIME 当前时间02, 5 NOW() 当前日期时间01, CURRENT_TIMESTAMP 当前日期和时间02, CURRENT_TIMESTAMP() 当前日期和时间03, 6 SYSDATE() 实时日期和时间 FROM DUAL;7+------------+------------+------------+------------+------------+---------------------+---------------------+---------------------+---------------------+8| 当前日期01 | 当前日期02 | 当前日期03 | 当前时间01 | 当前时间02 | 当前日期时间01 | 当前日期和时间02 | 当前日期和时间03 | 实时日期和时间 |9+------------+------------+------------+------------+------------+---------------------+---------------------+---------------------+---------------------+10| 2023-11-13 | 2023-11-13 | 2023-11-13 | 18:25:50 | 18:25:50 | 2023-11-13 18:25:50 | 2023-11-13 18:25:50 | 2023-11-13 18:25:50 | 2023-11-13 18:25:50 |11+------------+------------+------------+------------+------------+---------------------+---------------------+---------------------+---------------------+12
13
14-- 2. 日期运算15select date_add(now(), INTERVAL 70 YEAR ); -- 增加70年 2093-11-13 18:31:1316SELECT DATEDIFF(CURDATE(), ENTRYDATE) AS '相差天数' FROM EMP; -- 获取两个日期相差的天数(参数1-参数2)17SELECT TIMESTAMPDIFF(YEAR, ENTRYDATE, CURDATE()) 相差年数,18 TIMESTAMPDIFF(MONTH, ENTRYDATE, CURDATE()) 相差月数,19 TIMESTAMPDIFF(DAY, ENTRYDATE, CURDATE()) 相差天数,20 TIMESTAMPDIFF(HOUR, ENTRYDATE, CURDATE()) 相差时数,21 TIMESTAMPDIFF(MINUTE, ENTRYDATE, CURDATE()) 相差分数,22 TIMESTAMPDIFF(SECOND, ENTRYDATE, CURDATE()) 相差秒数23 FROM EMP; -- 获取两个时间相差的年月日时分秒(参数2-参数1)24+----------+----------+----------+----------+----------+-----------+25| 相差年数 | 相差月数 | 相差天数 | 相差时数 | 相差分数 | 相差秒数 |26+----------+----------+----------+----------+----------+-----------+27| 18 | 226 | 6890 | 165360 | 9921600 | 595296000 |28| 18 | 226 | 6890 | 165360 | 9921600 | 595296000 |29+----------+----------+----------+----------+----------+-----------+30
31-- 3. 提取年月日时分秒32-- 方式一:33SELECT YEAR(now()) 年, MONTH(now()) 月, DAY(now()) 日, 34 HOUR(now()) 时, MINUTE(now()) 分, SECOND(now()) 秒,35 QUARTER(now()) 季度, WEEKDAY(now()) 第几周, DAYOFWEEK(now()) 第几周,36 WEEK(now()) 该年第几周, DAYOFYEAR(now()) 该年第几天, DAYOFMONTH(now()) 该月第几天37FROM DUAL; -- -6138+------+------+------+------+------+------+------+--------+--------+------------+------------+------------+39| 年 | 月 | 日 | 时 | 分 | 秒 | 季度 | 第几周 | 第几周 | 该年第几周 | 该年第几天 | 该月第几天 |40+------+------+------+------+------+------+------+--------+--------+------------+------------+------------+41| 2023 | 12 | 2 | 14 | 13 | 26 | 4 | 5 | 7 | 48 | 336 | 2 |42+------+------+------+------+------+------+------+--------+--------+------------+------------+------------+43-- WEEKDAY(now())中周1是0,周2是1,。。。周日是644-- DAYOFWEEK(date)中周日是1,周一是2,。。。周六是745
46-- 方式二:47SELECT EXTRACT(MINUTE FROM NOW()) 分钟, EXTRACT( WEEK FROM NOW()) 周,48 EXTRACT( QUARTER FROM NOW()) 季度 ,EXTRACT( MINUTE_SECOND FROM NOW()) 分钟和秒值49 FROM DUAL;50+------+------+------+------------+51| 分钟 | 周 | 季度 | 分钟和秒值 |52+------+------+------+------------+53| 17 | 48 | 4 | 1722 |54+------+------+------+------------+55
56-- 4. 时间戳57mysql> SELECT UNIX_TIMESTAMP(), UNIX_TIMESTAMP(CURDATE()) FROM DUAL;58+------------------+---------------------------+59| UNIX_TIMESTAMP() | UNIX_TIMESTAMP(CURDATE()) |60+------------------+---------------------------+61| 1701497216 | 1701446400 |62+------------------+---------------------------+
3. 类型转换函数
251-- 1. 数值转字符串2SELECT CAST(12345 AS CHAR) 使用CAST转换, CONVERT(12345, CHAR) 使用CONVERT转换, 3 CONCAT('Number: ', 12345) 使用CONCAT隐式转换, FORMAT(12345, 0) 使用FORMAT格式化为整数 4 FROM DUAL;5
6-- 2. 字符串转数值7SELECT CAST('12345' AS SIGNED) 使用CAST转换, CONVERT('12345', SIGNED) 使用CONVERT转换, 8 '12345'+1 使用加号隐式转换 FROM DUAL;9
10-- 3. DATETIME转字符串11SELECT DATE_FORMAT(NOW(),'%Y-%m-%d %H:%i:%s') FROM DUAL; -- 2023-11-13 18:57:0512
13-- 4. 字符串转DATETIME14SELECT STR_TO_DATE('2022-04-13 10:29:47','%Y-%m-%d %H:%i:%s') FROM DUAL;15
16-- 5. ASCII码和CHAR转换17SELECT ASCII('a'),CHR(97) FROM DUAL; -- 仅支持ASCII函数,不支持CHR函数,但有一个类似的ORD函数(能将65转为57)。18
19-- 6. 时间戳转换20SELECT UNIX_TIMESTAMP('2011-11-11 11:11:11') 字符串转时间戳, FROM_UNIXTIME(1576380910) 时间戳转字符串 FROM DUAL;21+----------------+---------------------+22| 字符串转时间戳 | 时间戳转字符串 |23+----------------+---------------------+24| 1320981071 | 2019-12-15 11:35:10 |25+----------------+---------------------+注意:
Mysql字符串转数值转换失败时不会报错,如CAST('中' AS SIGNED)和'中'+1分别返回0和1,而Oracle中会报“无效数字”错误。
4. 窗口函数
1) 窗口函数简介
窗口函数可以对数据进行分组,不同的是,分组操作会把分组的结果聚合成一条记录,而窗口函数是将结果置于每一条数据记录中。
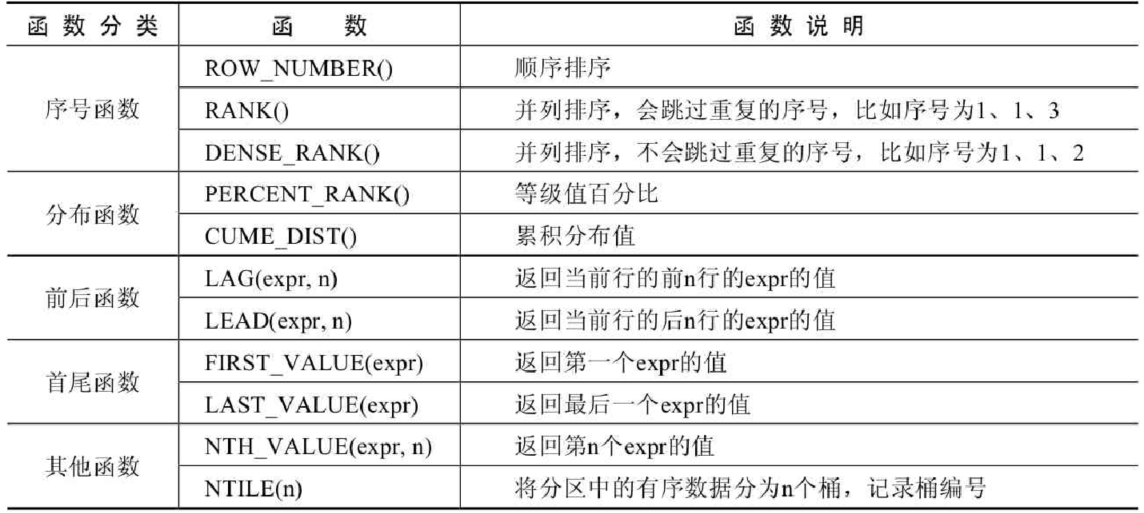
窗口函数的语法结构是:
81-- 语法格式2-- OVER关键字:指定函数窗口的范围,如果为空时,则包含满足WHERE条件的所有记录3-- 窗口名:为窗口设置一个别名,用来标识窗口4-- PARTITION BY子句:指定窗口函数按照哪些字段进行分组。分组后,窗口函数可以在每个分组中分执行。5-- ORDER BY子句:指定窗口函数按照哪些字段进行排序。执行排序操作使窗口函数按照排序后的数据记录的顺序进行编号。6-- FRAME子句:为分区中的某个子集定义规则,可以用来作为滑动窗口使用。7函数 OVER ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])8函数 OVER 窗口名 其它语句 WINDOW 窗口名 AS ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])注意:
MySQL从8.0版本开始支持窗口函数,文档地址为Window Function Descriptions。
窗口函数可以分为 静态窗口函数 和 动态窗口函数 。
静态窗口函数的窗口大小是固定的,不会因为记录的不同而不同;
动态窗口函数的窗口大小会随着记录的不同而变化。
2) 求和函数
311-- 数据2CREATE TABLE sales(3id INT PRIMARY KEY AUTO_INCREMENT,4city VARCHAR(15),5county VARCHAR(15),6sales_value DECIMAL7);8INSERT INTO sales(city,county,sales_value)9VALUES10('北京','海淀',10.00),11('北京','朝阳',20.00),12('上海','黄埔',30.00),13('上海','长宁',10.00);14
15-- 计算这个网站在每个城市的销售总额、在全国的销售总额、每个区的销售额占所在城市销售额中的比率,以及占总销售额中的比率16SELECT city AS 城市,county AS 区,sales_value AS 区销售额,17 SUM(sales_value) OVER(PARTITION BY city) AS 市销售额, -- 计算市销售额18 sales_value/SUM(sales_value) OVER(PARTITION BY city) AS 市比率,19 SUM(sales_value) OVER() AS 总销售额, -- 计算总销售额20 sales_value/SUM(sales_value) OVER() AS 总比率21 FROM sales22 ORDER BY city,county;23+------+------+----------+----------+--------+----------+--------+24| 城市 | 区 | 区销售额 | 市销售额 | 市比率 | 总销售额 | 总比率 |25+------+------+----------+----------+--------+----------+--------+26| 上海 | 长宁 | 10 | 40 | 0.2500 | 70 | 0.1429 |27| 上海 | 黄埔 | 30 | 40 | 0.7500 | 70 | 0.4286 |28| 北京 | 朝阳 | 20 | 30 | 0.6667 | 70 | 0.2857 |29| 北京 | 海淀 | 10 | 30 | 0.3333 | 70 | 0.1429 |30+------+------+----------+-----------+--------+----------+--------+314 rows in set (0.00 sec)
3) 序号函数
361-- 数据2CREATE TABLE goods(3id INT PRIMARY KEY AUTO_INCREMENT,4category_id INT,5category VARCHAR(15),6NAME VARCHAR(30),7price DECIMAL(10,2),8stock INT,9upper_time DATETIME10);11INSERT INTO goods(category_id,category,NAME,price,stock,upper_time)12VALUES13(1, '女装/女士精品', 'T恤', 39.90, 1000, '2020-11-10 00:00:00'),14(1, '女装/女士精品', '连衣裙', 79.90, 2500, '2020-11-10 00:00:00'),15(1, '女装/女士精品', '卫衣', 89.90, 1500, '2020-11-10 00:00:00'),16(1, '女装/女士精品', '牛仔裤', 89.90, 3500, '2020-11-10 00:00:00'),17(1, '女装/女士精品', '百褶裙', 29.90, 500, '2020-11-10 00:00:00'),18(1, '女装/女士精品', '呢绒外套', 399.90, 1200, '2020-11-10 00:00:00'),19(2, '户外运动', '自行车', 399.90, 1000, '2020-11-10 00:00:00'),20(2, '户外运动', '山地自行车', 1399.90, 2500, '2020-11-10 00:00:00'),21(2, '户外运动', '登山杖', 59.90, 1500, '2020-11-10 00:00:00'),22(2, '户外运动', '骑行装备', 399.90, 3500, '2020-11-10 00:00:00'),23(2, '户外运动', '运动外套', 799.90, 500, '2020-11-10 00:00:00'),24(2, '户外运动', '滑板', 499.90, 1200, '2020-11-10 00:00:00');25
26-- 查询 goods 数据表中每个商品分类下价格最高的3种商品信息27-- ROW_NUMBER() RANK() DENSE_RANK() 分别表示三种编号策略28SELECT * FROM ( 29 SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num123, 30 RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num113,31 SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num112,32 id, category_id, category, NAME, price, stock33 FROM goods34) t35 WHERE row_num123 <= 3;36
4) 分布函数
121-- 计算rank()值百分比,即(rank()-1)/(当前窗口总记录数-1)2SELECT RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS r,3 PERCENT_RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS pr,4 id, category_id, category, NAME, price, stock5 FROM goods6 WHERE category_id = 1;7
8-- 查询小于或等于当前价格的比例9SELECT CUME_DIST() OVER(PARTITION BY category_id ORDER BY price ASC) AS cd,10 id, category, NAME, price11 FROM goods;12
5) 前后函数
161-- 查询前1个商品价格与当前商品价格的差值2SELECT id, category, NAME, price, pre_price, price - pre_price AS diff_price3 FROM (4 SELECT id, category, NAME, price,LAG(price,1) OVER w AS pre_price5 FROM goods6 WINDOW w AS (PARTITION BY category_id ORDER BY price)7 ) t;8 9-- 后1个商品价格与当前商品价格的差值10SELECT id, category, NAME, behind_price, price,behind_price - price AS diff_price11 FROM(12 SELECT id, category, NAME, price,LEAD(price, 1) OVER w AS behind_price13 FROM goods 14 WINDOW w AS (PARTITION BY category_id ORDER BY price)15 ) t;16
6) 首尾函数
101-- 按照价格排序,查询第1个商品的价格信息2SELECT id, category, NAME, price, stock,FIRST_VALUE(price) OVER w AS first_price3 FROM goods 4WINDOW w AS (PARTITION BY category_id ORDER BY price);5
6-- 按照价格排序,查询最后一个商品的价格信息7SELECT id, category, NAME, price, stock,LAST_VALUE(price) OVER w AS last_price8 FROM goods 9WINDOW w AS (PARTITION BY category_id ORDER BY price);10
7) 其它窗口函数
121-- 查询goods数据表中排名第2和第3的价格信息2SELECT id, category, NAME, price,3 NTH_VALUE(price,2) OVER w AS second_price,4 NTH_VALUE(price,3) OVER w AS third_price5 FROM goods 6WINDOW w AS (PARTITION BY category_id ORDER BY price);7
8-- 将goods表中的商品按照价格分为3组9-- NTILE(n)函数将分区中的有序数据分为n个桶,记录桶编号10SELECT NTILE(3) OVER w AS nt,id, category, NAME, price11 FROM goods 12WINDOW w AS (PARTITION BY category_id ORDER BY price);
5. 其它函数
241-- NULL值转换函数2SELECT IFNULL(NULL,'DEFAULT') FROM DUAL; -- 参数1为空则返回参数2,否则返回参数1 Default3
4-- 分组拼接函数 5select age,group_concat(id) from t01 group by age; -- 以age分组拼接id字段(默认以”,“号连接)6select age,group_concat(id separator '|') from t01 group by age; -- 以”|“进行连接7select age,group_concat(distinct id) from t01 group by age; -- 去掉重复值再拼接8select age,group_concat(distinct id order by id desc) from t01 group by age; -- 按age降序拼接9
10-- 加解密函数11SELECT PASSWORD('123456') 不可逆密文, md5('123456') MD5值, SHA('123456') SHA值,12 ENCODE('123456','盐') , DECODE('密文','yan'); -- 测试报错13 14# 查询系统信息15# 查询数据也可用SCHEMA(),查询系统用户也可用 SYSTEM_USER() SESSION_USER()16SELECT VERSION() 版本号, CONNECTION_ID() 连接数, DATABASE() 数据库, 17 CURRENT_USER() 当前用户, USER() 系统用户,18 CHARSET('ABC') 字符集, COLLATION('ABC') 比较规则19 FROM DUAL;20+--------+--------+--------+----------+--------------------+--------+----------------+21| 版本号 | 连接数 | 数据库 | 当前用户 | 系统用户 | 字符集 | 比较规则 |22+--------+--------+--------+----------+--------------------+--------+----------------+23| 8.0.16 | 37976 | test01 | root@% | root@121.15.156.10 | gbk | gbk_chinese_ci |24+--------+--------+--------+----------+--------------------+--------+----------------+注意:
group_concat()最多拼接1024字节数据,可通过参数进行修改:
31SET SESSION group_concat_max_len = 18446744073709551615;2set global max_allowed_packet = 2*1024*1024*10;3```## 第05章_性能优化
第一节 SQL性能分析
1. SQL执行频率
根据SQL执行频率可以判断当前数据库是以增删改为主,还是以查询为主。
211-- 查询全局SQL执行频率2SHOW GLOBAL STATUS LIKE 'Com_______';3+---------------+-------+4| Variable_name | Value |5+---------------+-------+6| Com_binlog | 0 |7| Com_commit | 5 |8| Com_delete | 1 |9| Com_import | 0 |10| Com_insert | 10 |11| Com_repair | 0 |12| Com_revoke | 0 |13| Com_select | 949 |14| Com_signal | 0 |15| Com_update | 44 |16| Com_xa_end | 0 |17+---------------+-------+18
19-- 查询当前会话SQL执行频率20SHOW SESSION STATUS LIKE 'Com_______';21
2. 查询日志
查询日志记录了客户端的所有操作语句,且包括二进制日志不包含的DQL语句。
141-- 开启查询日志2-- 修改MySQL的配置文件(/etc/my.cnf),然后通过命令 systemctl restart mysqld 重启后生效 3general_log=1 # 开启查询日志(默认为0)4general_log_file=mysql_query.log # 查询日志文件名 (默认为host_name.log)5
6-- 查看查询日志是否开启7mysql> show variables like '%general_log%';8+------------------+-----------------------------------+9| Variable_name | Value |10+------------------+-----------------------------------+11| general_log | OFF |12| general_log_file | /var/lib/mysql/VM-12-4-centos.log |13+------------------+-----------------------------------+14
注意:
查询日志默认关闭,需要修改配置并重启服务器后才能打开。
如果长时间高频执行SQL语句,该日志文件将会非常大。
3. 慢查询日志
慢查询日志记录了执行时间超过 long_query_time 且扫描记录数不小于min_examined_row_limit 的SQL语句。
291-- 开启慢查询日志2-- 修改MySQL的配置文件(/etc/my.cnf),然后通过命令 systemctl restart mysqld 重启后生效 3slow_query_log=1 # 打开慢查询日志开关(默认为0)4long_query_time=2 # 设置慢查询记录阈值为2s(默认为10s)5log_slow_admin_statements =1 # 记录执行较慢的管理语句(默认为0)6log_queries_not_using_indexes = 1 # 记录执行较慢的未使用索引的语句(默认为0)7
8
9-- 查询慢查询日志是否打开10mysql> show variables like 'slow_query_log';11+----------------+-------+12| Variable_name | Value |13+----------------+-------+14| slow_query_log | OFF |15+----------------+-------+16
17
18-- 查询慢查询记录阈值19mysql> show variables like 'long_query_time';20+-----------------+-----------+21| Variable_name | Value |22+-----------------+-----------+23| long_query_time | 10.000000 |24+-----------------+-----------+25
26
27-- 查看慢查询日志28[root@localhost mysql]# tail -f /var/lib/mysql/localhost-slow.log29
注意:
慢查询日志默认关闭,需要修改配置并重启服务器后才能打开。
慢查询日志默认不记录管理语句和未使用索引的语句,需要修改配置打开。
4. 明细耗时(profile)
profile能够记录SQL语句各详细步骤的执行耗时。
1191-- 查询是否支持profile2mysql> SELECT @@have_profiling;3+------------------+4| @@have_profiling |5+------------------+6| YES |7+------------------+8
9
10-- 查询是否打开profile11mysql> select @profiling;12+------------+13| @profiling |14+------------+15| NULL |16+------------+17
18
19-- 打开profile(当前会话有效)20SET profiling = 1; 21
22
23-- 执行业务查询24mysql> select * from EMP;25+------+--------+--------+--------+------+--------------------+------------+26| ID | WORKNO | NAME | GENDER | AGE | IDCARD | ENTRYDATE |27+------+--------+--------+--------+------+--------------------+------------+28| 3 | 3 | 韦一笑 | 男 | 38 | 123456789012345670 | 2005-01-01 |29| 4 | 4 | 赵敏 | 女 | 18 | 123456789012345670 | 2005-01-01 |30+------+--------+--------+--------+------+--------------------+------------+31
32
33-- 查看基本耗时情况34mysql> show profiles;35+----------+------------+-------------------+36| Query_ID | Duration | Query |37+----------+------------+-------------------+38| 1 | 0.00017125 | select @profiling |39| 2 | 0.00039850 | select * from EMP |40+----------+------------+-------------------+41
42
43-- 查看某个查询的各步骤耗时44mysql> show profile for query 2;45+--------------------------------+----------+46| Status | Duration |47+--------------------------------+----------+48| starting | 0.000071 |49| Executing hook on transaction | 0.000011 |50| starting | 0.000010 |51| checking permissions | 0.000008 |52| Opening tables | 0.000129 |53| init | 0.000009 |54| System lock | 0.000009 |55| optimizing | 0.000006 |56| statistics | 0.000012 |57| preparing | 0.000015 |58| executing | 0.000004 |59| Sending data | 0.000044 |60| end | 0.000004 |61| query end | 0.000004 |62| waiting for handler commit | 0.000021 |63| closing tables | 0.000007 |64| freeing items | 0.000018 |65| cleaning up | 0.000017 |66+--------------------------------+----------+67
68
69-- 查询某个查询CPU花费70mysql> show profile cpu for query 2;71+--------------------------------+----------+----------+------------+72| Status | Duration | CPU_user | CPU_system |73+--------------------------------+----------+----------+------------+74| starting | 0.000071 | 0.000024 | 0.000040 |75| Executing hook on transaction | 0.000011 | 0.000004 | 0.000007 |76| starting | 0.000010 | 0.000003 | 0.000006 |77| checking permissions | 0.000008 | 0.000004 | 0.000006 |78| Opening tables | 0.000129 | 0.000047 | 0.000081 |79| init | 0.000009 | 0.000003 | 0.000005 |80| System lock | 0.000009 | 0.000004 | 0.000006 |81| optimizing | 0.000006 | 0.000002 | 0.000003 |82| statistics | 0.000012 | 0.000004 | 0.000008 |83| preparing | 0.000015 | 0.000006 | 0.000009 |84| executing | 0.000004 | 0.000001 | 0.000003 |85| Sending data | 0.000044 | 0.000017 | 0.000027 |86| end | 0.000004 | 0.000001 | 0.000003 |87| query end | 0.000004 | 0.000001 | 0.000002 |88| waiting for handler commit | 0.000021 | 0.000000 | 0.000022 |89| closing tables | 0.000007 | 0.000000 | 0.000006 |90| freeing items | 0.000018 | 0.000000 | 0.000019 |91| cleaning up | 0.000017 | 0.000000 | 0.000016 |92+--------------------------------+----------+----------+------------+93
94
95-- 查询各步骤对应的源代码位置96mysql> show profile source for query 2;97+--------------------------------+----------+-------------------------+----------------------+-------------+98| Status | Duration | Source_function | Source_file | Source_line |99+--------------------------------+----------+-------------------------+----------------------+-------------+100| starting | 0.000071 | NULL | NULL | NULL |101| Executing hook on transaction | 0.000011 | launch_hook_trans_begin | rpl_handler.cc | 1106 |102| starting | 0.000010 | launch_hook_trans_begin | rpl_handler.cc | 1108 |103| checking permissions | 0.000008 | check_access | sql_authorization.cc | 2202 |104| Opening tables | 0.000129 | open_tables | sql_base.cc | 5587 |105| init | 0.000009 | execute | sql_select.cc | 661 |106| System lock | 0.000009 | mysql_lock_tables | lock.cc | 332 |107| optimizing | 0.000006 | optimize | sql_optimizer.cc | 213 |108| statistics | 0.000012 | optimize | sql_optimizer.cc | 423 |109| preparing | 0.000015 | optimize | sql_optimizer.cc | 497 |110| executing | 0.000004 | exec | sql_executor.cc | 228 |111| Sending data | 0.000044 | exec | sql_executor.cc | 304 |112| end | 0.000004 | execute | sql_select.cc | 714 |113| query end | 0.000004 | mysql_execute_command | sql_parse.cc | 4520 |114| waiting for handler commit | 0.000021 | ha_commit_trans | handler.cc | 1533 |115| closing tables | 0.000007 | mysql_execute_command | sql_parse.cc | 4566 |116| freeing items | 0.000018 | mysql_parse | sql_parse.cc | 5237 |117| cleaning up | 0.000017 | dispatch_command | sql_parse.cc | 2147 |118+--------------------------------+----------+-------------------------+----------------------+-------------+119
5. 执行计划(explain)
explain可以获取某SQL的执行计划,包括如何提取数据、如何进行表连接、如何过滤数据等。
111-- 获取执行计划2mysql> explain select DISTINCT A.ID,A.NAME,B.STATUS FROM EMP A LEFT JOIN TB_USER B ON A.ID = B.ID WHERE A.ID > (select min(ID) FROM EMP C);3+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+4| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |5+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+6| 1 | PRIMARY | A | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where; Using temporary |7| 1 | PRIMARY | B | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) |8| 2 | SUBQUERY | C | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | NULL |9+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+103 rows in set, 1 warning (0.01 sec)11
执行计划中各字段的简要说明如下:
1) id:执行顺序,值越大越先执行,值相等则从上往下。
2) select_type:操作类型,常见的有:
PRIMARY:主查询,即最外层的查询
SIMPLE:简单表查询,即不用连接或子查询
UNION:UNION中第二个或之后的语句
SUBQUERY:SELECT/FROM/WHERE等后包含的子查询
Dependent subquery:依赖于外查询的子查询
3) table:操作的表或视图。
4) partitions:操作的分区。
5) type:表连接类型,性能从好到差依次为:
NULL:不需要访问表结构或索引直接得到结果
system/const:根据主键或唯一索引进行查询。
eq_ref:多表连接中,使用主键或唯一索引进行查询。
ref:使用非唯一索引或唯一索引前缀进行查询。
range:对索引树进行范围扫描。
index:遍历索引树。
ALL:全表扫描
6) possible_key:可能会使用的索引。
7) key:实际将使用的索引。
8) key_len:索引中可能使用的字节数,在不损失精确性的前提下,长度越短越好。
9) rows:预估要执行查询的行数。
10) filtered:返回结果的行数占需读取行数的百分比,值越大越好。
11) Extra:其它关键信息:
Using filesort:在没有索引的列上进行排序。
Using index:不需要回表。
Using where:部分条件不在索引中。
Using temporary:使用临时表来存储结果集,常用于分组。
第二节 合理使用索引
1. 索引存储结构
索引按存储结构可分为B+树索引、哈希(Hash)索引、全文(FullText)索引、R-Tree(空间索引)等,不同存储引擎的支持情况如下:
| 索引结构类型\引擎类型 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 支持 | ||
| FullText索引(倒排索引) | 支持(Mysql5.6+) | 支持 | |
| R-tree(空间索引) | 支持 |
1) B+Tree索引
MySql中的B+Tree索引从二叉树=>红黑树(自平衡二叉树)=>B-Tree(非叶子节点也存储数据的多叉树)=>B+Tree(仅叶子节点存储数据的多叉树,且叶子节点使用单向链表连接)一路发展而来,解决了二叉树顺序插入退化为链表的问题,解决了红黑树大数据量下层级较深的问题,解决了B-tree非叶子节点存储数据的问题,解决了B+Tree无反向链表不方便范围查找的问题,结构图示意如下:
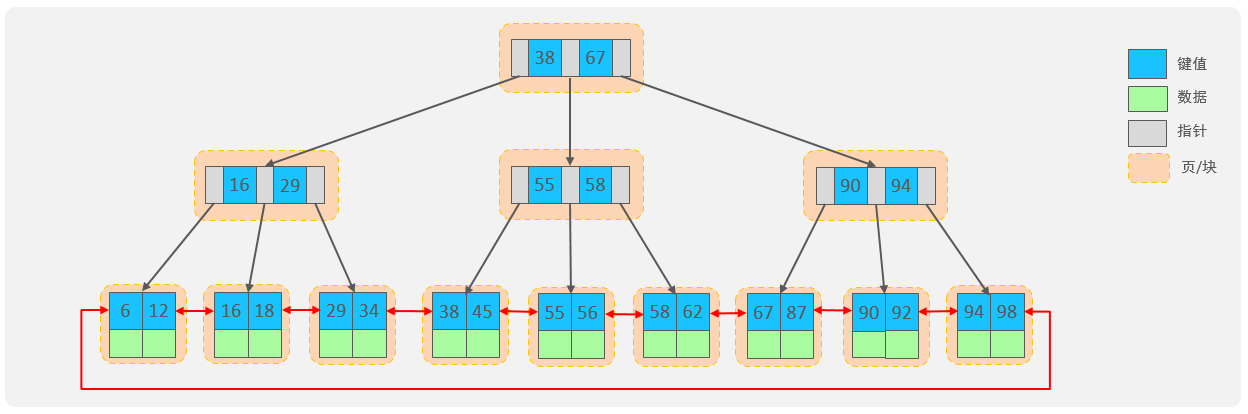
扩展:如何预估B+Tree索引的高度?
答:在B+Tree索引中,一个结点有一页的空间,而在InnoDB引擎中,一页的大小默认为16k,一个指针的大小为6字节,假设主键为BIGINT类型,占8个字节,则一个非叶子结点可以存储16*1024/(6+8)=1170个索引指针,那么可以算出两层最大支持1*1170页数据,三层最多支持1*1170*1170=1,368,900页数据,当一行数据为1k时,大约为1368900*16k/1k=2200万行。
2) Hash索引
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
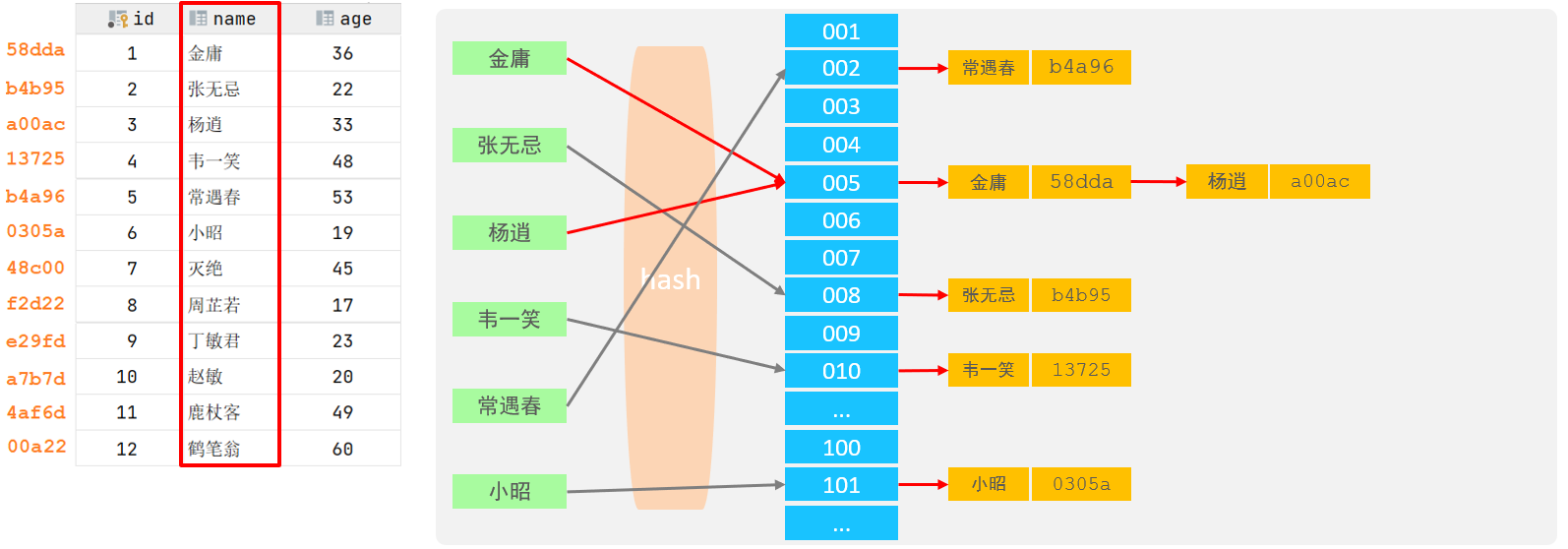
注意:
Hash索引查询效率非常高,通常只需要一次检索就可以了(不存在hash冲突的情况),效率通常要高于B+tree索引。
但是Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,...),且无法利用索引完成排序操作。
3) FullText索引
全文索引是通过倒排索引来实现的,类似ElasticSearch等搜索引擎的实现,对在大文本中检索关键词的场景非常有效。
4) 关于聚集索引
在InnoDB引擎中,B+树索引根据索引块和数据块存放的位置,将其分为聚集索引和二级索引。
聚集索引:基于数据块建立的索引,有且只有一个,一般就是主键索引或第一个唯一索引,如果两者都没有,则会自动生成一个rowid作为隐藏的聚集索引。
二级索引:基于索引列建立的索引,可以存在多个,使用该类索引进行查询时可能出现回表查询(即通过索引指向的主键再次查找索引列之外的字段)。
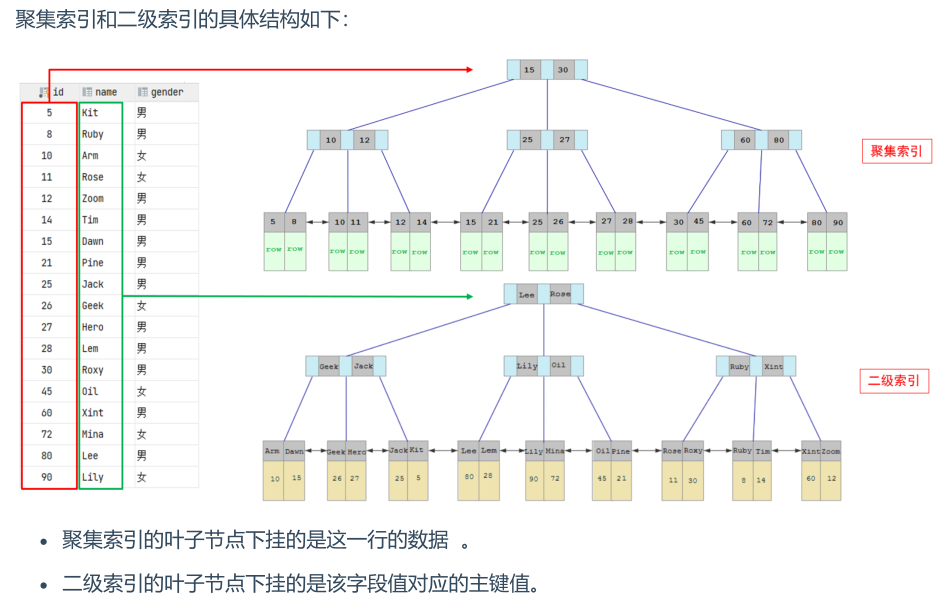
2. 添加索引提示
91-- 建议Mysql优化器使用指定索引2explain select * from tb_user use index(idx_user_pro) where profession = '软件工程';3
4-- 建议Mysql优化器不适用指定索引5explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工程';6
7-- 强制使用指定索引8explain select * from tb_user force index(idx_user_pro) where profession = '软件工程';9
3. 索引设计原则
1) 针对于数据量较大,且查询比较频繁的表建立索引。
2) 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3) 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
4) 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
5) 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6) 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
7) 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
第三节 特殊场景优化
1. 主键优化
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT)。

由于一页的存储空间有限,当主键乱序插入或执行删除操作时,就可能出现页分裂或页合并。因此在满足业务需要的情况下,尽量使用自增主键,防止插入时出现页分裂,并降低主键长度,以便一页中能够存储更多的主键,同时,也应该尽量避免对主键进行修改。
2. 插入优化
91-- 1. 数据量小时选择批量插入语句(使用非自动提交和主键按序插入性能更高)2Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry'); 3
4
5-- 2. 大数据量时选择Load命令加载6mysql –-local-infile -u root -p -- 客户端连接时添加-–local-infile参数7set global local_infile = 1; -- 打开从本地加载文件导入数据的开关8load data local infile '/root/sql01.log' into table tb_user fields terminated by ',' lines terminated by '\n' ; -- 执行load命令加载9
3. 排序和分组优化
排序和分组都可以使用索引,但要保证符合最左前缀法则。当使用索引进行排序时,执行计划中将显示Using index,否则将显示Using filesort,表示在排序缓冲区或文件排序。当分组未使用到索引时,执行计划中也会出现Using temporary等类似字样。
4. 分页优化
使用Limit进行分页查询时,页数越大则查询越慢,因为要对前M*N条数据进行额外的排序,可以通过两层查询或业务键限制优化。
61-- 两层查询2select * from tb_sku t , (select id from tb_sku order by id limit 2000000,10) a where t.id = a.id;3
4-- 业务键限制5select * from tb_sku t where id > xxxxxx order by id limit 10; -- id >= xxxxxx中xxxxxx应为上一页查询返回的最大id6
5. COUNT优化
在InnoDB引擎中,按效率排序为:COUNT(*) ≈ COUNT(1) > COUNT(主键) > COUNT(普通字段)。
特殊的,使用Count(*)时InnoDB引擎会在服务层直接按行进行累加。
6. UPDATE优化
在InnoDB引擎中,更新操作是对索引加锁的(Orace是对数据行加锁的),如果WHERE条件不存在索引,则会升级为表锁。
61-- id有索引,则在id索引上加锁,为行锁2update course set name = 'javaEE' where id = 1; 3
4-- name无索引,则无法在索引上加锁,升级为表锁5update course set name = 'SpringBoot' where name = 'PHP';6
第06章_过程操作
第一节 存储过程
1. 基本语法
221-- 查看所有存储过程2SELECT * FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA = 'test01';3
4-- 查看存储过程定义5SHOW CREATE PROCEDURE P_TEST01;6
7-- 创建存储过程8DELIMITER //9CREATE PROCEDURE P_TEST01(IN EMP_ID INT, OUT EMP_NAME VARCHAR(32))10BEGIN11 SELECT NAME INTO EMP_NAME FROM EMP WHERE ID = EMP_ID;12END;13//14DELIMITER ;15
16-- 调用存储过程17CALL P_TEST01(3,@EMP_RESULT);18SELECT @EMP_RESULT;19
20-- 删除存储过程21DROP PROCEDURE IF EXISTS P_TEST01;22
注意:
在命令行执行存储过程时,需通过
DELIMITER //执行存储过程结束符。在声明参数变量时,一般不加
@符号
2. 变量
在MySQL中变量分为三种类型: 系统变量(全局变量+会话变量)、用户定义变量、局部变量。
1) 系统变量
系统变量是MySQL服务器层面的变量,又分为全局变量(对所有会话生效)和会话变量(仅当前会话生效),命名一般以@@开头。
131-- 命令方式使用2set session autocommit = 1;3set global autocommit = 1;4show session variables like 'auto%';5show global variables like 'auto%';6
7
8-- @@方式使用9set @@global.autocommit = 1;10set @@session.autocommit = 1;11select @@global.autocommit;12select @@session.autocommit;13
注意:
如果没有指定SESSION或GLOBAL,则默认是SESSION变量。
mysql服务重新启动之后,所设置的全局参数会失效,要想不失效,可以在 /etc/my.cnf 中配置。
2) 用户定义变量
用户可以根据需要自己定义变量,用户变量不用提前声明,以@变量名格式直接使用即可,其作用域为当前连接。
81-- 变量赋值2set @myname = 'hyx', @myage := 18;3select @mycolor := 'red';4select count(*) into @mycount from tb_user;5
6-- 变量使用7select @myname,@myage;8
注意:
用户变量赋值使用
=和:=都可以。
3) 局部变量
局部变量一般用作存储过程的参数列表或内部变量,需要DECLARE显示声明,在其声明的BEGIN...END块内有效,一般不加@或@@。
局部变量的类型和数据库字段类型基本一致,包括INT、BIGINT、CHAR、VARCHAR、DATE、TIME等。
121DELIMITER //2CREATE PROCEDURE P2()3BEGIN4 DECLARE EMP_COUNT INT DEFAULT 0;5 SELECT COUNT(*) INTO EMP_COUNT FROM EMP;6 SELECT EMP_COUNT;7END;8//9DELIMITER ;10
11call p2();12
注意:
局部变量作为输入输出参数时,需要指明输入输出类型,可以是
IN、OUT、INOUT三种之一。
3. 流程控制
1) IF语句
221DELIMITER //2CREATE PROCEDURE P3()3BEGIN4 DECLARE SCORE INT DEFAULT 58;5 DECLARE RESULT VARCHAR(10);6 7 -- IF语句8 IF SCORE >= 85 THEN9 SET RESULT := '优秀';10 ELSEIF SCORE >= 60 THEN11 SET RESULT := '及格';12 ELSE13 SET RESULT := '不及格';14 END IF;15 16 SELECT RESULT;17END;18//19DELIMITER ;20
21CALL P3();22
2) CASE语句
391-- 语法格式12CASE case_value3 WHEN when_value1 THEN statement_list14 [ WHEN when_value2 THEN statement_list2] ...5 [ ELSE statement_list ]6END CASE;7
8-- 语法格式29CASE10 WHEN search_condition1 THEN statement_list111 [WHEN search_condition2 THEN statement_list2] ...12 [ELSE statement_list]13END CASE;14
15-- 示例:16DELIMITER //17CREATE PROCEDURE P6(IN MONTH INT)18BEGIN19 DECLARE RESULT VARCHAR(10);20CASE21 WHEN MONTH >= 1 AND MONTH <= 3 THEN22 SET RESULT := '第一季度';23 WHEN MONTH >= 4 AND MONTH <= 6 THEN24 SET RESULT := '第二季度';25 WHEN MONTH >= 7 AND MONTH <= 9 THEN26 SET RESULT := '第三季度';27 WHEN MONTH >= 10 AND MONTH <= 12 THEN28 SET RESULT := '第四季度';29 ELSE30 SET RESULT := '非法参数';31 END CASE ;32 33 SELECT CONCAT('您输入的月份为: ',MONTH, ', 所属的季度为: ',RESULT);34END;35//36DELIMITER ;37 38CALL P6(8);39
3) WHILE语句
171DELIMITER //2CREATE PROCEDURE P7(IN n INT)3BEGIN4 DECLARE TOTAL INT DEFAULT 0;5 6 WHILE n>0 DO7 SET TOTAL := TOTAL + n;8 SET n := n - 1;9 END WHILE;10 11 SELECT TOTAL;12END;13//14DELIMITER ;15
16CALL P7(100);17
4) REPEAT语句
191DELIMITER //2CREATE PROCEDURE P8(IN n INT)3BEGIN4 DECLARE TOTAL INT DEFAULT 0;5 6 REPEAT7 SET TOTAL := TOTAL + n;8 SET n := n - 1;9 UNTIL n <= 010 END REPEAT;11 12 SELECT TOTAL;13END;14//15DELIMITER ;16
17CALL P8(100);18
19
5) LOOP语句
501-- 示例12DELIMITER //3CREATE PROCEDURE P9(IN n INT)4BEGIN5 DECLARE TOTAL INT DEFAULT 0;6 7 SUM:LOOP8 IF n<=0 THEN9 LEAVE SUM;10 END IF;11 12 SET TOTAL := TOTAL + n;13 SET n := n - 1;14 END LOOP SUM;15 16 SELECT TOTAL;17END;18//19DELIMITER ;20
21CALL P9(100);22
23
24-- 示例2:演示ITERATE的用法25DELIMITER //26CREATE PROCEDURE P10(IN N INT)27BEGIN28 DECLARE TOTAL INT DEFAULT 0;29 30 SUM:LOOP31 IF N<=0 THEN32 LEAVE SUM;33 END IF;34 35 IF N%2 = 1 THEN36 SET N := N - 1;37 ITERATE SUM;38 END IF;39 40 SET TOTAL := TOTAL + N;41 SET N := N - 1;42 END LOOP SUM;43 44 SELECT TOTAL;45END;46//47DELIMITER ;48
49CALL P10(100);50
4. 游标
游标(CURSOR)是用来存储查询结果集的数据类型 , 在存储过程和函数中可以使用游标对结果集进行循环的处理。
311-- 注意:如下示例执行结果与预期不一致2DROP PROCEDURE IF EXISTS P12;3DELIMITER //4CREATE PROCEDURE P12(IN uage INT)5BEGIN6 DECLARE ID INT;7 DECLARE NAME VARCHAR(32);8 -- 1. 声明游标9 DECLARE u_cursor CURSOR FOR SELECT ID, NAME FROM EMP WHERE AGE <= uage;10 -- 2. 声明条件处理程序(当SQL语句执行抛出的状态码为02开头时,将关闭游标u_cursor,并退出)11 DECLARE EXIT HANDLER FOR NOT FOUND CLOSE u_cursor;12 13 -- 3. 打开游标14 OPEN u_cursor;15
16 WHILE TRUE DO17 -- 4. 提取游标记录18 FETCH u_cursor INTO ID, NAME;19 SELECT ID, NAME;20 INSERT INTO EMP_BAK VALUES (ID, NAME);21 END WHILE;22
23 -- 5. 关闭游标24 CLOSE u_cursor;25
26END;27//28DELIMITER ;29
30CALL P12(30);31
第二节 存储函数
存储函数是有返回值的存储过程,存储函数的参数只能是IN类型的。
1. 语法说明
71CREATE FUNCTION 存储函数名称 ([ 参数列表 ])2RETURNS type [characteristic ...]3BEGIN4 -- SQL语句5RETURN ...;6END ;7
关于characteristic说明:
DETERMINISTIC:相同的输入参数总是产生相同的结果。
NO SQL :不包含 SQL 语句。
READS SQL DATA:包含读取数据的语句,但不包含写入数据的语句。
注意:
在mysql8.0中默认开启binlog,这要求在定义存储过程时指定characteristic特性,否则会报错。
2. 简单示例
181DELIMITER //2CREATE FUNCTION FUN1(n INT)3RETURNS INT DETERMINISTIC4BEGIN5 DECLARE total INT DEFAULT 0;6 7 WHILE n>0 DO8 SET total := total + n;9 SET n := n - 1;10 END WHILE;11 12 RETURN total;13END;14//15DELIMITER ;16
17SELECT FUN1(50);18
第三节 触发器
1. 触发器简介
触发器是与表有关的数据库对象,指在insert/update/delete之前(BEFORE)或之后(AFTER),触发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性、 日志记录、数据校验等操作。
使用别名OLD和NEW来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。
| 触发器类型 | NEW 和 OLD |
|---|---|
| INSERT 型触发器 | NEW 表示将要或者已经新增的数据 |
| UPDATE 型触发器 | OLD 表示修改之前的数据 , NEW 表示将要或已经修改后的数据 |
| DELETE 型触发器 | OLD 表示将要或者已经删除的数据 |
注意:
Mysql8.0版本触发器还只支持行级触发,不支持语句级触发。
2. 语法说明
141-- 创建触发器2CREATE TRIGGER trigger_name3BEFORE/AFTER INSERT/UPDATE/DELETE4ON tbl_name FOR EACH ROW -- 行级触发器5BEGIN6 trigger_stmt ;7END;8
9-- 查看触发器10SHOW TRIGGERS ; 11
12-- 删除触发器13DROP TRIGGER IF EXISTS trigger_name;14
3. 简单示例
通过触发器记录 tb_user 表的数据变更日志,将变更日志插入到日志表user_logs中, 包含增加、修改、删除操作;
571-- 业务表2DROP TABLE IF EXISTS TB_USER;3CREATE TABLE TB_USER(4 ID INT(11) PRIMARY KEY AUTO_INCREMENT,5 NAME VARCHAR(32)6);7
8-- 创建日志表 9DROP TABLE IF EXISTS USER_LOGS;10CREATE TABLE USER_LOGS(11 ID INT(11) NOT NULL AUTO_INCREMENT,12 OPERATION VARCHAR(20) NOT NULL COMMENT '操作类型, INSERT/UPDATE/DELETE',13 OPERATE_TIME DATETIME NOT NULL COMMENT '操作时间',14 OPERATE_ID INT(11) NOT NULL COMMENT '操作的ID',15 OPERATE_PARAMS VARCHAR(500) COMMENT '操作参数',16 PRIMARY KEY(`ID`)17)ENGINE=INNODB DEFAULT CHARSET=UTF8;18
19
20-- INSERT触发器21DROP TRIGGER IF EXISTS TB_USER_INSERT_TRIGGER;22DELIMITER //23CREATE TRIGGER TB_USER_INSERT_TRIGGER24AFTER INSERT ON TB_USER FOR EACH ROW25BEGIN26 INSERT INTO USER_LOGS(ID, OPERATION, OPERATE_TIME, OPERATE_ID, OPERATE_PARAMS)27 VALUES (NULL, 'INSERT', NOW(), NEW.ID, CONCAT('插入的数据内容为:ID=',NEW.ID,',NAME=',NEW.NAME));28END;29//30DELIMITER ;31
32
33-- UPDATE触发器34DROP TRIGGER IF EXISTS TB_USER_UPDATE_TRIGGER;35DELIMITER //36CREATE TRIGGER TB_USER_UPDATE_TRIGGER37AFTER UPDATE ON TB_USER FOR EACH ROW38BEGIN39 INSERT INTO USER_LOGS(ID, OPERATION, OPERATE_TIME, OPERATE_ID, OPERATE_PARAMS)40 VALUES (NULL, 'UPDATE', NOW(), NEW.ID, CONCAT('更新之前的数据: ID=',OLD.ID,',NAME=',OLD.NAME,' | 更新之后的数据: ID=',NEW.ID,',NAME=',NEW.NAME));41END;42//43DELIMITER ;44
45
46-- DELETE触发器47DROP TRIGGER IF EXISTS TB_USER_DELETE_TRIGGER;48DELIMITER //49CREATE TRIGGER TB_USER_DELETE_TRIGGER50AFTER DELETE ON TB_USER FOR EACH ROW51BEGIN52 INSERT INTO USER_LOGS(ID, OPERATION, OPERATE_TIME, OPERATE_ID, OPERATE_PARAMS)53 VALUES (NULL, 'DELETE', NOW(), OLD.ID,CONCAT('删除之前的数据: ID=',OLD.ID,',NAME=',OLD.NAME));54END;55//56DELIMITER ;57
第07章_扩展提高
第一节 InnoDB引擎结构
1. 逻辑存储结构
InnoDB引擎的逻辑存储结构如下图所示:
1) 表空间:表空间是InnoDB存储引擎逻辑结构的最高层,一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。
如果用户启用了参数
innodb_file_per_table(在8.0版本中默认开启) ,则每张表都会有一个表空间文件xxx.ibd。
2) 段:分为数据段、索引段、回滚段,InnoDB是索引组织表,数据段就是B+树的叶子节点, 索引段即为B+树的非叶子节点。
3) 区: 表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为16K, 即一个区中一共有64个连续的页。
4) 页:磁盘管理的最小单元,每个页的大小默认为 16KB。为了保证页的连续性,InnoDB 存储引擎每次从磁盘申请 4-5 个区。
5) 行:数据是按行进行存放的。在行中,默认有两个隐藏字段:
Trx_id:每次对某条记录进行改动时,都会把对应的事务id赋值给trx_id隐藏列。
Roll_pointer:每次对某条记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
提示:
在Oracle逻辑结构中,表空间之下按层次分为段(数据段/索引段/回滚段/临时段)、区、块。
2. 内存存储结构
InnoDB引擎的内存结构如下图左边部分所示,主要分为 Buffer Pool、Change Buffer、Adaptive Hash Index、Log Buffer 四大块。
1) Buffer Pool
缓存高频使用的数据页、索引页、undo页、插入缓存、自适应哈希索引、InnoDB锁信息等。在执行增删改查时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
71-- 查询 Buffer Pool 大小2mysql> show variables like 'innodb_buffer_pool_size';3+-------------------------+-----------+4| Variable_name | Value |5+-------------------------+-----------+6| innodb_buffer_pool_size | 134217728 |7+-------------------------+-----------+
2) Change Buffer
针对非唯一二级索引页设置的更改缓冲区,在执行DML语句时,如果这些数据页没有在 Buffer Pool 中,不会直接操作磁盘,而会将数据变更存在更改缓冲区 Change Buffer中,在未来数据被读取时,再将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘中。 Change Buffer的意义是什么呢?先来看一幅图,这个是二级索引的结构图:

与聚集索引不同,二级索引通常是非唯一的,并且以相对随机的顺序插入二级索引。删除和更新可能会影响索引树中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了ChangeBuffer之后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
3) Adaptive Hash Index
InnoDB引擎不自持Hash索引,但是会根据查询性能监控情况,自动建立自适应哈希索引,无需人工干预。
4) Log Buffer
日志缓冲区,缓存REDO日志和UNDO日志,默认大小为 16MB,会定期刷新到磁盘中。如果需要更新、插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘 I/O。
171-- 查询日志缓存区大小2mysql> show variables like 'innodb_log_buffer_size';3+------------------------+----------+4| Variable_name | Value |5+------------------------+----------+6| innodb_log_buffer_size | 16777216 |7+------------------------+----------+8
9-- 查询日志刷新时机 10-- 0-每秒1次写入并刷新到磁盘 1-事务提交时写入并刷新到磁盘(默认) 2-事务提交后写入,并每秒刷新到磁盘一次11mysql> show variables like 'innodb_flush_log_at_trx_commit';12+--------------------------------+-------+13| Variable_name | Value |14+--------------------------------+-------+15| innodb_flush_log_at_trx_commit | 1 |16+--------------------------------+-------+17
3. 磁盘存储结构
1) System Tablespace
系统表空间,默认文件名为ibdata1,用于存储 Change Buffer ,以及创建在系统表空间中的表和索引数据。
71-- 查询系统表空间2mysql> show variables like 'innodb_data_file_path';3+-----------------------+------------------------+4| Variable_name | Value |5+-----------------------+------------------------+6| innodb_data_file_path | ibdata1:12M:autoextend | -- 系统表空间7+-----------------------+------------------------+
2 ) File-Per-Table Tablespaces
当开启innodb_file_per_table开关时,为每个表都创建单独的表空间,文件名后缀为.ibd,用于存储其数据和索引。
71-- 查询是否打开innodb_file_per_table开关(默认开启)2mysql> show variables like 'innodb_file_per_table';3+-----------------------+-------+4| Variable_name | Value |5+-----------------------+-------+6| innodb_file_per_table | ON |7+-----------------------+-------+
3) General Tablespaces
通用表空间,需要手动创建并在建表时指定其存储的表空间,和Oracle中表空间的用法类似。
61-- 创建表空间2CREATE TABLESPACE ts_name ADD DATAFILE 'file_name' ENGINE = engine_name;3
4-- 创建表空间时指定表5CREATE TABLE xxx ... TABLESPACE ts_name; 6
4) Undo Tablespaces
撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
5) Redo Log
重做日志,在事务提交时写入(顺序写,比较快),当数据库崩溃重启时,用于数据恢复。重做日志存在多个文件,以循环的方式写入:
6) Doublewrite Buffer Files
双写缓冲区,innoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。

7) Temporary Tablespaces
InnoDB 使用会话临时表空间和全局临时表空间,存储用户创建的临时表等数据。
4. 后台线程组
在InnoDB的后台线程中,分为4类,分别是:Master Thread 、IO Thread、Purge Thread、Page Cleaner Thread。
1) Master Thread
核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收。
2) IO Thread
在InnoDB存储引擎中大量使用了AIO来处理IO请求,这样可以极大地提高数据库的性能,而IOThread主要负责这些IO请求的回调。
| 线程类型 | 默认个数 | 职责 |
|---|---|---|
| Read thread | 4 | 负责读操作 |
| Write thread | 4 | 负责写操作 |
| Log thread | 1 | 负责将日志缓冲区刷新到磁盘 |
| Insert buffer thread | 1 | 负责将写缓冲区内容刷新到磁盘 |
我们可以通过以下的这条指令,查看到InnoDB的状态信息,其中就包含IO Thread信息。
1111*************************** 1. row ***************************2 Type: InnoDB3 Name:4Status:5=====================================62023-11-25 17:27:10 0x7f06eaff9700 INNODB MONITOR OUTPUT7=====================================8Per second averages calculated from the last 32 seconds9-----------------10BACKGROUND THREAD11-----------------12srv_master_thread loops: 210 srv_active, 0 srv_shutdown, 13044011 srv_idle13srv_master_thread log flush and writes: 014----------15SEMAPHORES16----------17OS WAIT ARRAY INFO: reservation count 10018OS WAIT ARRAY INFO: signal count 10019RW-shared spins 0, rounds 0, OS waits 020RW-excl spins 5, rounds 151, OS waits 421RW-sx spins 0, rounds 0, OS waits 022Spin rounds per wait: 0.00 RW-shared, 30.20 RW-excl, 0.00 RW-sx23------------24TRANSACTIONS25------------26Trx id counter 42597827Purge done for trx's n:o < 425978 undo n:o < 0 state: running but idle28History list length 2529LIST OF TRANSACTIONS FOR EACH SESSION:30---TRANSACTION 421143599736624, not started310 lock struct(s), heap size 1136, 0 row lock(s)32--------33FILE I/O34--------35I/O thread 0 state: waiting for completed aio requests (insert buffer thread)36I/O thread 1 state: waiting for completed aio requests (log thread)37I/O thread 2 state: waiting for completed aio requests (read thread)38I/O thread 3 state: waiting for completed aio requests (read thread)39I/O thread 4 state: waiting for completed aio requests (read thread)40I/O thread 5 state: waiting for completed aio requests (read thread)41I/O thread 6 state: waiting for completed aio requests (write thread)42I/O thread 7 state: waiting for completed aio requests (write thread)43I/O thread 8 state: waiting for completed aio requests (write thread)44I/O thread 9 state: waiting for completed aio requests (write thread)45Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,46 ibuf aio reads:, log i/o's:, sync i/o's:47Pending flushes (fsync) log: 0; buffer pool: 0481500 OS file reads, 7556 OS file writes, 2613 OS fsyncs490.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s50-------------------------------------51INSERT BUFFER AND ADAPTIVE HASH INDEX52-------------------------------------53Ibuf: size 1, free list len 2057, seg size 2059, 0 merges54merged operations:55 insert 0, delete mark 0, delete 056discarded operations:57 insert 0, delete mark 0, delete 058Hash table size 34679, node heap has 1 buffer(s)59Hash table size 34679, node heap has 2 buffer(s)60Hash table size 34679, node heap has 1 buffer(s)61Hash table size 34679, node heap has 3 buffer(s)62Hash table size 34679, node heap has 4 buffer(s)63Hash table size 34679, node heap has 3 buffer(s)64Hash table size 34679, node heap has 4 buffer(s)65Hash table size 34679, node heap has 10 buffer(s)660.00 hash searches/s, 0.00 non-hash searches/s67---68LOG69---70Log sequence number 8331622751071Log buffer assigned up to 8331622751072Log buffer completed up to 8331622751073Log written up to 8331622751074Log flushed up to 8331622751075Added dirty pages up to 8331622751076Pages flushed up to 8331622751077Last checkpoint at 83316227510782161 log i/o's done, 0.00 log i/o's/second79----------------------80BUFFER POOL AND MEMORY81----------------------82Total large memory allocated 13736345683Dictionary memory allocated 59371084Buffer pool size 819285Free buffers 658186Database pages 158387Old database pages 56488Modified db pages 089Pending reads 090Pending writes: LRU 0, flush list 0, single page 091Pages made young 1, not young 0920.00 youngs/s, 0.00 non-youngs/s93Pages read 1236, created 347, written 4715940.00 reads/s, 0.00 creates/s, 0.00 writes/s95No buffer pool page gets since the last printout96Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s97LRU len: 1583, unzip_LRU len: 098I/O sum[0]:cur[0], unzip sum[0]:cur[0]99--------------100ROW OPERATIONS101--------------1020 queries inside InnoDB, 0 queries in queue1030 read views open inside InnoDB104Process ID=1101, Main thread ID=139668113794816 , state=sleeping105Number of rows inserted 910, updated 1092, deleted 1308, read 5342841060.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s107----------------------------108END OF INNODB MONITOR OUTPUT109============================110
1111 row in set (0.01 sec)
3) Purge Thread
主要用于回收事务已经提交了的undo log,在事务提交之后,undo log可能不用了,就用它来回收。
4) Page Cleaner Thread
协助 Master Thread 刷新脏页到磁盘的线程,它可以减轻 Master Thread 的工作压力,减少阻塞。
5. 扩展:索引存储结构
在InnoDB引擎中,根据索引块和数据块存放的位置,将其分为聚集索引和二级索引。
1) 聚集索引:基于数据块建立的索引,有且只有一个,一般就是主键索引或第一个唯一索引,如果两者都没有,则会自动生成一个rowid作为隐藏的聚集索引。
2) 二级索引:基于索引列建立的索引,可以存在多个,使用该类索引进行查询时可能出现回表查询(即通过索引指向的主键再次查找索引列之外的字段)。
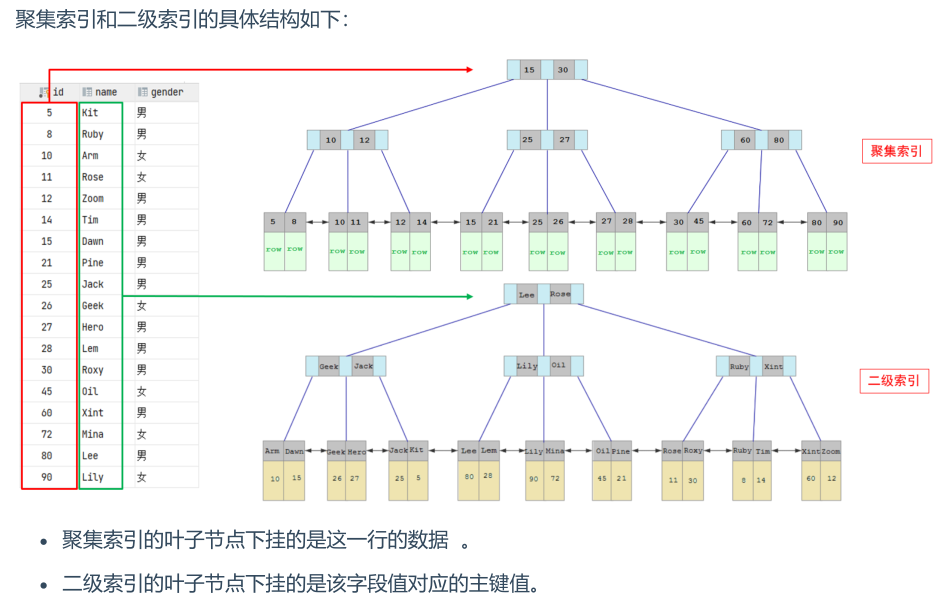
第二节 事务原理
1. 事务的四大特性
事务是一组操作的集合,这些操作要么全部成功,要么全部失败,它具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)四大特性。
从实现原理来看,可以把这四大特性分为两个部分,其中原子性、一致性和持久性由 REDO LOG 和 UNDO LOG 保证,而隔离性是通过数据库的锁和MVCC机制来保证的。
2. 重做日志与回滚日志
重做日志记录事务提交时数据页的修改(物理日志),用来优化事务的持久化性能。如果没有重做日志,那么将采用随机写磁盘的方式,会非常慢,采用重做日志后,先顺序写重做日志,再异步刷新磁盘数据,这种方式被称为(WAL,Write-Ahead Logging,先写日志)。
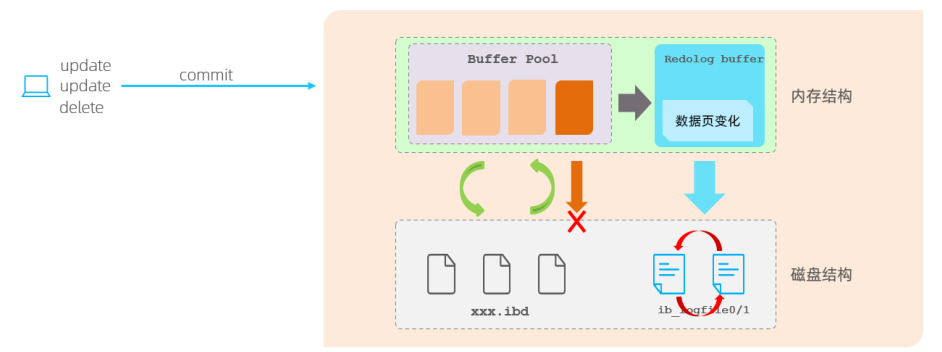
回滚日志记录数据被修改前的信息(逻辑日志,如DELETE语句记INSERT,UPDATE语句记相反的UPDATE等),主要用于回滚(保证事务的原子性) 和MVCC(多版本并发控制) ,存储在表空间中的回滚段。
扩展:关于重做日志和回滚日志的有效期
重做日志在将数据刷新到磁盘后,就可以删除了,因此采用循环写的方式。
回滚日志在事务执行时产生,但在事务提交时并不会立即删除回滚日志,可能还会被用于MVCC。
3. 多版本并发控制(MVCC)
多版本并发控制(MVCC,Multi-Version Concurrency Control)指维护一个数据的多个版本,使得读写操作没有冲突(快照读,读历史版本),Mysql中的具体实现是依赖记录中的隐藏字段、回滚日志、读视图(readView)等。
1) 隐藏字段
| 隐藏字段 | 含义 |
|---|---|
| DB_TRX_ID | 最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID |
| DB_ROLL_PTR | 回滚指针,配合 undo log 使用,指向这条记录的上一个版本 |
| DB_ROW_ID | 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段 |
提示:
隐藏字段可通过
ibd2sdi stu.ibd命令查看。
2) 回滚日志
回滚日志指在 insert、update、delete 的时候产生的便于数据回滚的日志。当insert的时候,产生的undo log日志只在回滚时需要,在事务提交后可被立即删除。而update、delete的时候,产生的undo log日志不仅在回滚时需要,在快照读时也需要,不会立即被删除。
例如:插入1条数据并重复修改2次,将产生如下的回滚日志(注:日志内容仅做示意,实际上回滚日志是逻辑日志)。

3) 快照读与读视图
快照读指读取记录的可见版本,有可能是历史数据,不加锁,是非阻塞读。
在RC隔离级别下,每次普通的select(不加锁)都将生成一个快照读。
在RR隔离级别下,只在开启事务后的第一个select语句生成快照读,后续都复用该读视图。
在Serializable隔离级别下,不会使用快照读,都是当前读。
ReadView(读视图)是 快照读 SQL执行时MVCC提取数据的依据,记录并维护系统当前未提交事务的id。它包含四个核心字段:
| 字段 | 含义 |
|---|---|
| m_ids | 当前活跃的事务ID集合 |
| min_trx_id | 最小活跃事务ID |
| max_trx_id | 预分配事务ID,当前最大事务ID+1(因为事务ID是自增的) |
| creator_trx_id | ReadView创建者的事务ID |
而在readview中规定了版本链数据的访问规则,如下图所示,其中 trx_id 代表当前undolog版本链对应事务ID。
| 条件 | 是否可以访问 | 说明 |
|---|---|---|
| trx_id == creator_trx_id | 可以访问该版本 | 说明数据是当前这个事务更改的 |
| trx_id < min_trx_id | 可以访问该版本 | 说明数据已经提交了 |
| trx_id > max_trx_id | 不可以访问该版本 | 说明该事务是在ReadView生成后才开启 |
| min_trx_id <= trx_id <= max_trx_id | 如果trx_id不在m_ids中,是可以访问该版本的 | 说明数据已经提交 |
扩展:
当前读指读取记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。如:select ... lock in share mode(共享锁),select ...for update、update、insert、delete(排他锁)都是一种当前读。
4. RC实现原理分析
RC隔离级别下,在事务中每一次执行快照读时生成读视图(ReadView)。

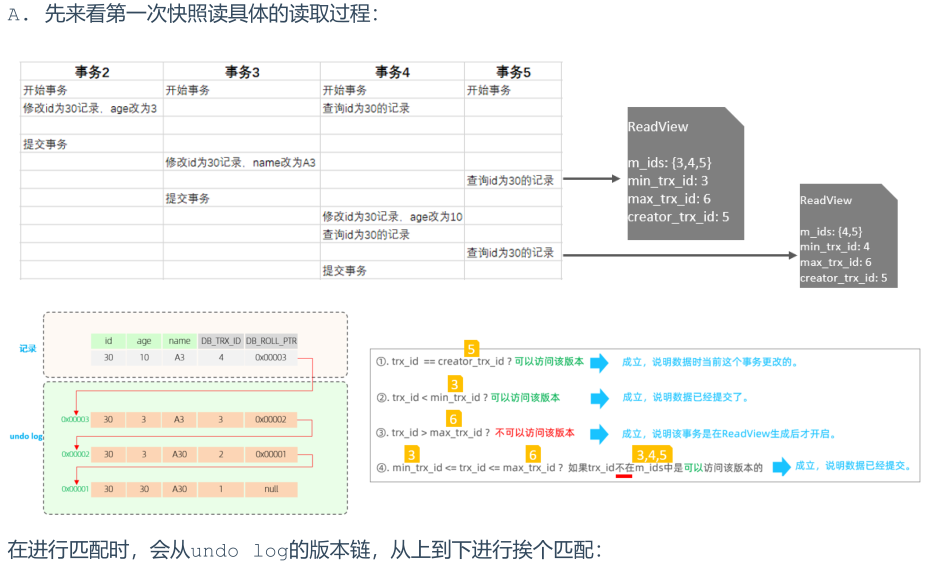



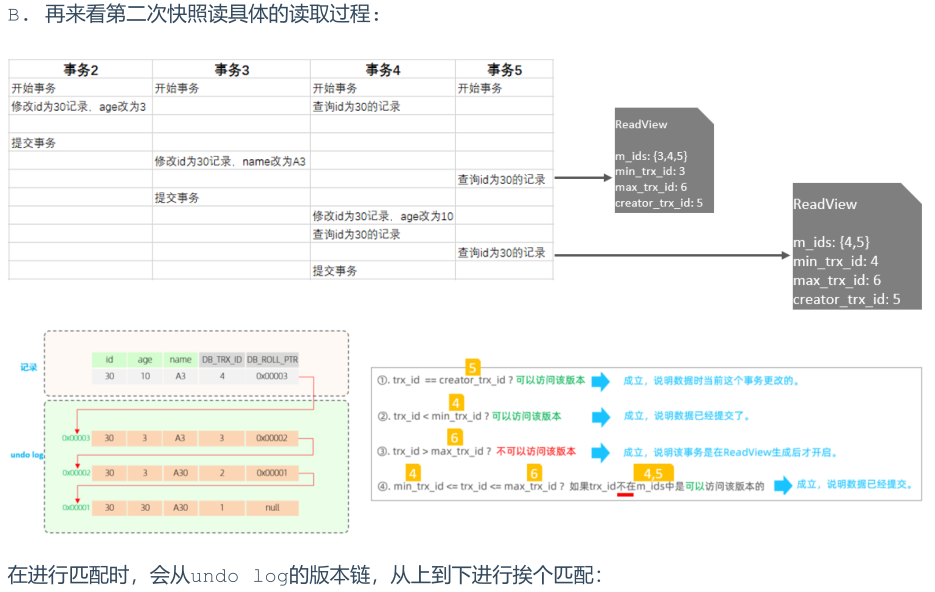

5. RR实现原理分析
RR隔离级别下,仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。 而RR 是可重复读,在一个事务中,执行两次相同的select语句,查询到的结果是一样的。
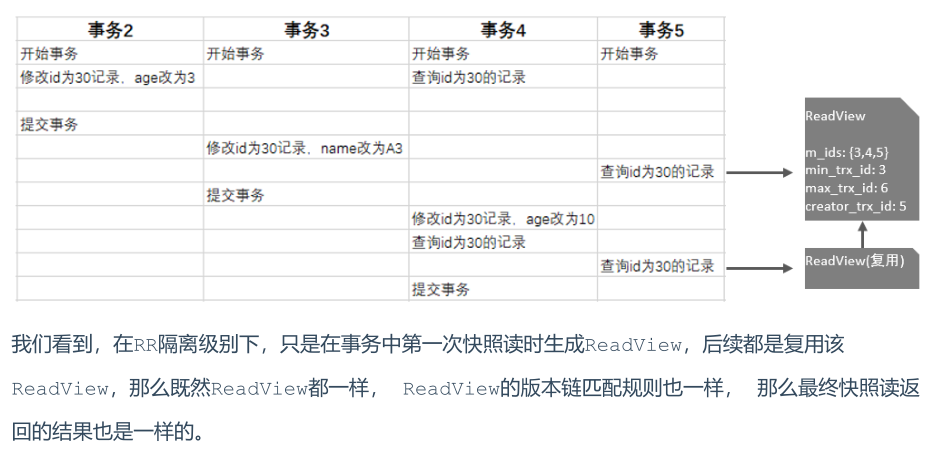

第三节 主从复制
1. 主从复制简介
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。
主从复制的优点主要包含以下三个方面:
主库出现问题,可以快速切换到从库提供服务。
实现读写分离,降低主库的访问压力。
可以在从库中执行备份,以避免备份期间影响主库服务。
2. 主从复制原理
MySQL主从复制的核心就是二进制日志,具体的过程如下:

从上图来看,复制分成三步:
Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
slave重做中继日志中的事件,将改变反映它自己的数据。
3. 主从复制配置
1) 主库配置
修改配置文件 /etc/my.cnf
41server-id=1 # Mysql服务器ID,取值范围1 – 232-1,默认为1,需保证整个集群环境中唯一2read-only=0 # 是否只读 1 代表只读 0 代表读写3#binlog-ignore-db=mysql # 忽略的数据库, 指不需要同步的数据库4#binlog-do-db=db01 # 指定同步的数据库重启MySQL服务器
11systemctl restart mysqld登录mysql,创建远程连接的账号,并授予主从复制权限
51# 创建用户,并设置密码,该用户可在任意主机连接该MySQL服务2CREATE USER 'hyx'@'%' IDENTIFIED WITH mysql_native_password BY 'hyx123456';34#为 'hyx'@'%' 用户分配主从复制权限5GRANT REPLICATION SLAVE ON *.* TO 'hyx'@'%';查看二进制日志坐标。其中 File 和 Position 表示当前二进制日志文件和位置,Binlog_Ignore_DB表示忽略推送的数据库。
61mysql> show master status;2+---------------+----------+--------------+------------------+-------------------+3| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |4+---------------+----------+--------------+------------------+-------------------+5| binlog.000040 | 80470 | | | |6+---------------+----------+--------------+------------------+-------------------+
2) 从库配置
修改配置文件 /etc/my.cnf
21server-id=2 # Mysql服务器ID需与主库不同2read-only=1 # 从库只读重启MySQL服务器
11systemctl restart mysqld登录mysql,设置主库配置
71-- Mysql 8.0.23 之前的版本2CHANGE MASTER TO MASTER_HOST='106.53.120.230', MASTER_USER='hyx', MASTER_PASSWORD='hyx123456',3MASTER_LOG_FILE='binlog.000040', MASTER_LOG_POS=80470;45-- Mysql 8.0.23 及之后的版本6CHANGE REPLICATION SOURCE TO SOURCE_HOST='106.53.120.230', SOURCE_USER='hyx', SOURCE_PASSWORD='hyx123456',7SOURCE_LOG_FILE='binlog.000040', SOURCE_LOG_POS=80470;开启同步操作
21start replica; # Mysql 8.0.22 之后2start slave; # Mysql 8.0.22 之前查看主从同步状态
21show replica status; # Mysql 8.0.22 之后2show slave status; # Mysql 8.0.22 之前
第四节 分库分表
查看相关独立文档!
第五节 读写分离
查看相关独立文档!